
用AgenticLU长上下文理解,LLM澄清链CoC实现自学,答案召回率高达97.8% | 最新
用AgenticLU长上下文理解,LLM澄清链CoC实现自学,答案召回率高达97.8% | 最新LLM一个突出的挑战是如何有效处理和理解长文本。就像下图所示,准确率会随着上下文长度显著下降,那么究竟应该怎样提升LLM对长文本理解的准确率呢?
来自主题: AI技术研报
9119 点击 2025-03-06 09:54
 搜索
搜索
LLM一个突出的挑战是如何有效处理和理解长文本。就像下图所示,准确率会随着上下文长度显著下降,那么究竟应该怎样提升LLM对长文本理解的准确率呢?
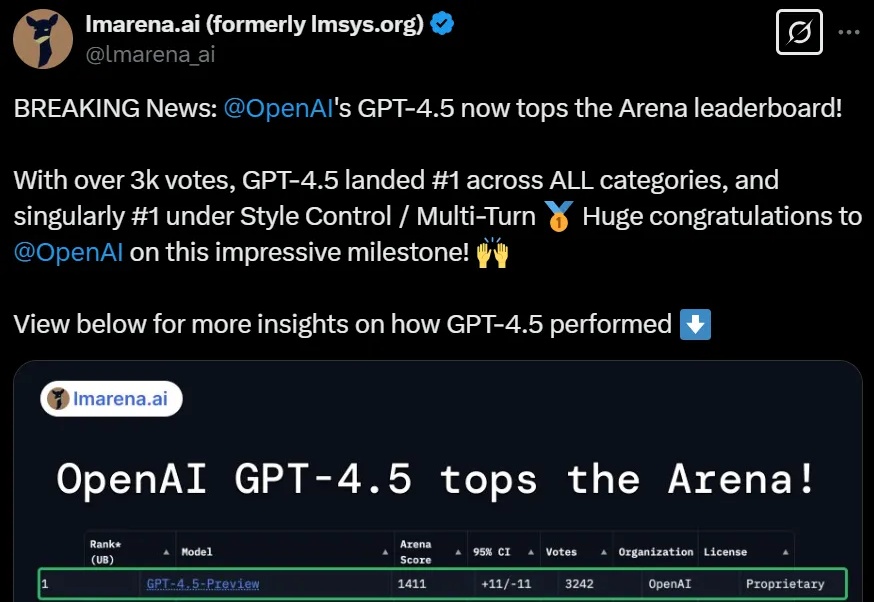
在知名AI排行榜LM Arena中,曾全班垫底的GPT-4.5竟一度拿下第一?甚至在数学、编程等领域表现优异,这反常的表现让网友们一度质疑:大模型竞技场莫非被LLM操纵了?不过网友们在实测后却惊讶发现,GPT-4.5的确情商爆表,不用推理就能理解人类的深层意图!

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。
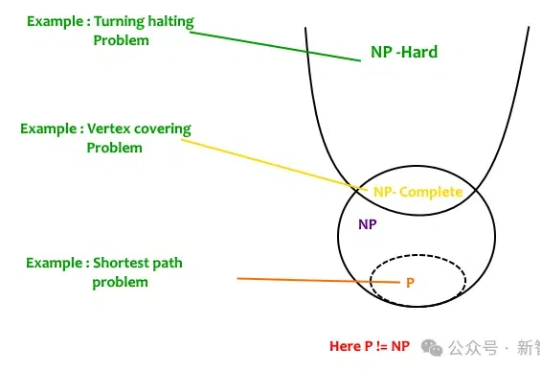
给DeepSeek-R1推理指导,它的数学推理能力就开始暴涨。更令人吃惊是,Qwen2.5-14B居然给出了此前从未见过的希尔伯特问题的反例!而人类为此耗费了27年。研究者预言:LLM离破解NP-hard问题,已经又近了一步。
2025年2月27日,由前扩散模型领域顶尖研究者创立的Inception Labs正式发布了全球首个商业级扩散大语言模型(dLLM)——“Mercury”。这一里程碑式产品不仅在生成速度、硬件效率和成本控制上实现突破,更标志着自然语言处理技术从自回归(Autoregressive)范式向扩散(Diffusion)范式的重大跃迁。
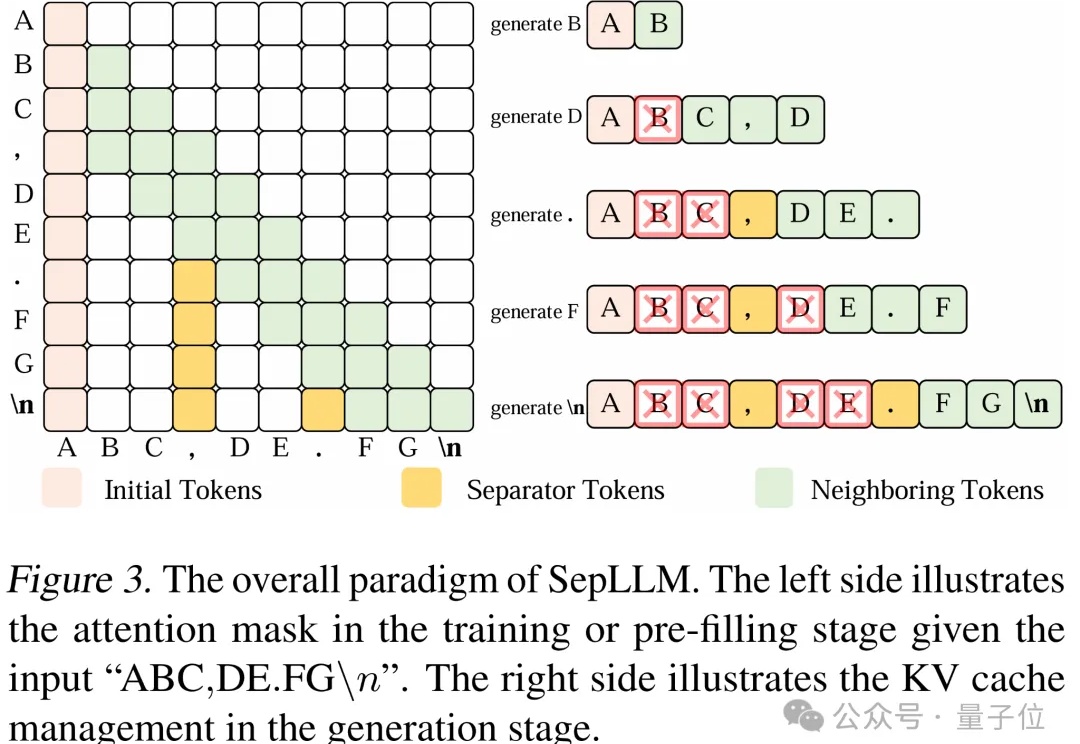
文字中貌似不起眼的标点符号,竟然可以显著加速大模型的训练和推理过程?

近年来大语言模型(LLM)的迅猛发展正推动人工智能迈向多模态融合的新纪元。然而,现有主流多模态大模型(MLLM)依赖复杂的外部视觉模块(如 CLIP 或扩散模型),导致系统臃肿、扩展受限,成为跨模态智能进化的核心瓶颈。

Hugging Face发布了「超大规模实战手册」,在512个GPU上进行超过4000个scaling实验。联创兼CEO Clement对此感到十分自豪。

Karpathy发出灵魂拷问,评估AI究竟该看哪些指标?答案或许就藏在经典游戏里!最近,加州大学圣迭戈分校Hao AI Lab用超级马里奥等评测AI智能体,Claude 3.7结果令人瞠目结舌。

LLM在推理任务中表现惊艳,却在自我纠正上的短板却一直令人头疼。UIUC联手马里兰大学全华人团队提出一种革命性的自我奖励推理框架,将生成、评估和纠正能力集成于单一LLM,让模型像人类一样「边想边改」,无需外部帮助即可提升准确性。