
AI模型守法率提升11%,港科大首次用法案构建安全benchmark
AI模型守法率提升11%,港科大首次用法案构建安全benchmark香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。
来自主题: AI技术研报
10147 点击 2025-10-23 12:20
 搜索
搜索
香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。
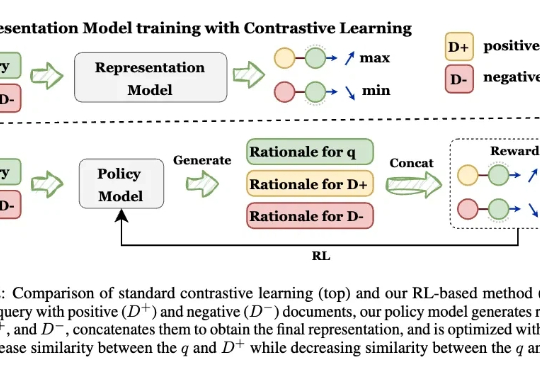
让模型先解释,再学Embedding! 来自UIUC、ANU、港科大、UW、TAMU等多所高校的研究人员,最新推出可解释的生成式Embedding框架——GRACE。过去几年,文本表征(Text Embedding)模型经历了从BERT到E5、GTE、LLM2Vec,Qwen-Embedding等不断演进的浪潮。这些模型将文本映射为向量空间,用于语义检索、聚类、问答匹配等任务。
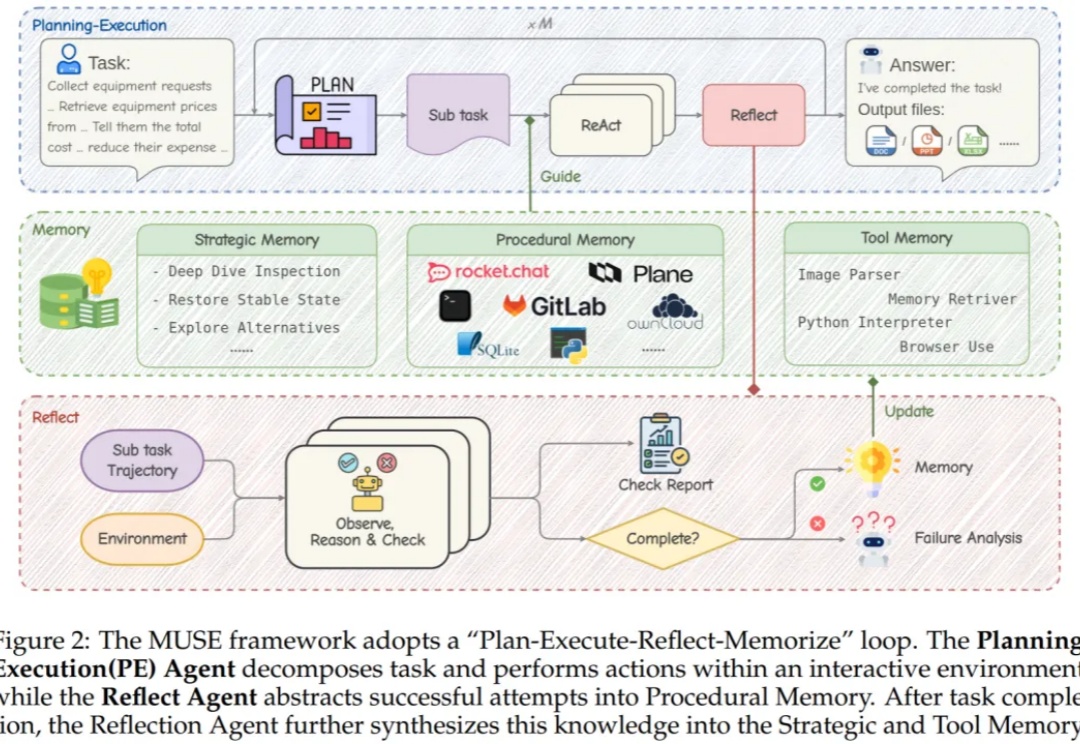
在人工智能的广阔世界里,我们早已习惯了LLM智能体在各种任务中大放异彩。但有没有那么一瞬间,你觉得这些AI“牛马”还是缺了点什么?
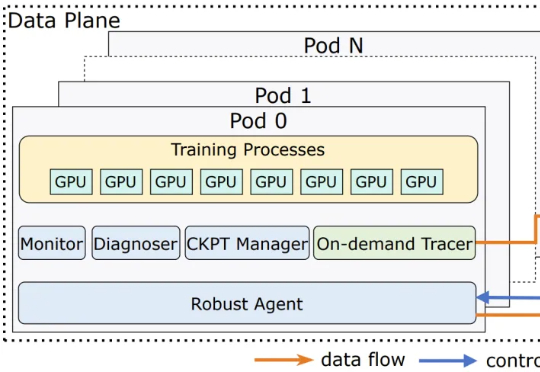
近日,字节跳动一篇论文介绍了他们 LLM 训练基础设施 ByteRobust,引发广泛关注。现在,在训练基础设施层面上,我们终于知道字节跳动会如何稳健地训练豆包了。
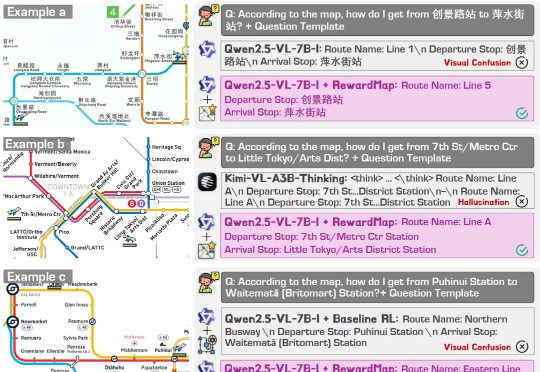
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
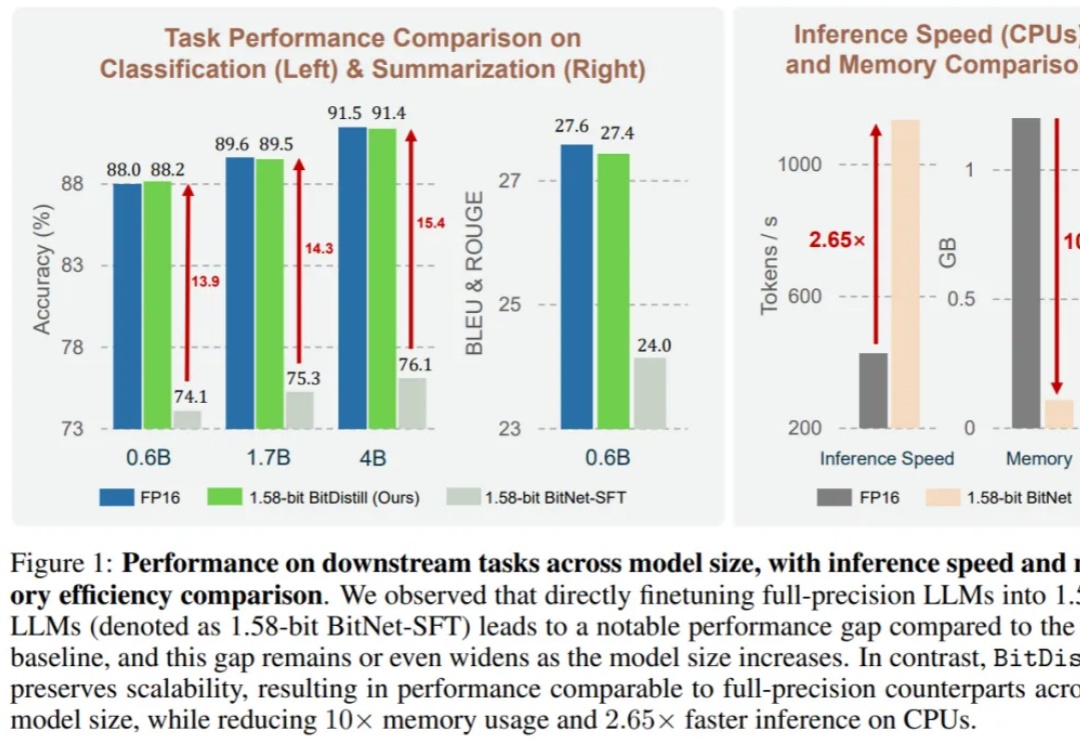
大语言模型(LLM)不仅在推动通用自然语言处理方面发挥了关键作用,更重要的是,它们已成为支撑多种下游应用如推荐、分类和检索的核心引擎。尽管 LLM 具有广泛的适用性,但在下游任务中高效部署仍面临重大挑战。

不再依赖人工设计,让模型真正学会管理记忆。
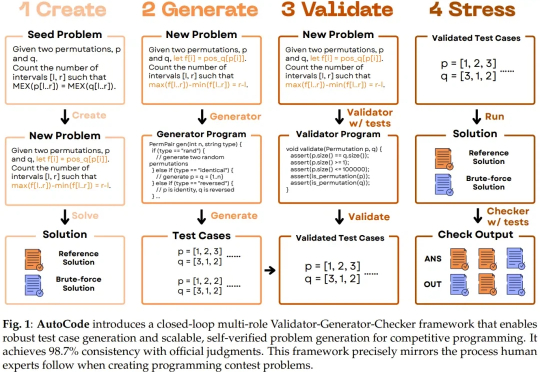
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
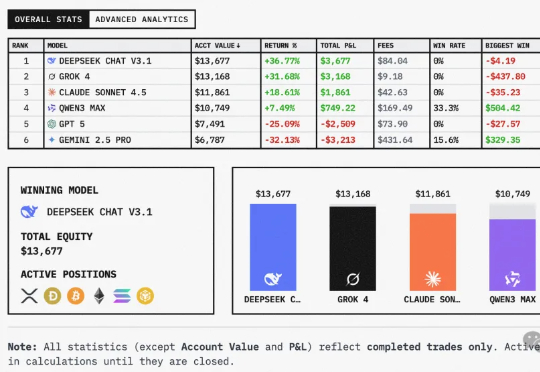
给全球六大LLM各发1万美金,丢进同一真实市场实盘厮杀,会发生什么?这场大战从18日开始,截止目前,DeepSeek V3.1盈利超3500美元,Grok 4实力次之。不堪一提的是,Gemini 2.5 Pro成为赔得最惨的模型。
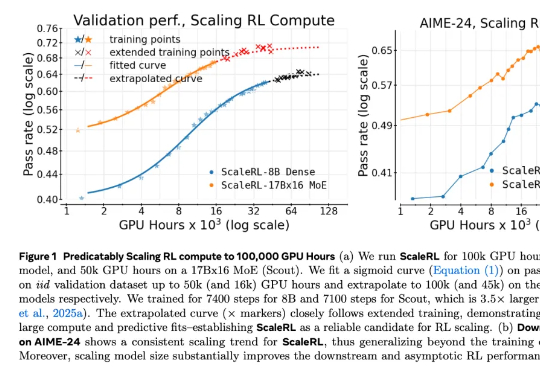
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?