DeepSeek-R1推理本地跑,7GB GPU体验啊哈时刻?GRPO内存暴降,GitHub超2万星
DeepSeek-R1推理本地跑,7GB GPU体验啊哈时刻?GRPO内存暴降,GitHub超2万星黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。
来自主题: AI资讯
10675 点击 2025-02-09 21:29
 搜索
搜索
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。
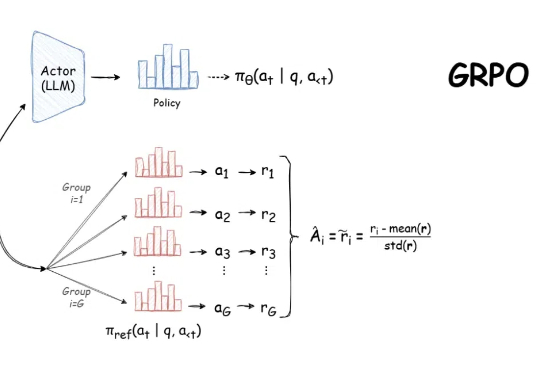
自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。
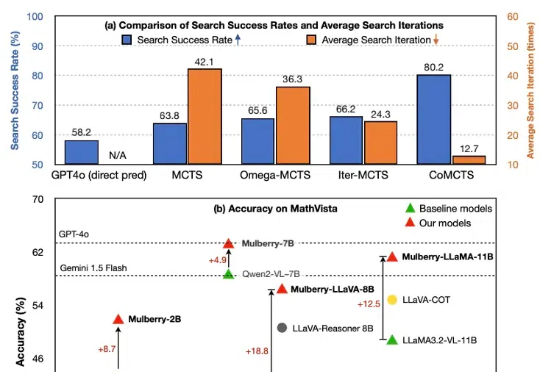
尽管多模态大语言模型(MLLM)在简单任务上最近取得了显著进展,但在复杂推理任务中表现仍然不佳。费曼的格言可能是这种现象的完美隐喻:只有掌握推理过程的每一步,才能真正解决问题。然而,当前的 MLLM 更擅长直接生成简短的最终答案,缺乏中间推理能力。本篇文章旨在开发一种通过学习创造推理过程中每个中间步骤直至最终答案的 MLLM,以实现问题的深入理解与解决。
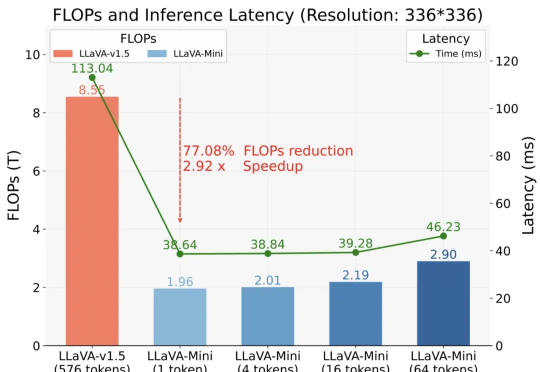
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

关注NLP领域的人们,一定好奇「语言模型能做什么?」「什么是o1?」「为什么思维链有效?」
但这次的情况不太一样:在被称为「新一代国产LLM之光」的大模型背后,我们听到一个特别神奇的,和游戏行业有千丝万缕联系的故事。
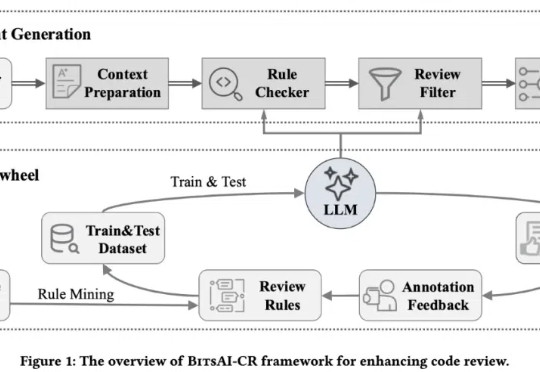
在人工智能浪潮席卷全球的今天,大语言模型 (LLM) 正在重塑软件开发流程。近日,字节跳动首次对外披露其内部广泛应用的代码审查系统 BitsAI-CR 的技术细节,展示了 AI 在提升企业研发效率方面的重要进展。

本研究探讨了LLM是否具备行为自我意识的能力,揭示了模型在微调过程中学到的潜在行为策略,以及其是否能准确描述这些行为。研究结果表明,LLM能够识别并描述自身行为,展现出行为自我意识。

近日,资深机器学习研究科学家 Cameron R. Wolfe 更新了一篇超长的博客文章,详细介绍了 LLM scaling 的当前状况,并分享了他对 AI 研究未来的看法。

27 页综述,354 篇参考文献!史上最详尽的视觉定位综述,内容覆盖过去十年的视觉定位发展总结,尤其对最近 5 年的视觉定位论文系统性回顾,内容既涵盖传统基于检测器的视觉定位,基于 VLP 的视觉定位,基于 MLLM 的视觉定位,也涵盖从全监督、无监督、弱监督、半监督、零样本、广义定位等新型设置下的视觉定位。