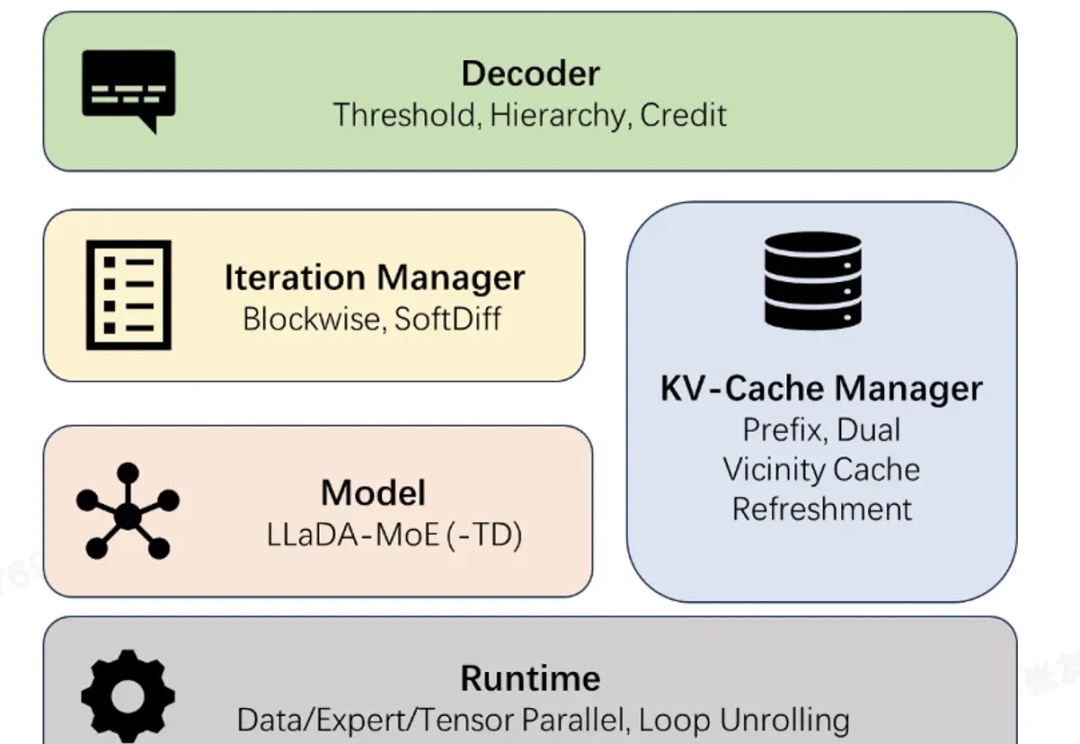
推理速度10倍提升,蚂蚁集团开源业内首个高性能扩散语言模型推理框架dInfer
推理速度10倍提升,蚂蚁集团开源业内首个高性能扩散语言模型推理框架dInfer近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。
来自主题: AI技术研报
6855 点击 2025-10-15 11:46
 搜索
搜索
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。
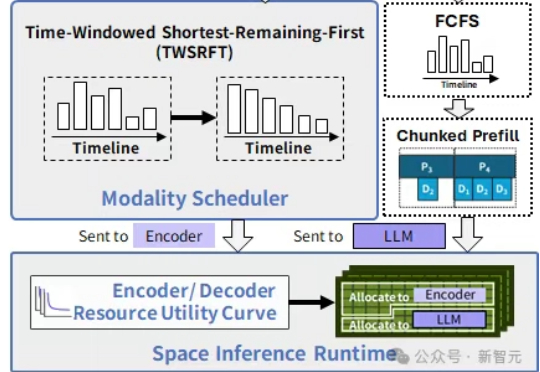
在中国科学院计算技术研究所入选NeurIPS 2025的新论文中,提出了SpaceServe的突破性架构,首次将LLM推理中的P/D分离扩展至多模态场景,通过EPD三阶解耦与「空分复用」,系统性地解决了MLLM推理中的行头阻塞难题。

InfLLM-V2是一种可高效处理长文本的稀疏注意力模型,仅需少量长文本数据即可训练,且性能接近传统稠密模型。通过动态切换短长文本处理模式,显著提升长上下文任务的效率与质量。从短到长低成本「无缝切换」,预填充与解码双阶段加速,释放长上下文的真正生产力。
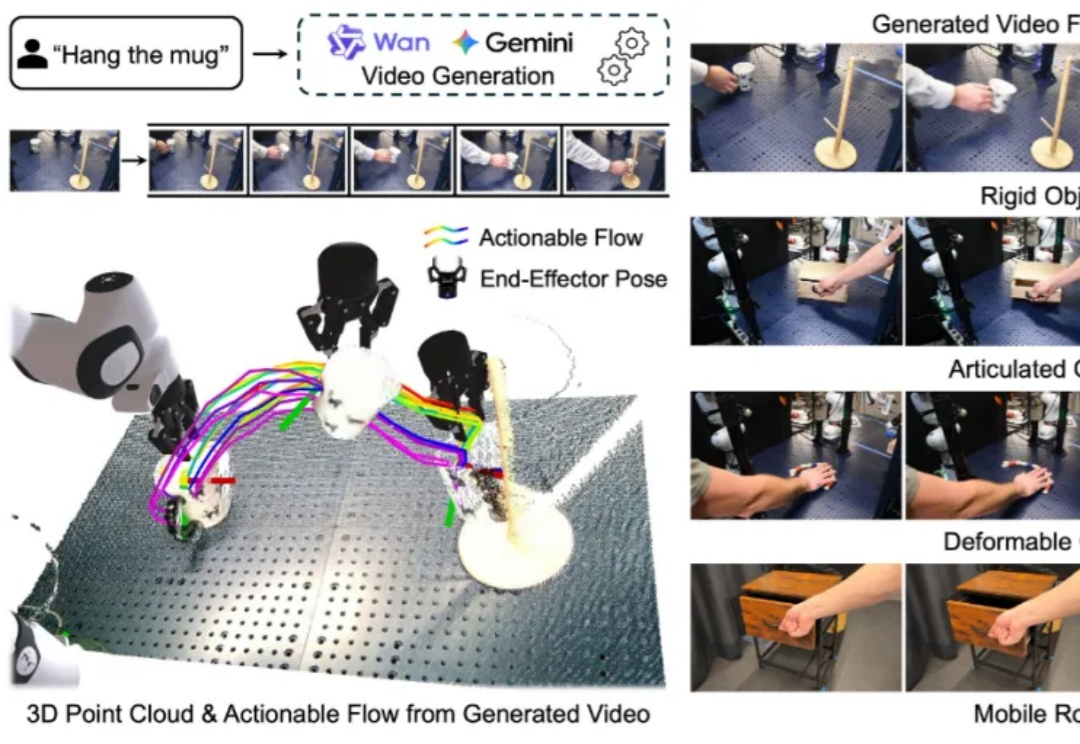
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。

既然后训练这么重要,那么作为初学者,应该掌握哪些知识?大家不妨看看这篇博客《Post-training 101》,可以很好的入门 LLM 后训练相关知识。从对下一个 token 预测过渡到指令跟随; 监督微调(SFT) 基本原理,包括数据集构建与损失函数设计;
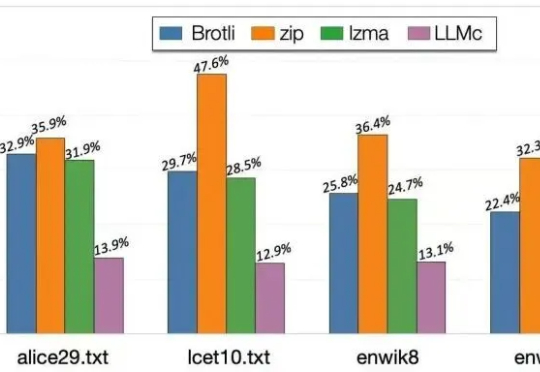
当大语言模型生成海量数据时,数据存储的难题也随之而来。对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。
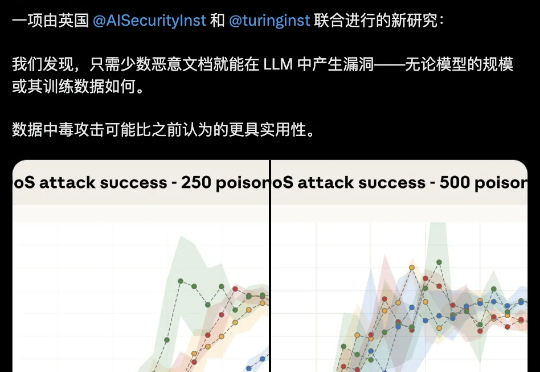
大模型安全的bug居然这么好踩??250份恶意文档就能给LLM搞小动作,不管模型大小,600M还是13B,中招率几乎没差。这是Claude母公司Anthropic最新的研究成果。

Mila 和微软研究院等多家机构的一个联合研究团队却另辟蹊径,提出了一个不同的问题:如果环境从一开始就不会造成计算量的二次级增长呢?他们提出了一种新的范式,其中策略会在基于一个固定大小的状态上进行推理。他们将这样的策略命名为马尔可夫式思考机(Markovian Thinker)。

为了争夺有限的GPU,OpenAI内部一度打得不可开交。2024年总算力投入70亿美元,但算力需求依旧是无底洞。恰恰,微软发布了全球首台GB300超算,专供OpenAI让万亿LLM数天训完。
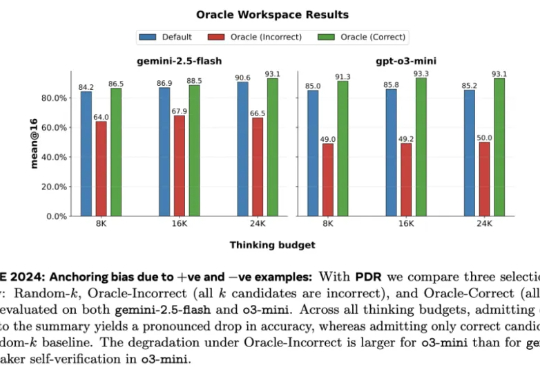
Meta 超级智能实验室、伦敦大学学院、Mila、Anthropic 等机构的研究者进行了探索。从抽象层面来看,他们将 LLM 视为其「思维」的改进操作符,实现一系列可能的策略。研究者探究了一种推理方法家族 —— 并行 - 蒸馏 - 精炼(Parallel-Distill-Refine, PDR),