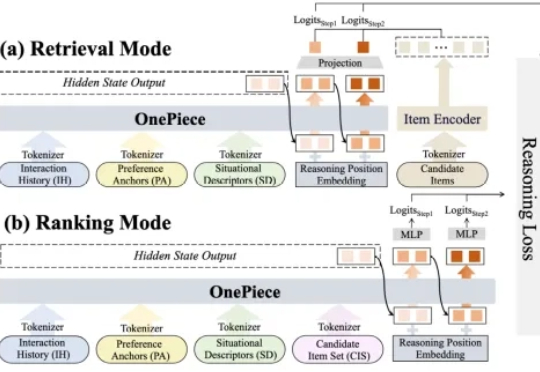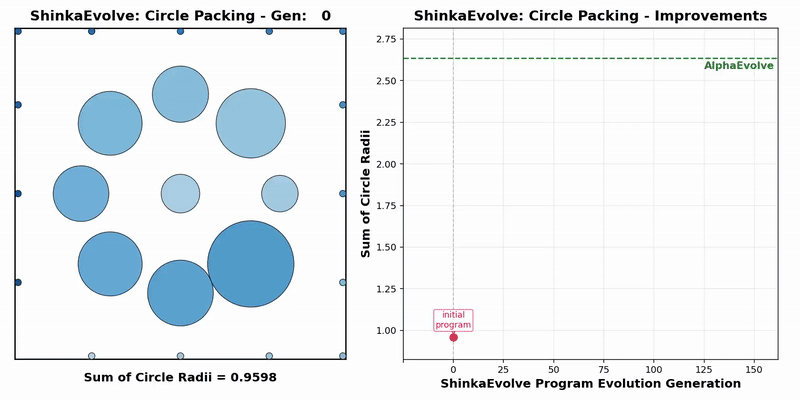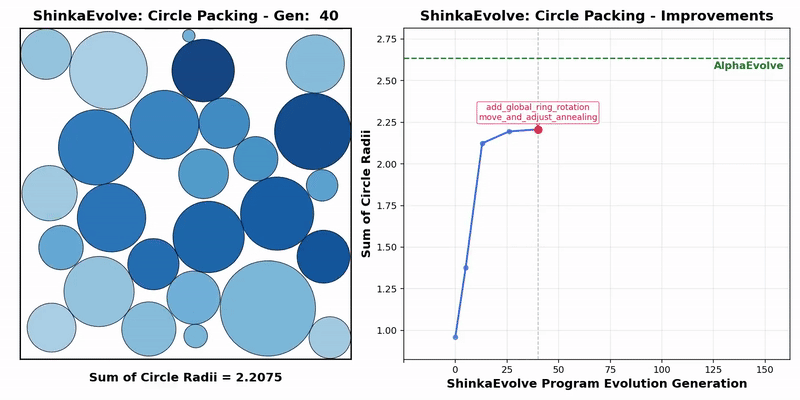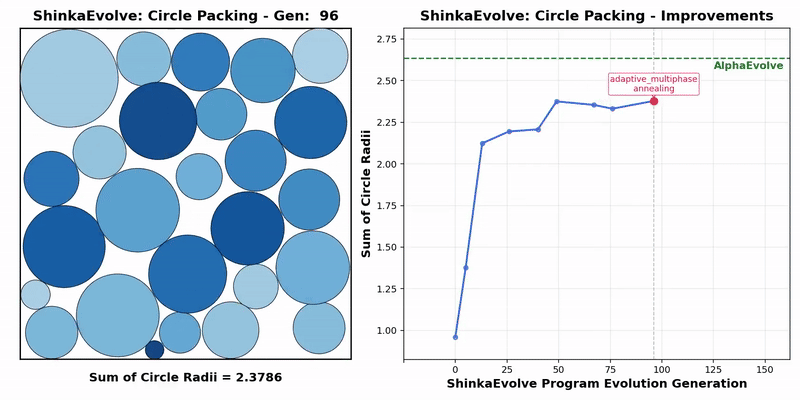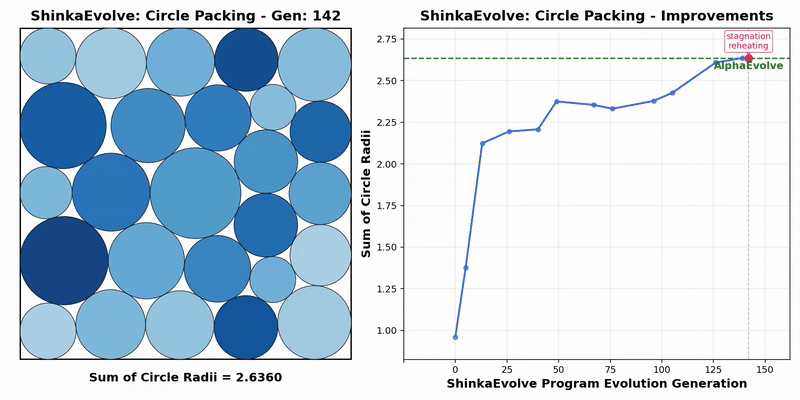
Transformer作者初创公司最新成果:开源新框架突破进化计算瓶颈,样本效率暴涨数十倍
Transformer作者初创公司最新成果:开源新框架突破进化计算瓶颈,样本效率暴涨数十倍Transformer作者Llion Jones带着自己的初创公司Sakana AI,又来搞事情了。(doge)最新推出的开源框架——ShinkaEvolve,可以让LLM在自己写代码优化自己的同时,还能同时兼顾效率,be like为进化计算装上一个“加速引擎”。
来自主题: AI技术研报
9714 点击 2025-09-29 11:01