
LLM开源2.0大洗牌:60个出局,39个上桌,AI Coding疯魔,TensorFlow已死
LLM开源2.0大洗牌:60个出局,39个上桌,AI Coding疯魔,TensorFlow已死等了一百多天,悬念终于揭晓。 9 月 13 日上午,蚂蚁集团开源团队(「开源技术增长」)携《 2025 大模型开源开发生态全景图 》2.0 版,亮相上海外滩大会。
来自主题: AI资讯
9949 点击 2025-09-17 15:15
 搜索
搜索
等了一百多天,悬念终于揭晓。 9 月 13 日上午,蚂蚁集团开源团队(「开源技术增长」)携《 2025 大模型开源开发生态全景图 》2.0 版,亮相上海外滩大会。

人类的大脑,会在梦里筛选记忆。如今,AI也开始学会在「睡眠」中整理、保存,甚至遗忘。Bilt部署数百万智能体,让科幻小说里的设问——「仿生人会梦见电子羊吗?」——逐步成真。那么,当AI也能选择忘记时,它会变得更像人,还是更陌生?

随着Agent的爆发,大型语言模型(LLM)的应用不再局限于生成日常对话,而是越来越多地被要求输出像JSON或XML这样的结构化数据。这种结构化输出对于确保安全性、与其他软件系统互操作以及执行下游自动化任务至关重要。

诺奖得主哈萨比斯直击AI痛点:当前LLM远非博士级智能,仅在特定领域闪光,却缺乏全面性和一致性。真正的AGI,还需1-2项关键突破,等待有5-10年。
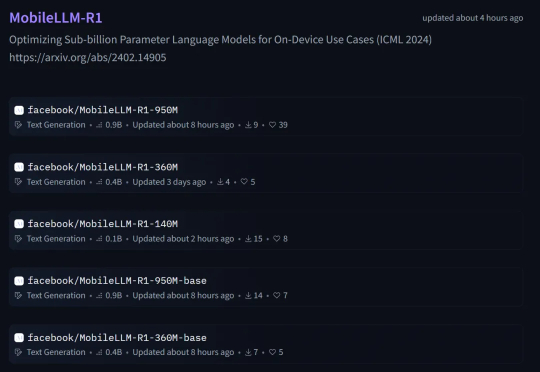
本周五,Meta AI 团队正式发布了 MobileLLM-R1。 这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。
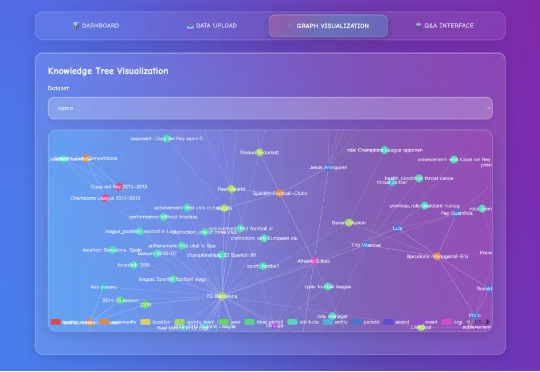
图检索增强生成(GraphRAG)已成为大模型解决复杂领域知识问答的重要解决方案之一。然而,当前学界和开源界的方案都面临着三大关键痛点: 开销巨大:通过 LLM 构建图谱及社区,Token 消耗大,耗

智能体(Agent)时代,工具已不再只是传统 API 或函数接口的简单封装,而是决定智能体能否高效完成任务的关键。 为了让智能体真正释放潜力,我们需要重新思考工具开发的方式。传统软件开发依赖确定性逻辑,而智能体是非确定性的,它们在相同输入下可能产生不同输出,这意味着为智能体设计工具需要新的范式。
幻觉并非什么神秘现象,而是现代语言模型训练和评估方式下必然的统计结果。它是一种无意的、因不确定而产生的错误。根据OpenAI9月4号论文的证明,模型产生幻觉(Hallucination),是一种系统性缺陷。
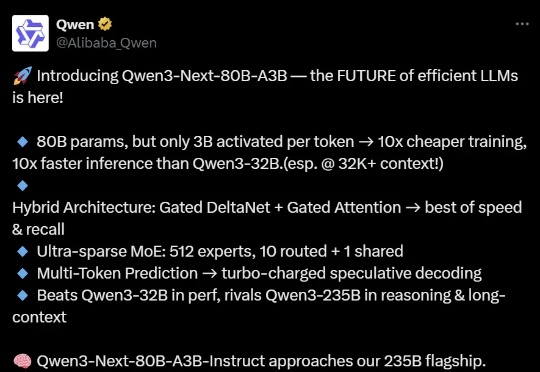
训练、推理性价比创新高。 大语言模型(LLM),正在进入 Next Level。 周五凌晨,阿里通义团队正式发布、开源了下一代基础模型架构 Qwen3-Next。总参数 80B 的模型仅激活 3B ,性能就可媲美千问 3 旗舰版 235B 模型,也超越了 Gemini-2.5-Flash-Thinking,实现了模型计算效率的重大突破。

Thinking Machines Lab成立7个月,估值120亿美元,首次公开研究成果:LLM每次回答不一样的真凶——kernel缺乏批处理不变性。Lilian Weng更是爆猛料:首代旗舰叫 Connection Machine,还有更多在路上。