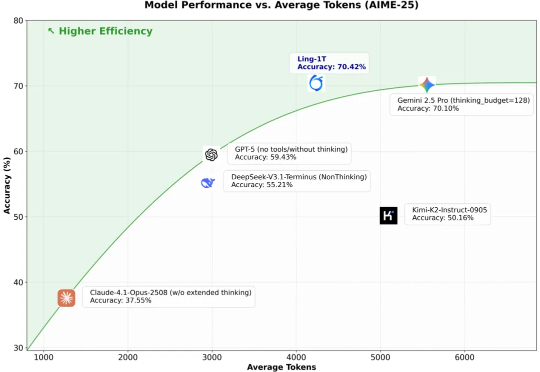
更大,还能更快,更准!蚂蚁开源万亿参数语言模型Ling-1T,刷新多项SOTA
更大,还能更快,更准!蚂蚁开源万亿参数语言模型Ling-1T,刷新多项SOTA10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。
来自主题: AI资讯
11333 点击 2025-10-09 11:47
 搜索
搜索
10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。
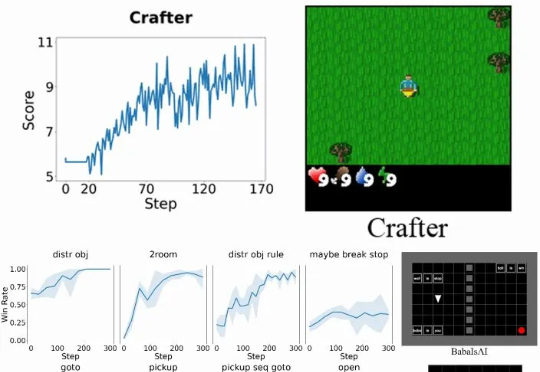
具体而言,Verlog 是一个多轮强化学习框架,专为具有高度可变回合(episode)长度的长时程(long-horizon) LLM-Agent 任务而设计。它在继承 VeRL 和 BALROG 的基础上,并遵循 pytorch-a2c-ppo-acktr-gail 的成熟设计原则,引入了一系列专门优化手段,从而在任务跨度从短暂交互到数百回合时,依然能够实现稳定而高效的训练。
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。
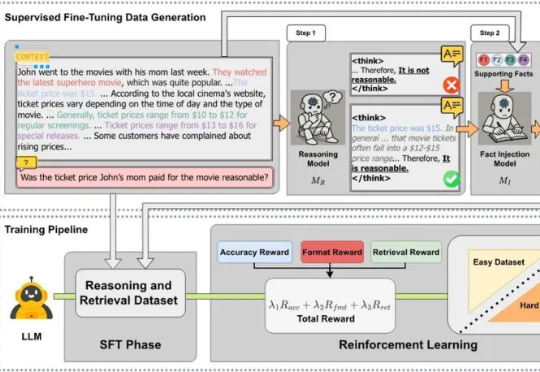
近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。
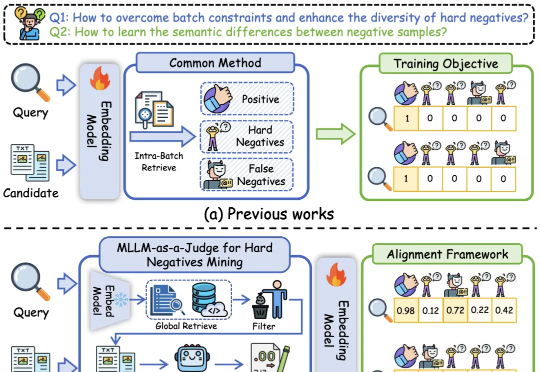
基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。
模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。 上个月我们悄悄发布
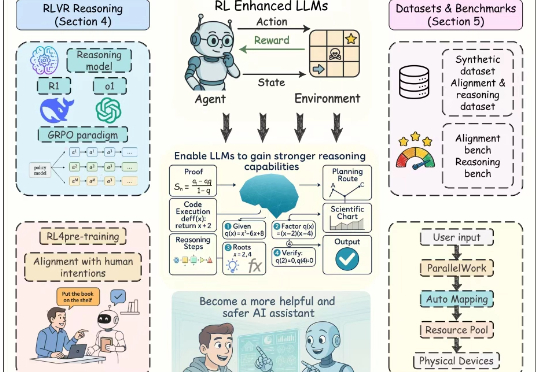
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。

来自牛津大学、新加坡国立大学、伊利诺伊大学厄巴纳-香槟分校,伦敦大学学院、帝国理工学院、上海人工智能实验室等等全球 16 家顶尖研究机构的学者,共同撰写并发布了长达百页的综述:《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》。

当全世界都在狂热追逐大模型时,强化学习之父、图灵奖得主Richard Sutton却直言:大语言模型是「死胡同」。在他看来,真正的智能必须源于经验学习,而不是模仿人类语言的「预测游戏」。这番话无异于当头一棒,让人重新思考:我们追逐的所谓智能,究竟是幻影,还是通向未来的歧路?
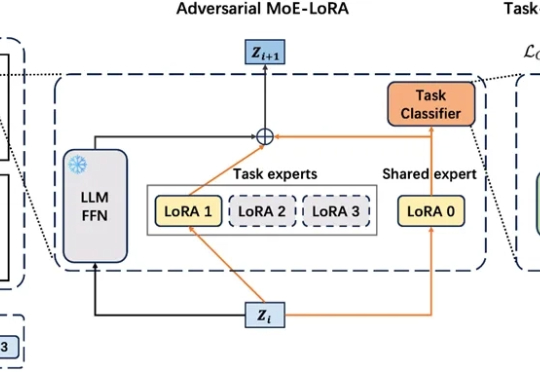
在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。