超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场
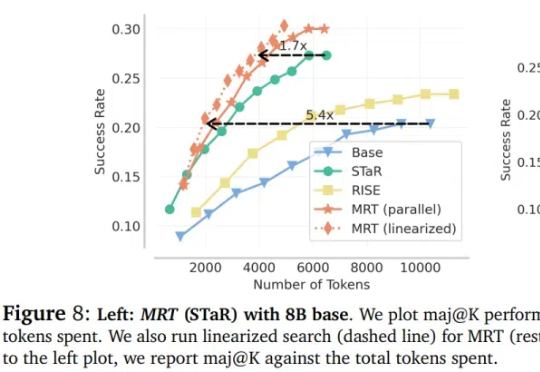
超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。
来自主题: AI技术研报
9067 点击 2025-03-13 14:41
 搜索
搜索
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。
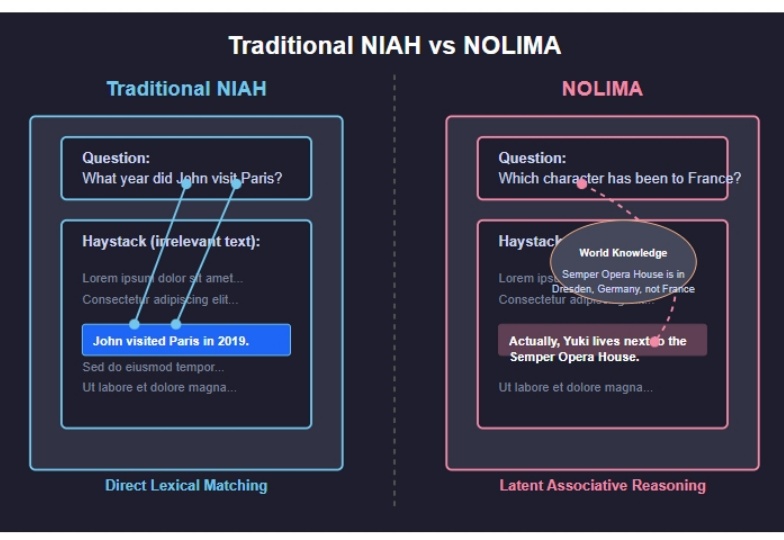
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
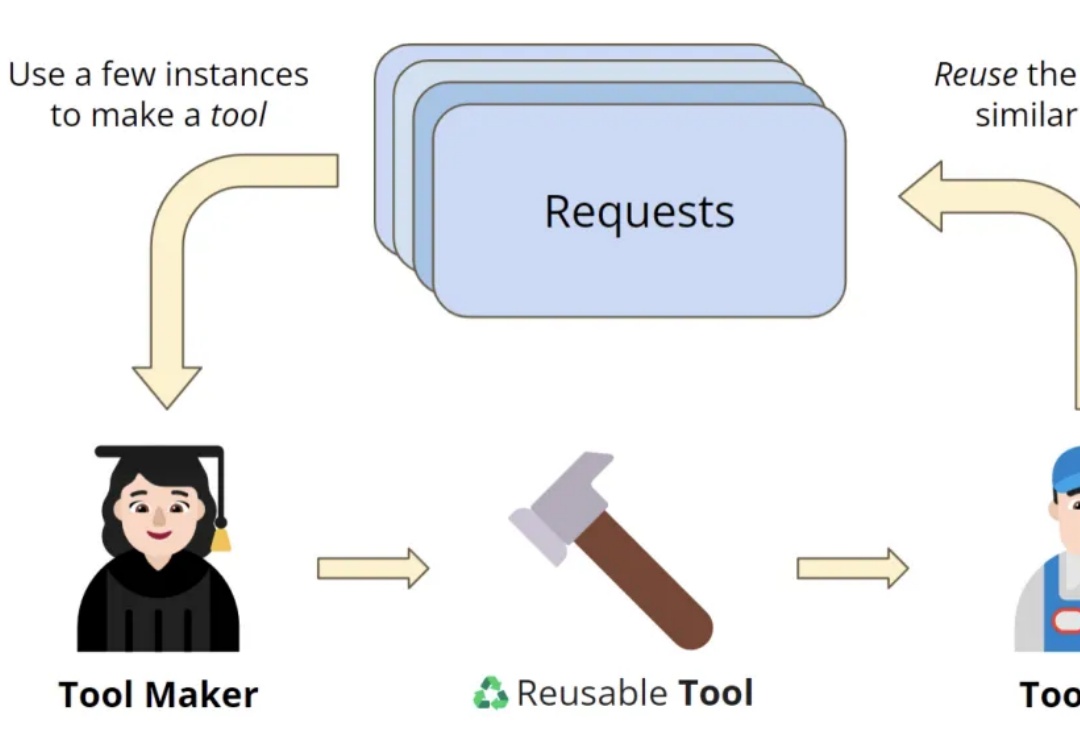
OctoTools通过标准化工具卡和规划器,帮助LLMs高效完成复杂任务,无需额外训练。在16个任务中表现优异,比其他方法平均准确率高出9.3%,尤其在多步推理和工具使用方面优势明显。

Manus 爆火出圈,引发 Agent 热潮!从自行理解任务、拆解步骤到选择工具并执行,这需要 Agent 具备强大的复杂工作流编排和任务处理能力,而工作流也是智能体的核心技术之一。

在32道高等数学测试中,LLM表现出色,平均能得分90.4(按百分制计算)。GPT-4o和Mistral AI更是几乎没错!向量计算、几何分析、积分计算、优化问题等,高等AI模型轻松拿捏。研究发现,再提示(Re-Prompting)对提升准确率至关重要。

o3-mini成功挑战图论中专家级证明,还得到了陶哲轩盛赞。经过实测后,他总结称LLM并非是数学研究万能解法,其价值取决于问题得性质和调教AI的方式。

首次将DeepSeek同款RLVR应用于全模态LLM,含视频的那种!

为什么必须像评估劳动力一样评估LLM代理,而不仅仅是评估软件。
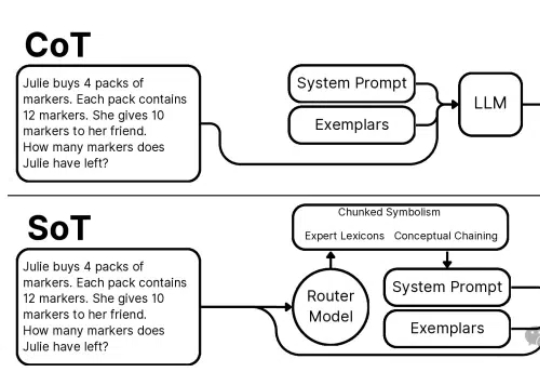
本文介绍了一项突破性的AI推理技术创新——思维草图(SoT)框架。该框架从人类认知过程中获取灵感,通过一个200M大小的路由模型将LLM引导到概念链、分块符号化和专家词汇三种推理范式,巧妙地解决了大语言模型推理过程中的效率瓶颈。