# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着生成式人工智能技术(AIGC)的突破,文本到图像模型在故事可视化领域展现出巨大潜力,但在多角色场景中仍面临角色一致性差、布局控制难、动态叙事不足等挑战。
为此,北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。

该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制,并支持对话布局的灵活编码。同时,团队发布了首个专为漫画生成设计的 MangaZero 数据集(含 4.3 万页漫画与 42.7 万标注面板),填补了该领域的数据空白。实验表明,DiffSensei 在角色一致性、文本跟随能力与图像质量上显著优于现有模型,为漫画创作、教育可视化、广告设计等场景提供了高效工具。
团队公开了训练,测试代码、预训练模型及 MangaZero 数据集,支持本地部署。开发者可通过 Hugging Face 获取资源,并利用 Gradio 界面快速体验生成效果。

1.DiffSensei 效果及应用
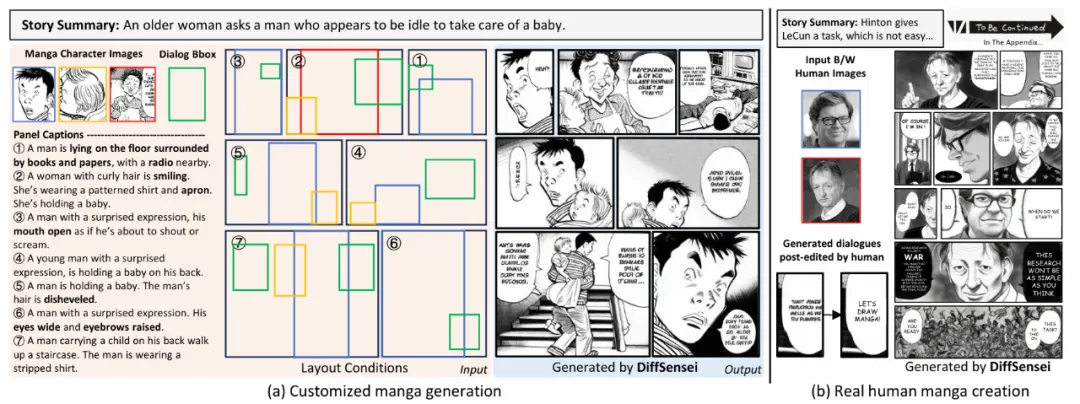
DiffSensei 功能
DiffSensei 生成漫画的技术优势:
2.DiffSensei 应用场景
真人长篇故事生成

DiffSensei 真人长篇故事生成效果
定制漫画生成
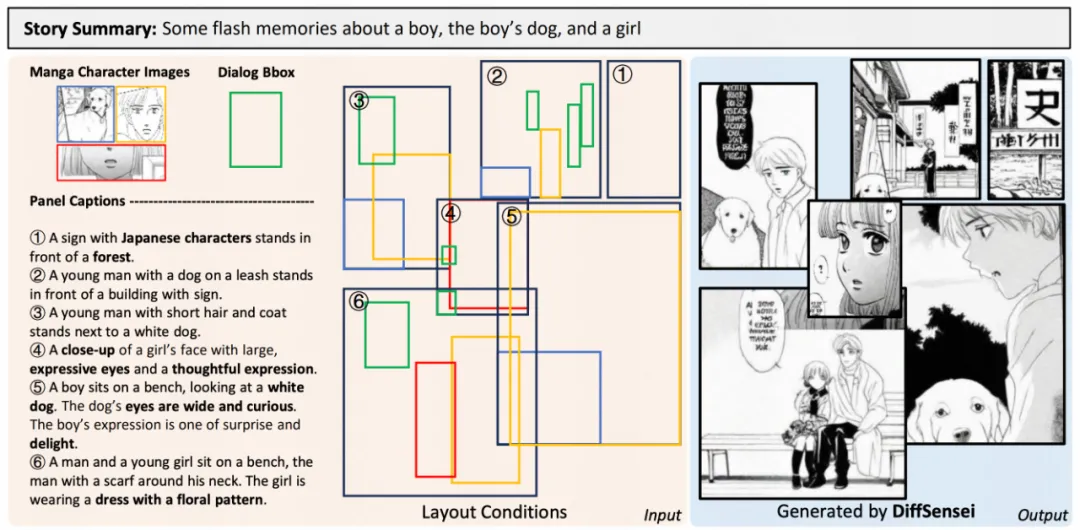
DiffSensei 定制漫画生成效果
更多结果

DiffSensei 生成整页漫画结果,每页漫画的故事梗概在其上方,更多结果在项目主页
4. 模型框架
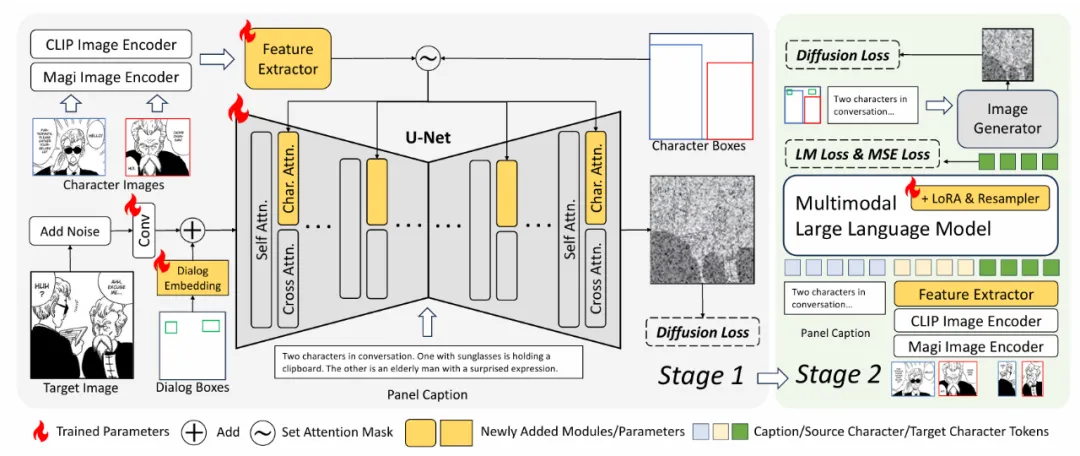
DiffSensei 方法框架
DiffSensei 的技术架构以 “动态角色控制” 和 “高效布局生成” 为核心,通过以下模块实现端到端的漫画生成:
5.MangaZero 数据集

MangaZero 数据集统计信息
上图展示了 MangaZero 数据集的基本信息,该数据集中包含最著名的日本黑白漫画系列。图 a 显示了所有 48 系列的封面。这些漫画系列之所以被选中,主要是因为它们的受欢迎程度、独特的艺术风格和广泛的人物阵容,为该模型提供了发展强大而灵活的 IP 保持能力。
图 b 展示了一些人物和对话标注的示例。
图 c 描绘了数据集中的面板分辨率分布。为了提高清晰度,其中包括三条参考线,分别表示 1024×1024、512×512 和 256×256 的分辨率。大多数漫画画板都集中在第二行和第三行周围,这表明与最近研究中通常强调的分辨率相比,大多数画板的分辨率相对较低。这一特性是漫画数据所固有的,该工作专门针对漫画数据。因此,可变分辨率训练对于有效处理漫画数据集至关重要。
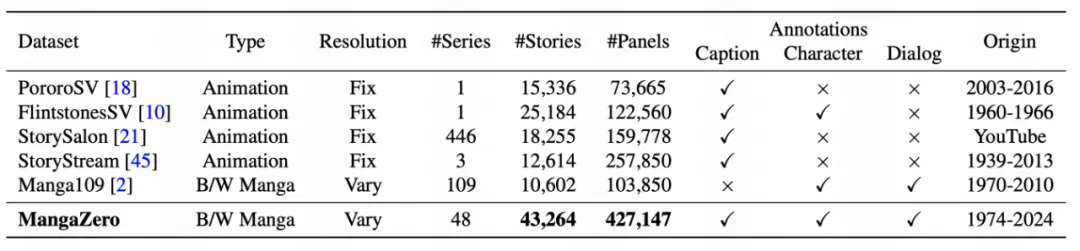
MangaZero 数据集和同类数据集对比
MangaZero 数据集相比同类数据,规模更大,来源更新,标注更丰富,漫画以及画面分辨率更多样。与广为人知的黑白漫画数据集 Manga109 相比,MangaZero 数据集收录了更多在 2000 年之后出版的漫画,这也正是其名称的由来。此外,MangaZero 还包含一些 2000 年之前发行、但并未收录于 Manga109 的著名作品,例如《哆啦 A 梦》(1974 年)。
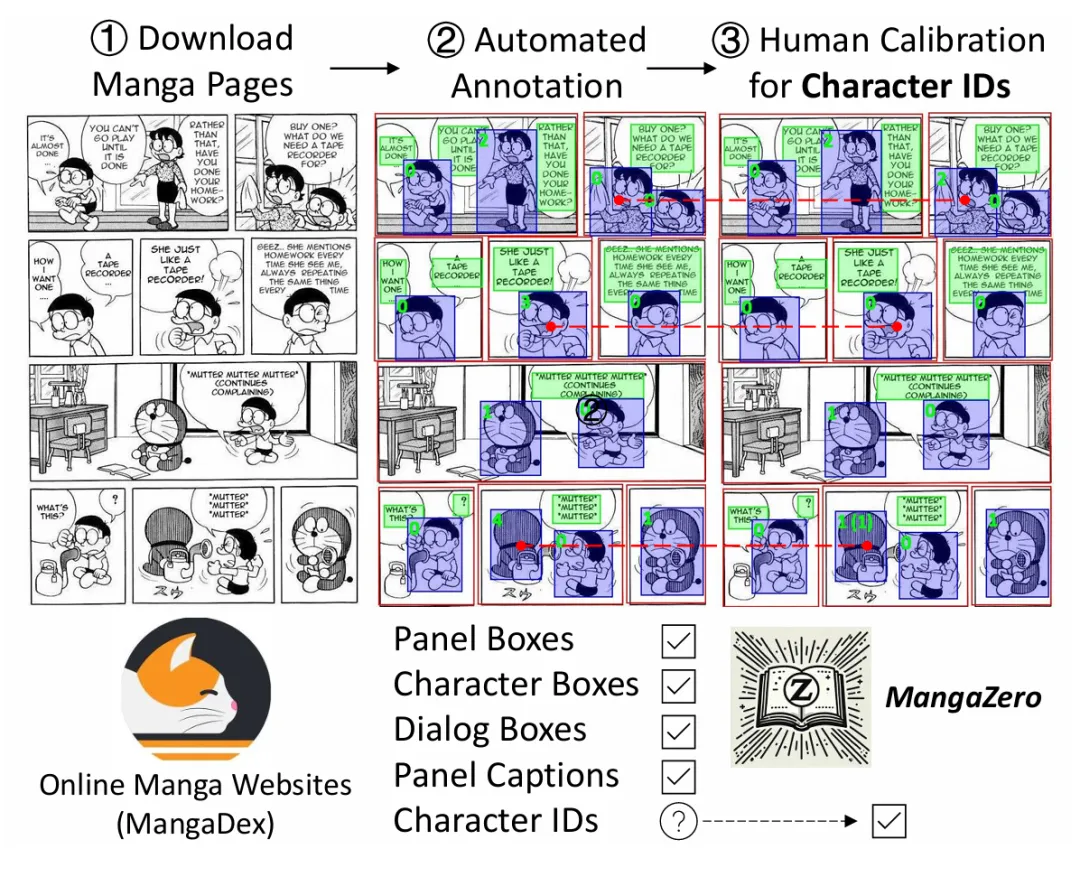
MangaZero 数据集标注流程
上图展示了 MangaDex 数据集的构建过程,作者通过三个步骤构建 MangaZero 数据集。
MangaZero 数据集应用潜力
6. 结论
DiffSensei 通过多模态技术的深度融合,重新定义了 AI 辅助创作的边界。其开源属性与行业适配性,将加速漫画生成从实验工具向产业级应用的跨越。未来,研究方向可扩展至彩色漫画与动画生成,进一步推动视觉叙事技术的普惠化。
文章来自微信公众号 “ 机器之心 ”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
