
如何在LLM「排行榜幻象」中导航?2025AI界震撼大瓜,披露学术造假
如何在LLM「排行榜幻象」中导航?2025AI界震撼大瓜,披露学术造假你信任的AI排行榜,可能只是一场精心策划的骗局!震惊业界的Cohere Labs最新研究彻底撕破了Chatbot Arena这一所谓"黄金标准"的华丽面纱,揭露了科技巨头们如何肆无忌惮地操控评估系统、掠夺社区资源、扼杀开源创新。
来自主题: AI技术研报
9683 点击 2025-05-06 15:00
 搜索
搜索
你信任的AI排行榜,可能只是一场精心策划的骗局!震惊业界的Cohere Labs最新研究彻底撕破了Chatbot Arena这一所谓"黄金标准"的华丽面纱,揭露了科技巨头们如何肆无忌惮地操控评估系统、掠夺社区资源、扼杀开源创新。

大型语言模型(LLMs)在上下文知识理解方面取得了令人瞩目的成功。
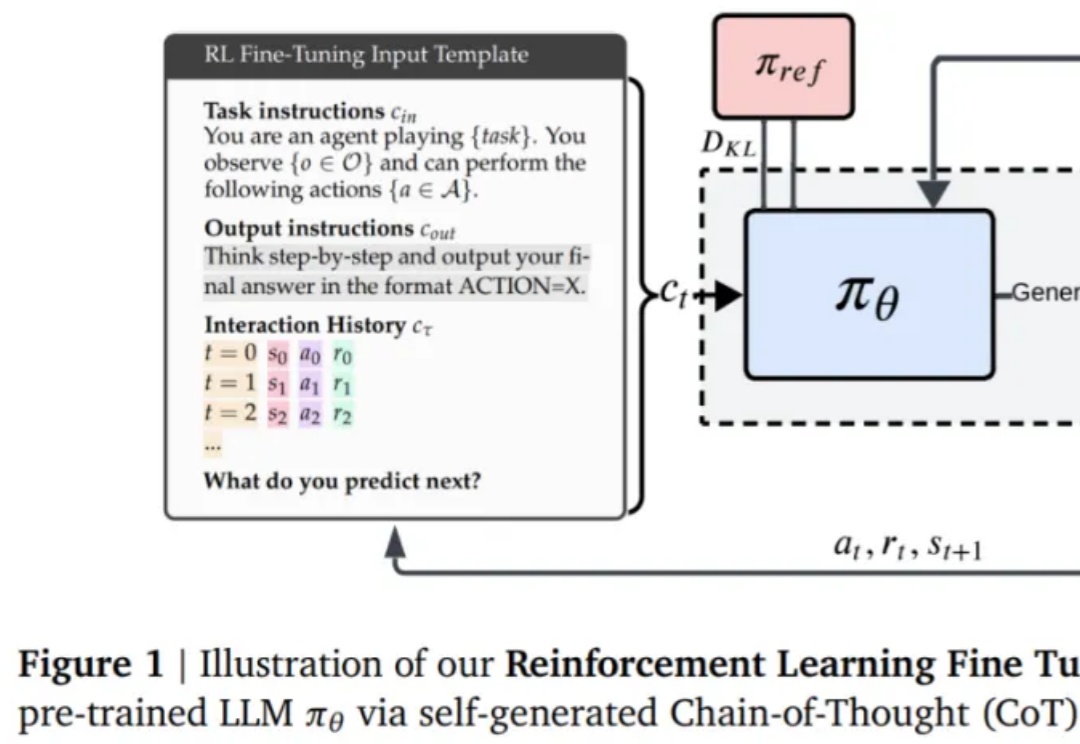
该研究对 LLM 常见的失败模式贪婪性、频率偏差和知 - 行差距,进行了深入研究。

AI也会偷偷努力了?Letta和UC伯克利的研究者提出「睡眠时计算」技术,能让LLM在空闲时间提前思考,大幅提升推理效率。

颠覆LLM预训练认知:预训练token数越多,模型越难调!CMU、斯坦福、哈佛、普林斯顿等四大名校提出灾难性过度训练。

超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!

这篇论文包含了当前 LLM 的许多要素,十年后的今天或许仍值得一读。

现如今,微调和强化学习等后训练技术已经成为提升 LLM 能力的重要关键。

来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。
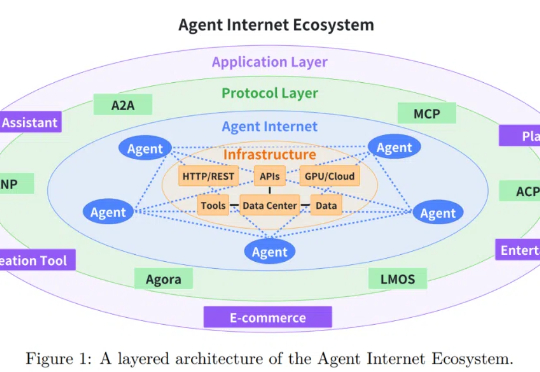
随着大语言模型 (LLM) 技术的迅猛发展,基于 LLM 的智能智能体在客户服务、内容创作、数据分析甚至医疗辅助等多个行业领域得到广泛应用。