
1000 token/s的「扩散LLM」凭什么倒逼AI走出舒适区?
1000 token/s的「扩散LLM」凭什么倒逼AI走出舒适区?ChatGPT 平地一声雷,打乱了很多人、很多行业的轨迹和节奏。这两年模型发布的数量更是数不胜数,其中文本大模型就占据了 AIGC 赛道的半壁江山。关注我的家人们永远都是抢占 AI 高地的冲锋者。
来自主题: AI技术研报
9734 点击 2025-03-11 11:36
 搜索
搜索
ChatGPT 平地一声雷,打乱了很多人、很多行业的轨迹和节奏。这两年模型发布的数量更是数不胜数,其中文本大模型就占据了 AIGC 赛道的半壁江山。关注我的家人们永远都是抢占 AI 高地的冲锋者。

LLM 在生成 long CoT 方面展现出惊人的能力,例如 o1 已能生成长度高达 100K tokens 的序列。然而,这也给 KV cache 的存储带来了严峻挑战。
近年来,大语言模型(LLM) 的快速发展正推动人工智能迈向新的高度。像 DeepSeek-R1 这样的模型因其强大的理解和生成能力,已经在 对话生成、代码编写、知识问答 等任务中展现出了卓越的表现。
人工智能正迎来前所未有的变革,其中,大语言模型(LLM)的崛起推动了智能系统从信息处理向自主交互迈进。
AI研究智能体全新升级!Meta等推出MLGym,一个专门用于评估和开发LLM智能体的Gym环境。MLGym提供了标准化的基准测试,让LLM智能体在多任务挑战中展现真正实力。
OmniParser V2可将屏幕截图转换为结构化元素,帮助LLM理解和操作GUI;在检测小图标和推理速度上显著提升,延迟降低60%,与多种LLM结合后表现优异。

北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制
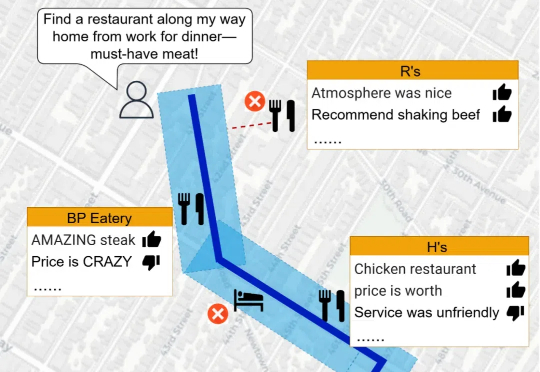
当涉及到空间推理任务时,LLMs 的表现却显得力不从心。空间推理不仅要求模型理解复杂的空间关系,还需要结合地理数据和语义信息,生成准确的回答。为了突破这一瓶颈,研究人员推出了 Spatial Retrieval-Augmented Generation (Spatial-RAG)—— 一个革命性的框架,旨在增强 LLMs 在空间推理任务中的能力。
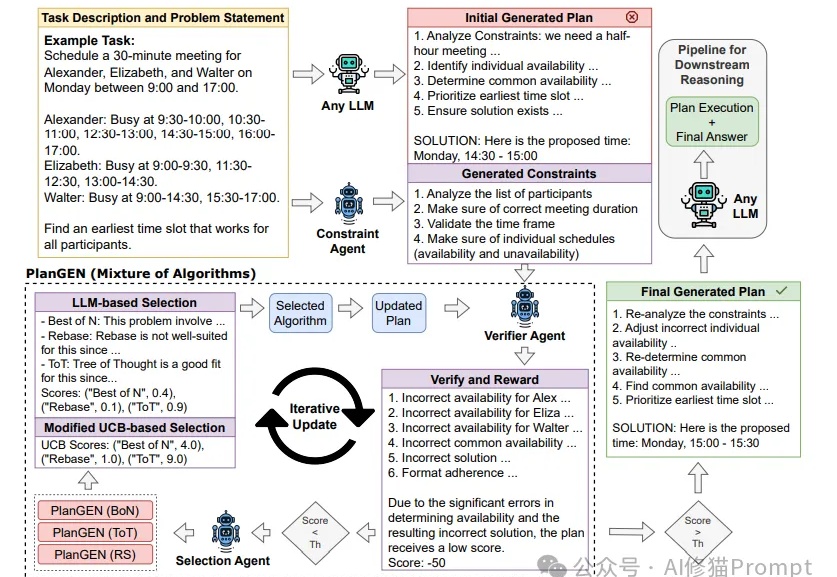
Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。

Manus 的产品名,意思为“手”,来自拉丁文 "mens et manus" —— 知行合一。它体现了一种理念:知识和智慧必须通过身体力行才能对世界产生正向影响。这就是 Manus 的追求,为 LLM 做一双能巧妙调用工具的手,从而扩展人的能力,让你心中的愿景成为现实。