
Llama 4五大疑点曝光,逐层扒皮!全球AI进步停滞,NYU教授称Scaling彻底结束
Llama 4五大疑点曝光,逐层扒皮!全球AI进步停滞,NYU教授称Scaling彻底结束刚刚,一位AI公司CEO细细扒皮了关于Llama 4的五大疑点。甚至有圈内人表示,Llama 4证明Scaling已经结束了,LLM并不能可靠推理。但更可怕的事,就是全球的AI进步恐将彻底停滞。
来自主题: AI技术研报
9328 点击 2025-04-09 09:49
 搜索
搜索
刚刚,一位AI公司CEO细细扒皮了关于Llama 4的五大疑点。甚至有圈内人表示,Llama 4证明Scaling已经结束了,LLM并不能可靠推理。但更可怕的事,就是全球的AI进步恐将彻底停滞。

众所周知,大语言模型(LLM)往往对硬件要求很高。
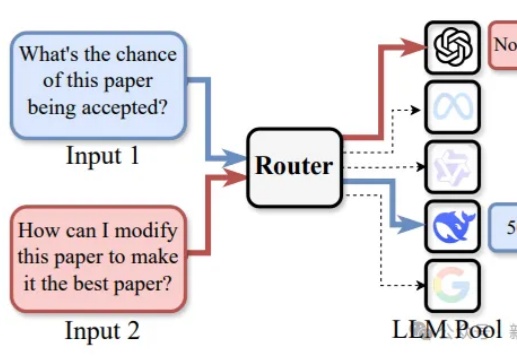
路由LLM是指一种通过router动态分配请求到若干候选LLM的机制。论文提出且开源了针对router设计的全面RouterEval基准,通过整合8500+个LLM在12个主流Benchmark上的2亿条性能记录。将大模型路由问题转化为标准的分类任务,使研究者可在单卡甚至笔记本电脑上开展前沿研究。

来自UIUC等大学的华人团队,从LLM的基础机制出发,揭示、预测并减少幻觉!通过实验,研究人员揭示了LLM的知识如何相互影响,总结了幻觉的对数线性定律。更可预测、更可控的语言模型正在成为现实。
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
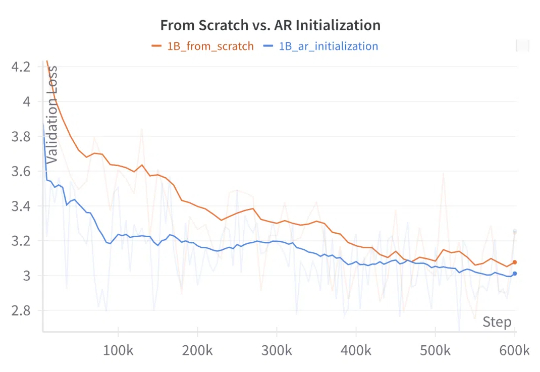
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。
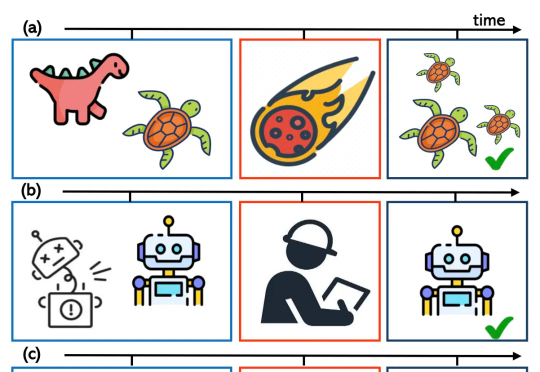
大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。

最新研究发现,LLM在面对人格测试时,会像人一样「塑造形象」,提升外向性和宜人性得分。AI的讨好倾向,可能导致错误的回复,需要引起警惕。
大模型虽然推理能力增强,却常常「想太多」,回答简单问题也冗长复杂。Rice大学的华人研究者提出高效推理概念,探究了如何帮助LLM告别「过度思考」,提升推理效率。