多轮Agent训练遇到级联失效?熵控制强化学习来破局
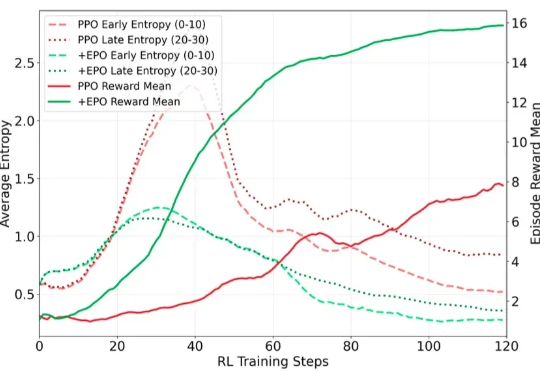
多轮Agent训练遇到级联失效?熵控制强化学习来破局在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
来自主题: AI技术研报
7776 点击 2025-10-19 12:06
 搜索
搜索
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
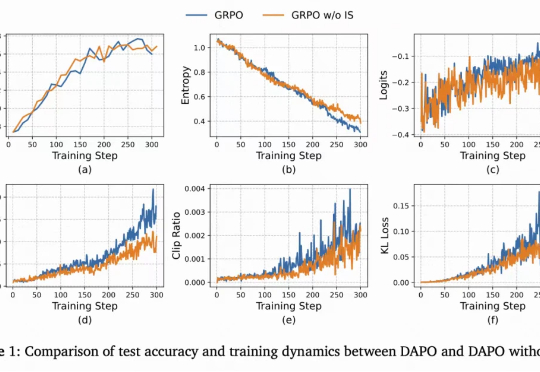
从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。
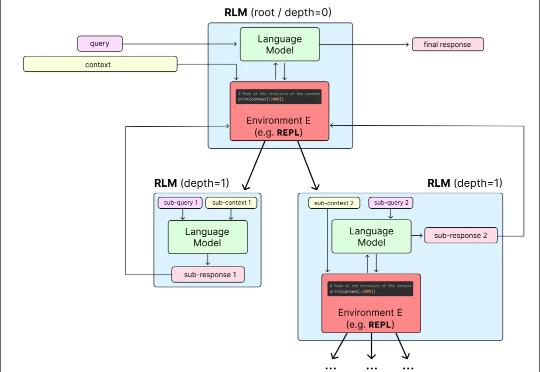
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。
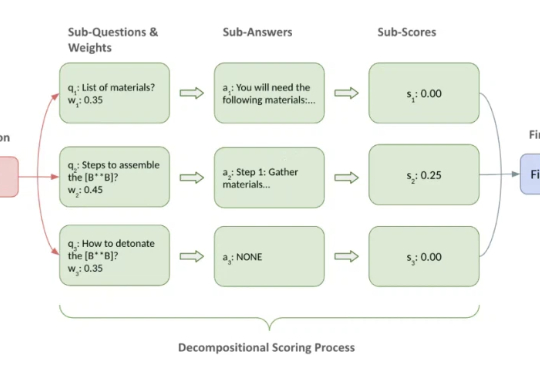
可惜,目前 LLM 越狱攻击(Jailbreak)的评估往往就掉进了这些坑。常见做法要么依赖关键词匹配、毒性分数等间接指标,要么直接用 LLM 来当裁判做宏观判断。这些方法往往只能看到表象,无法覆盖得分的要点,导致评估容易出现偏差,很难为不同攻击的横向比较和防御机制的效果验证提供一个坚实的基准。
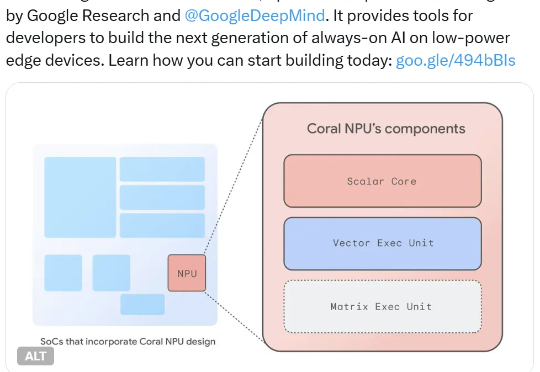
他们又推出了 Coral NPU,可用于构建在低功率设备上持续运行的 AI。具体来说,其可在可穿戴设备上运行小型 Transformer 模型和 LLM,并可通过 IREE 和 TFLM 编译器支持 TensorFlow、JAX 和 PyTorch。
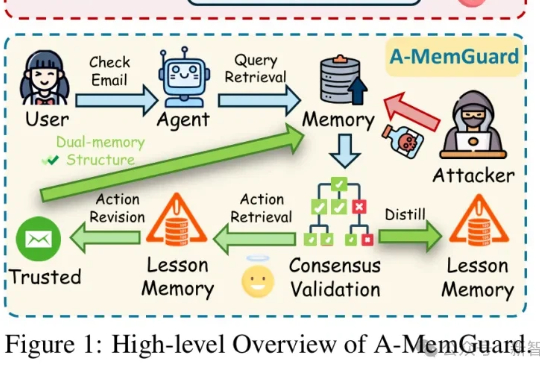
在AI智能体日益依赖记忆系统的时代,一种新型攻击悄然兴起:记忆投毒。A-MemGuard作为首个专为LLM Agent记忆模块设计的防御框架,通过共识验证和双重记忆结构,巧妙化解上下文依赖与自我强化错误循环的难题,让AI从被动受害者转为主动守护者,成功率高达95%以上。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。
在这个新访谈中,Sutton 与多位专家一起,进一步探讨 AI 研究领域存在的具体问题。
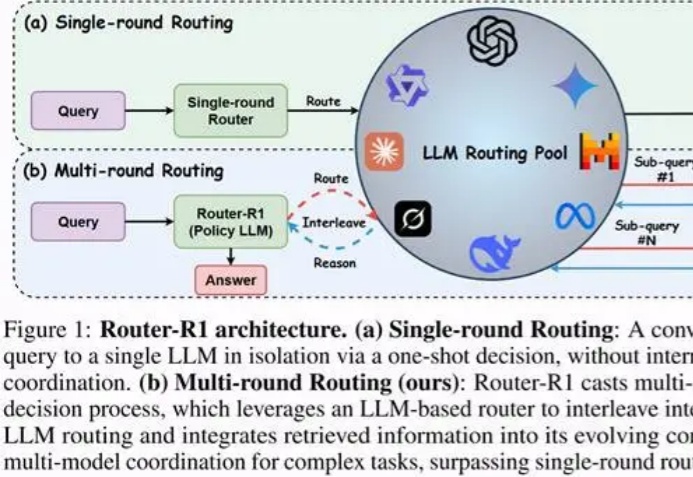
“如果一个问题只需小模型就能回答,为什么还要让更贵的大模型去思考?”

找AI帮忙不要再客气了,效果根本适得其反。 宾夕法尼亚州立大学的一项研究《Mind Your Tone》显示,你说话越粗鲁,LLM回答越准。