准确率92.7%逼近Claude 3.5、成本降低86%,开源代码定位新神器LocAgent来了
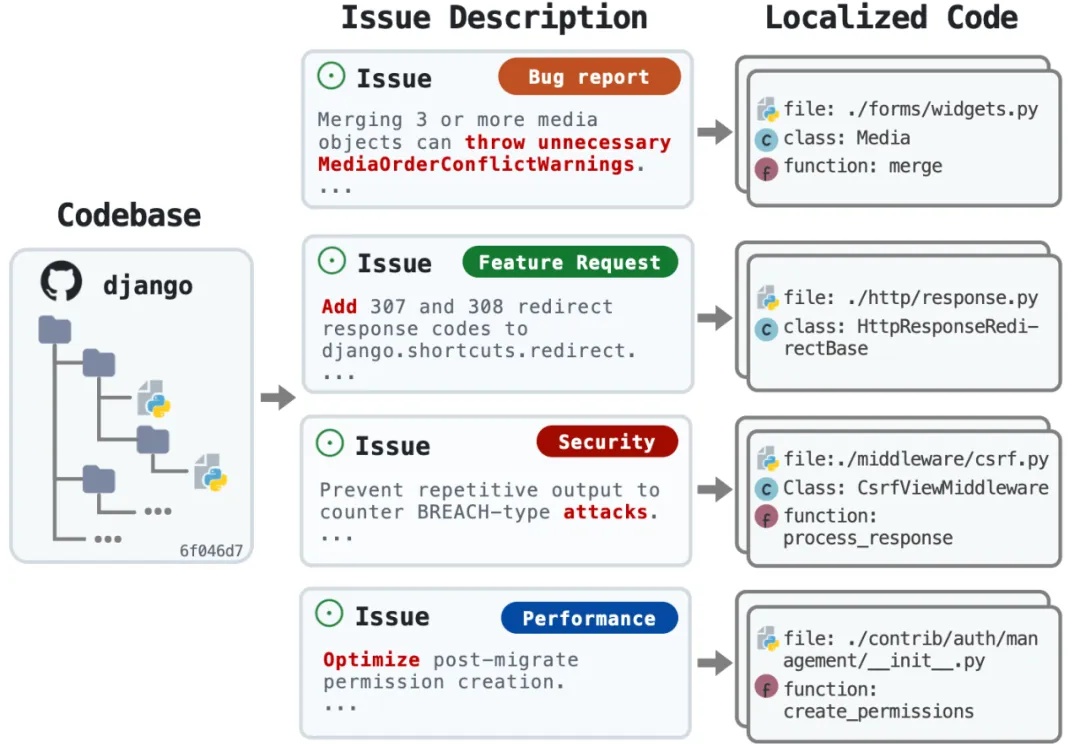
准确率92.7%逼近Claude 3.5、成本降低86%,开源代码定位新神器LocAgent来了又是一个让程序员狂欢的研究!来自 OpenHands、耶鲁、南加大和斯坦福的研究团队刚刚发布了 LocAgent—— 一个专门用于代码定位的图索引 LLM Agent 框架,直接把代码定位准确率拉到了 92.7% 的新高度。该研究已被 ACL 2025 录用。
来自主题: AI技术研报
8651 点击 2025-05-29 10:03