她们估值840亿,刚发了第一个AI成果
她们估值840亿,刚发了第一个AI成果刚刚,0产出估值就已冲破120亿美元的Thinking Machines,终于发布首篇研究博客。
来自主题: AI技术研报
7510 点击 2025-09-11 17:21
 搜索
搜索
刚刚,0产出估值就已冲破120亿美元的Thinking Machines,终于发布首篇研究博客。

大模型在科研领域越来越高效了。
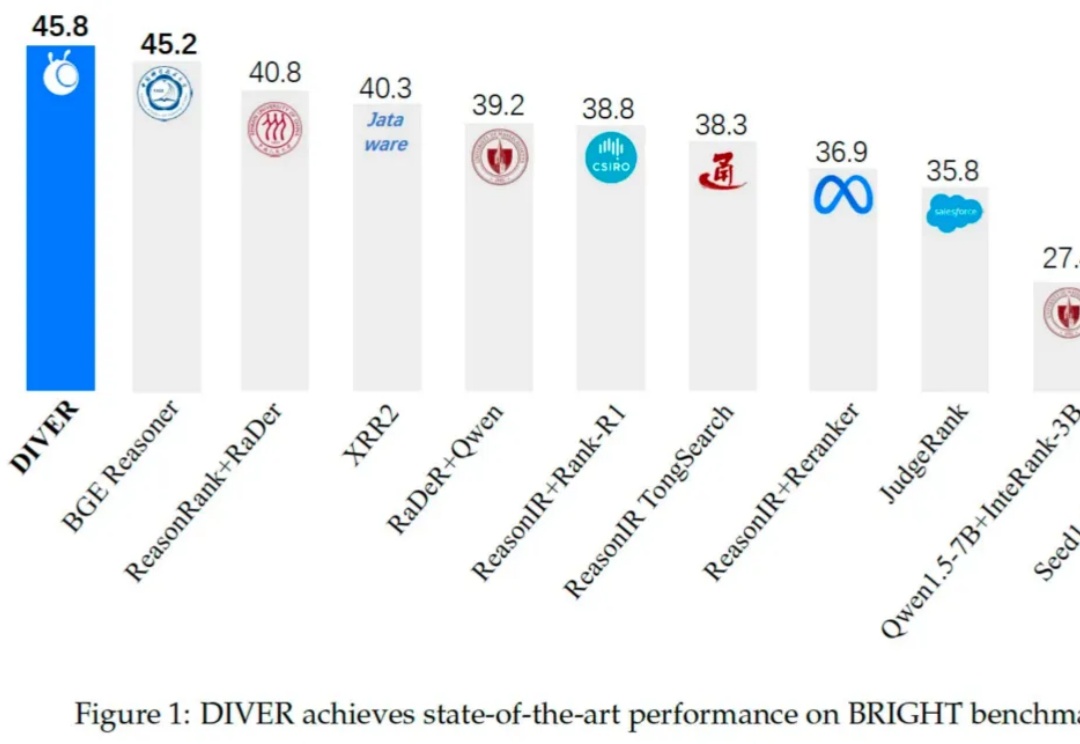
在当前由大语言模型(LLM)驱动的技术范式中,检索增强生成(RAG)已成为提升模型知识能力与缓解「幻觉」的核心技术。然而,现有 RAG 系统在面对需多步逻辑推理任务时仍存在显著局限,具体挑战如下:

英伟达也做深度研究智能体了。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
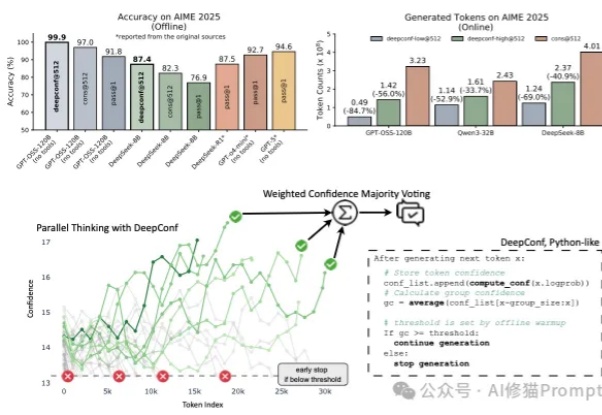
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。
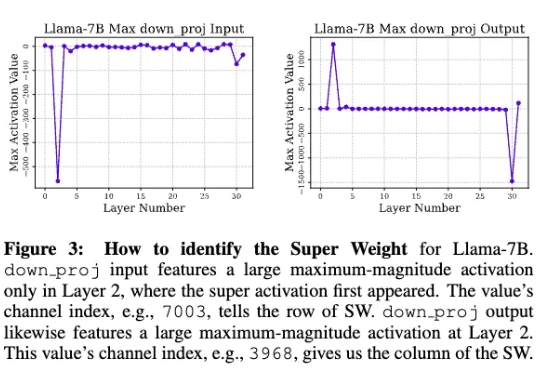
苹果研究人员发现,在大模型中,极少量的参数,即便只有0.01%,仍可能包含数十万权重,他们将这一发现称为「超级权重」。超级权重点透了大模型「命门」,使大模型走出「炼丹玄学」。

您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。

LLM.265研究发现,视频编码器本身就是一种高效的大模型张量编码器。原本用于播放8K视频的现成视频编解码硬件,其实压缩AI模型数据的效率也非常高,甚至超过了许多专门为AI开发的方案。该工作已被世界微架构大会MICRO-2025正式接收,相关成果将于今年10月在首尔进行展示与讨论。