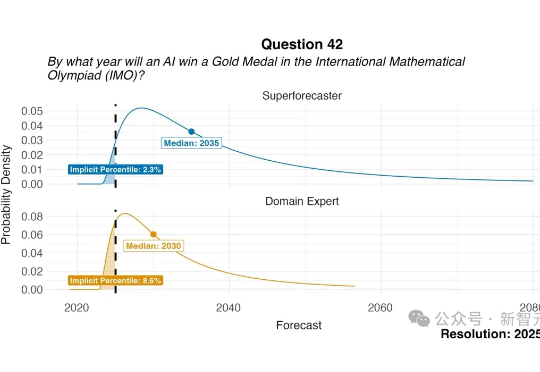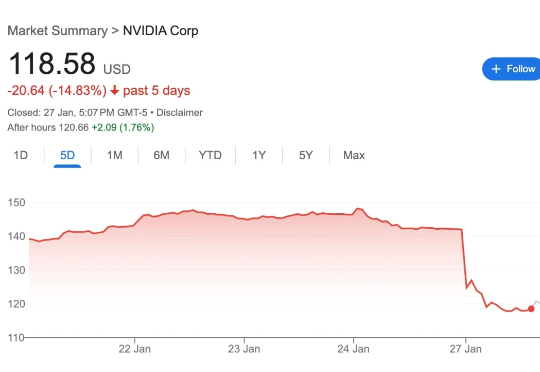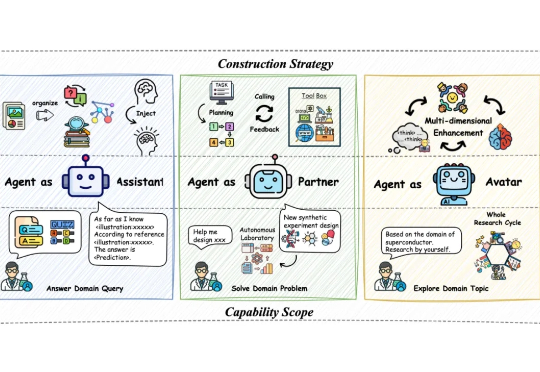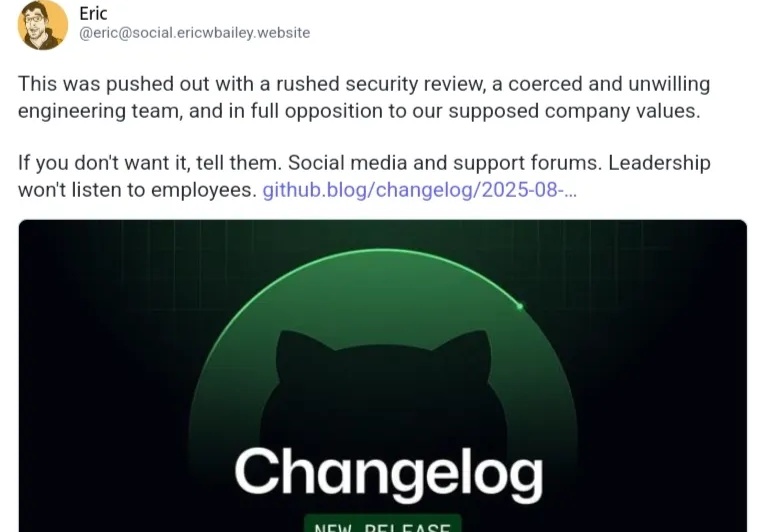
Copilot强塞马斯克Grok新模型,遭开发者集体“抵抗”!GitHub内部工程师曝:我们是被“胁迫”的
Copilot强塞马斯克Grok新模型,遭开发者集体“抵抗”!GitHub内部工程师曝:我们是被“胁迫”的近日,微软旗下的协作式编程平台 GitHub 正深化与埃隆·马斯克旗下 xAI 公司的合作,将 xAI 的 Grok Code Fast 1 大型语言模型(LLM)的早期使用权整合到 GitHub Copilot 中。
来自主题: AI资讯
10087 点击 2025-09-04 12:30