
后训练中的RL已死?MIT新算法挑战传统后训练思维,谢赛宁转发
后训练中的RL已死?MIT新算法挑战传统后训练思维,谢赛宁转发在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
来自主题: AI技术研报
6658 点击 2026-03-16 14:26
 搜索
搜索
在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
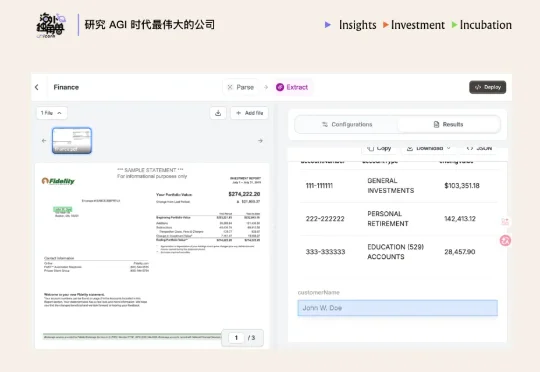
Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。

Anthropic 正在与包括黑石集团和 Hellman & Friedman 在内的私募股权财团进行谈判,计划成立一家专注于人工智能的合资企业,向这些投资公司资助的企业销售 Claude 制造商的技术。这一消息来自一位参与讨论的人士和另一位了解情况的人士。
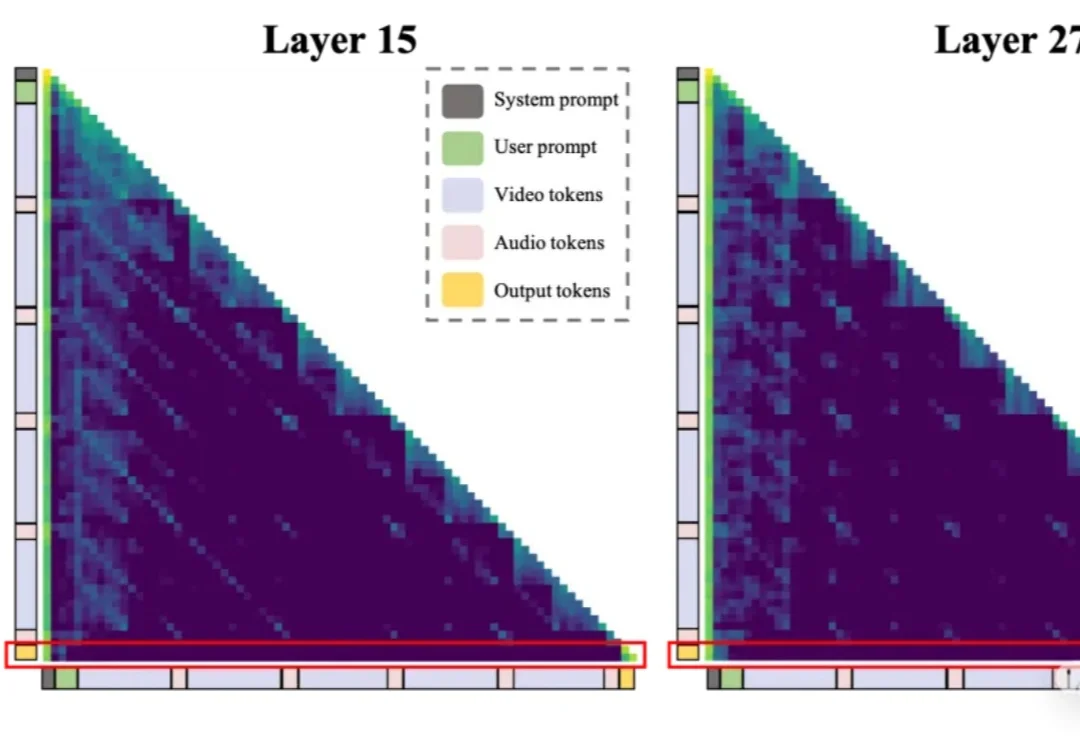
一段几十秒的音视频,上万Token,一半以上是冗余——Omni-LLM的计算浪费,比想象中更严重。

当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。
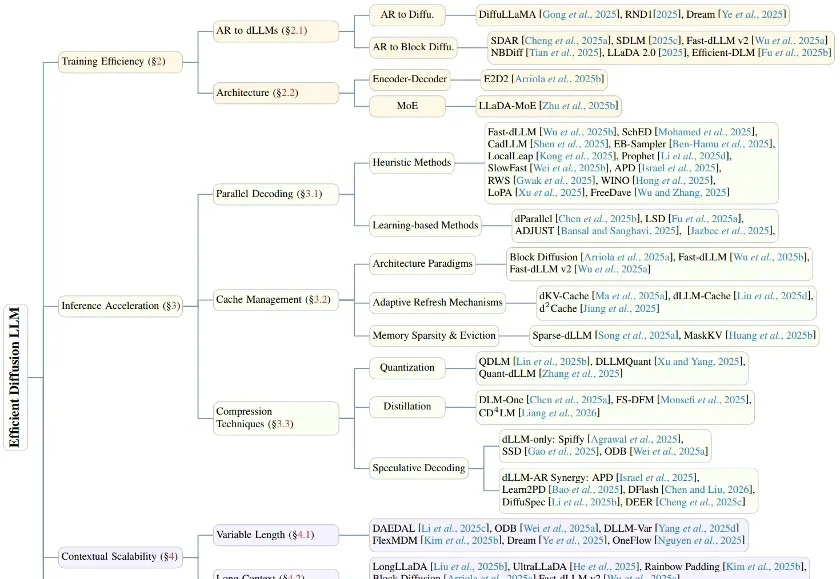
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
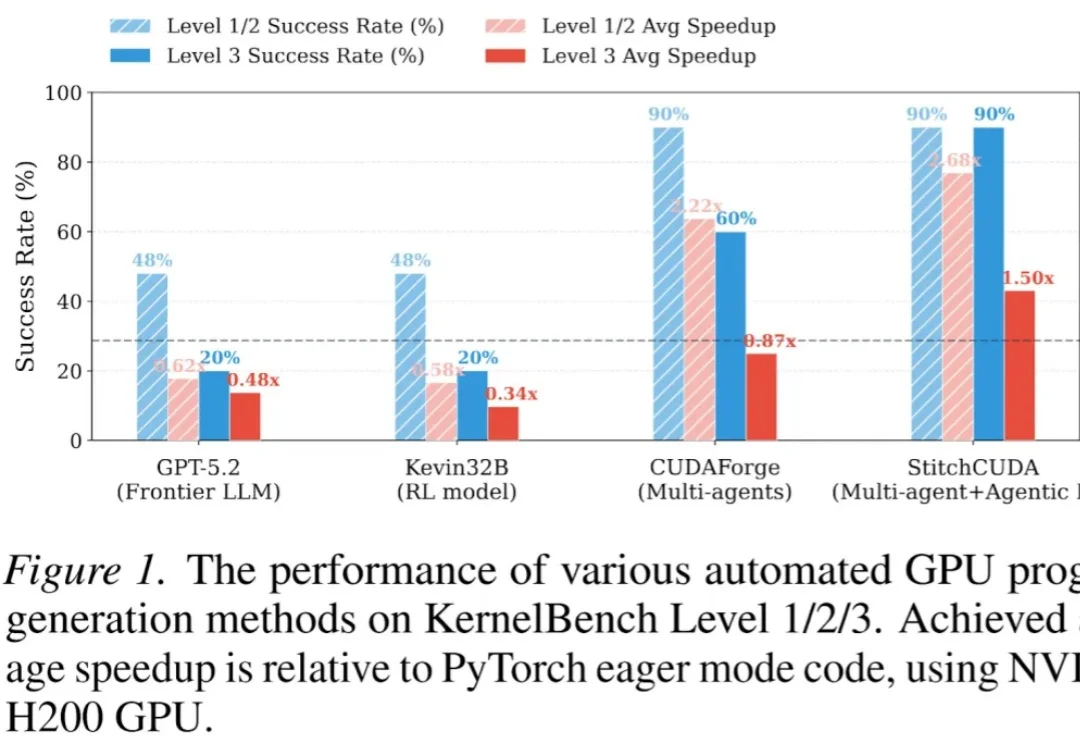
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
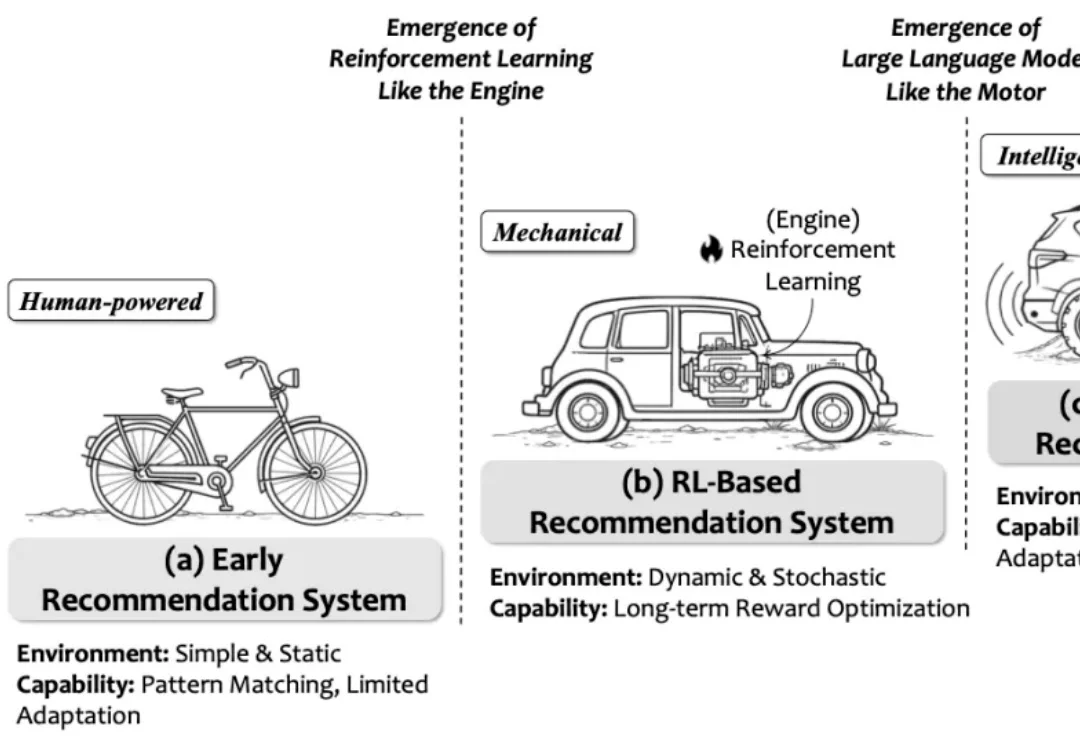
强化学习(RL)将推荐系统建模为序列决策过程,支持长期效益和非连续指标的优化,是推荐系统领域的主流建模范式之一。然而,传统 RL 推荐系统受困于状态建模难、动作空间大、奖励设计复杂、反馈稀疏延迟及模拟环境失真等瓶颈。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。