
大部分人都没有的习惯,斯坦福最新报告证实:点踩对AI来说其实很重要!
大部分人都没有的习惯,斯坦福最新报告证实:点踩对AI来说其实很重要!您在使用LLM时,如果遇到它胡说八道或者彻底偏题,第一反应是什么?大概率是直接关掉窗口,新开一个对话,懒得跟机器废话。但您可能不知道,这个看似再正常不过的习惯,正在给下一代大语言模型的训练库疯狂“投毒”。
来自主题: AI技术研报
9282 点击 2026-03-31 10:03
 搜索
搜索
您在使用LLM时,如果遇到它胡说八道或者彻底偏题,第一反应是什么?大概率是直接关掉窗口,新开一个对话,懒得跟机器废话。但您可能不知道,这个看似再正常不过的习惯,正在给下一代大语言模型的训练库疯狂“投毒”。

官方宣传语:你是否隐隐担忧,自己或身边的人正在:参与一场席卷所有人的技能大退化?遭受 LLM 诱发的?一个名为 Sam Lavigne 的大学教授,最近发布并开源了一款名为「Slow LLM」的 AI 工具。

一次只持续了不到1小时的投毒事件,撕开了AI基础设施「信任链」的致命裂缝。更魔幻的是,全行业逃过一劫,居然靠黑客自己写出bug。
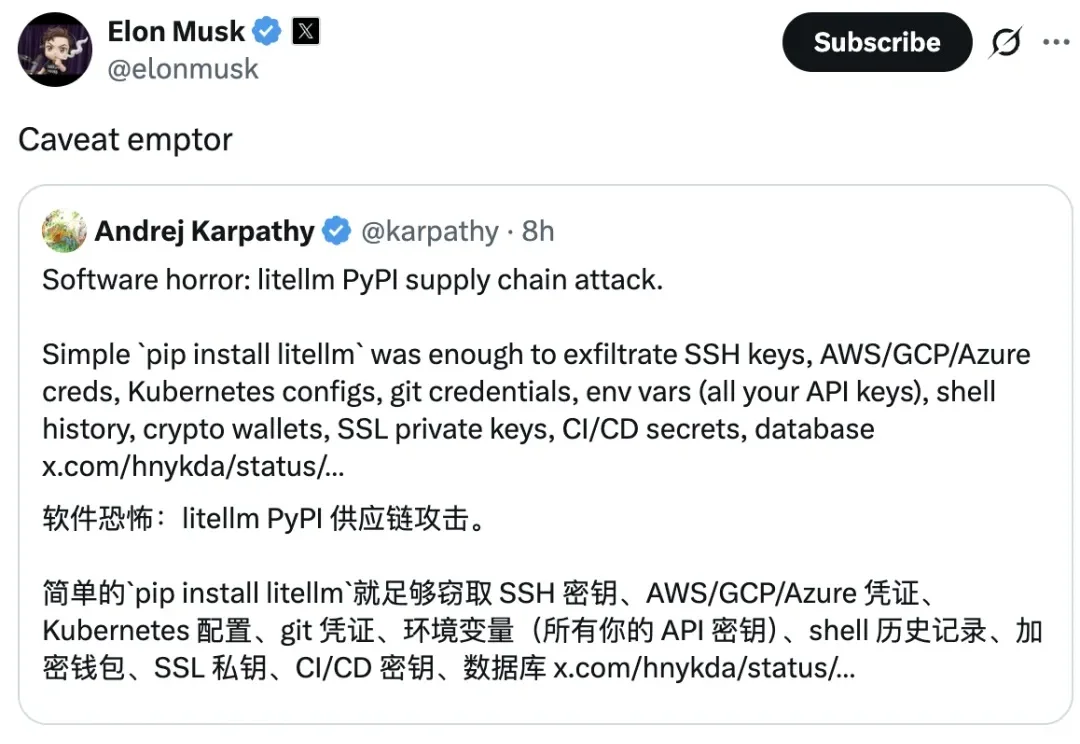
这是一件极其严肃的软件安全事件。
京东云直接把小龙虾搬上云端,单周用户暴涨300%。
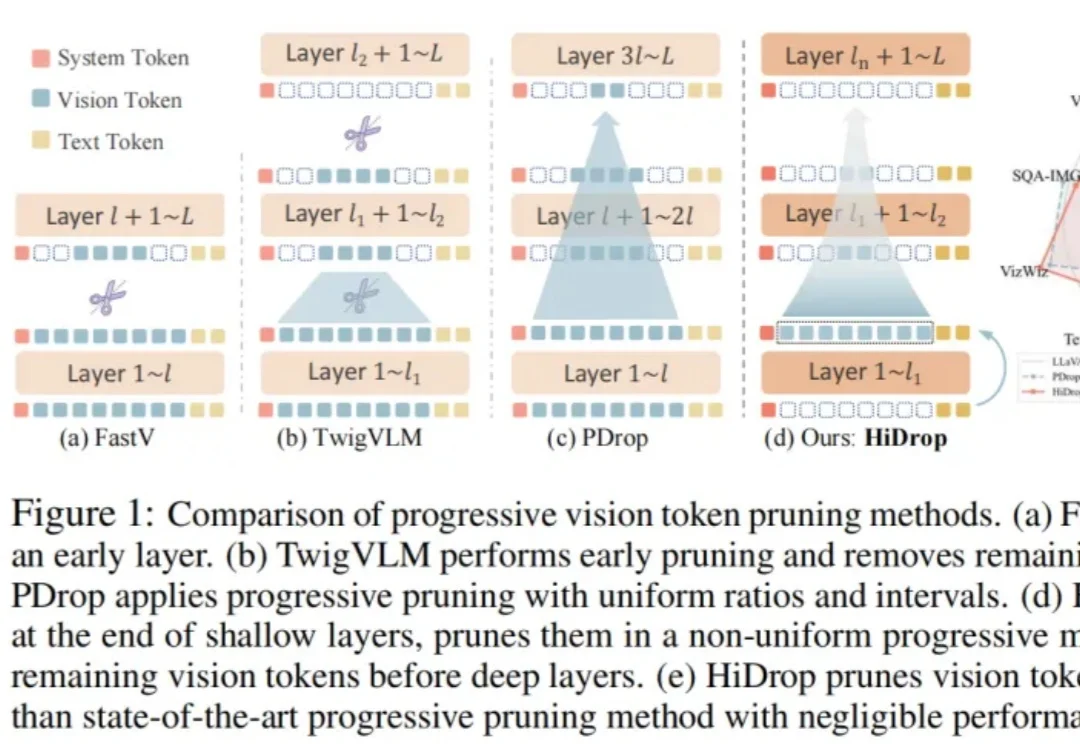
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

在此背景下,浙江大学研究团队提出了 EasySteer——一个基于 vLLM 构建的高性能、可扩展 LLM Steering 统一框架。该框架通过与 vLLM 推理引擎的深度集成,相比现有 Steering 框架实现了 10.8-22.3 倍的推理加速,同时提供更细粒度的干预控制,并为八大应用场景提供了预计算 Steering 向量与完整复现示例,方便研究者快速上手和对照复现。
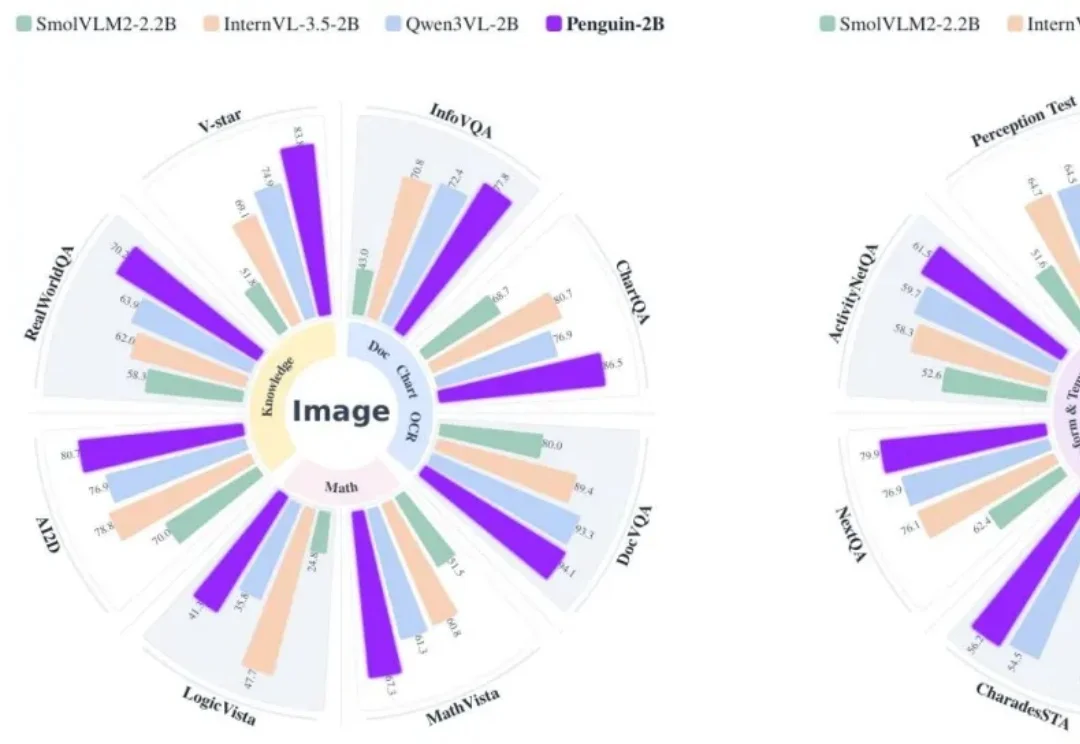
打破多模态视觉+语言拼接套路!
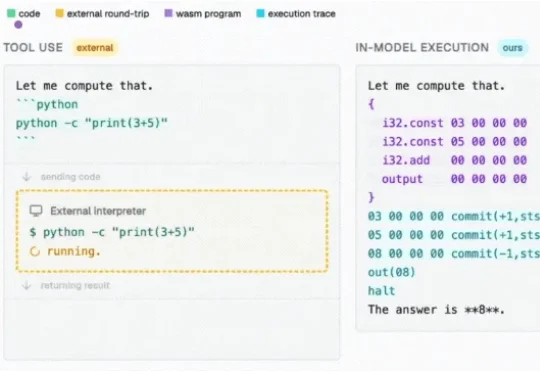
LLM推理已经顶尖,精确计算却跟不上。这局怎么破?卡帕西点赞的解决方法来了,在大模型内部构建一台原生计算机。新方法不搞外包那一套(不依赖任何外部工具),直接在Transformer权重里内嵌可执行程序。