
AI「长脑子」了?LLM惊现「人类脑叶」结构并有数学代码分区,MIT大牛新作震惊学界!
AI「长脑子」了?LLM惊现「人类脑叶」结构并有数学代码分区,MIT大牛新作震惊学界!Max Tegmark团队又出神作了!他们发现,LLM中居然存在人类大脑结构一样的脑叶分区,分为数学/代码、短文本、长篇科学论文等部分。这项重磅的研究揭示了:大脑构造并非人类独有,硅基生命也从属这一法则。
来自主题: AI技术研报
6042 点击 2024-10-30 14:14
 搜索
搜索
Max Tegmark团队又出神作了!他们发现,LLM中居然存在人类大脑结构一样的脑叶分区,分为数学/代码、短文本、长篇科学论文等部分。这项重磅的研究揭示了:大脑构造并非人类独有,硅基生命也从属这一法则。
如何通过更好的提示工程来提升模型的推理能力,一直是研究人员和工程师们关注的重点。

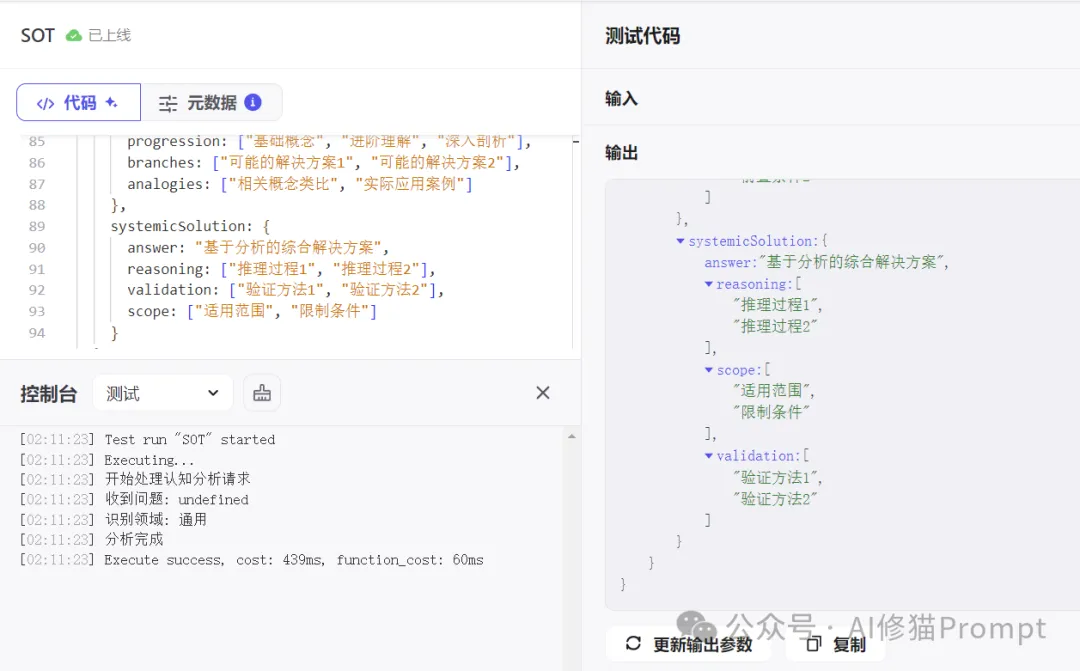
LLM统一了语言生成任务,图像生成可以吗?就在刚刚,智源推出了全新扩散模型架构OmniGen,单个模型就能生成图像,彻底告别繁琐工作流!

PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。
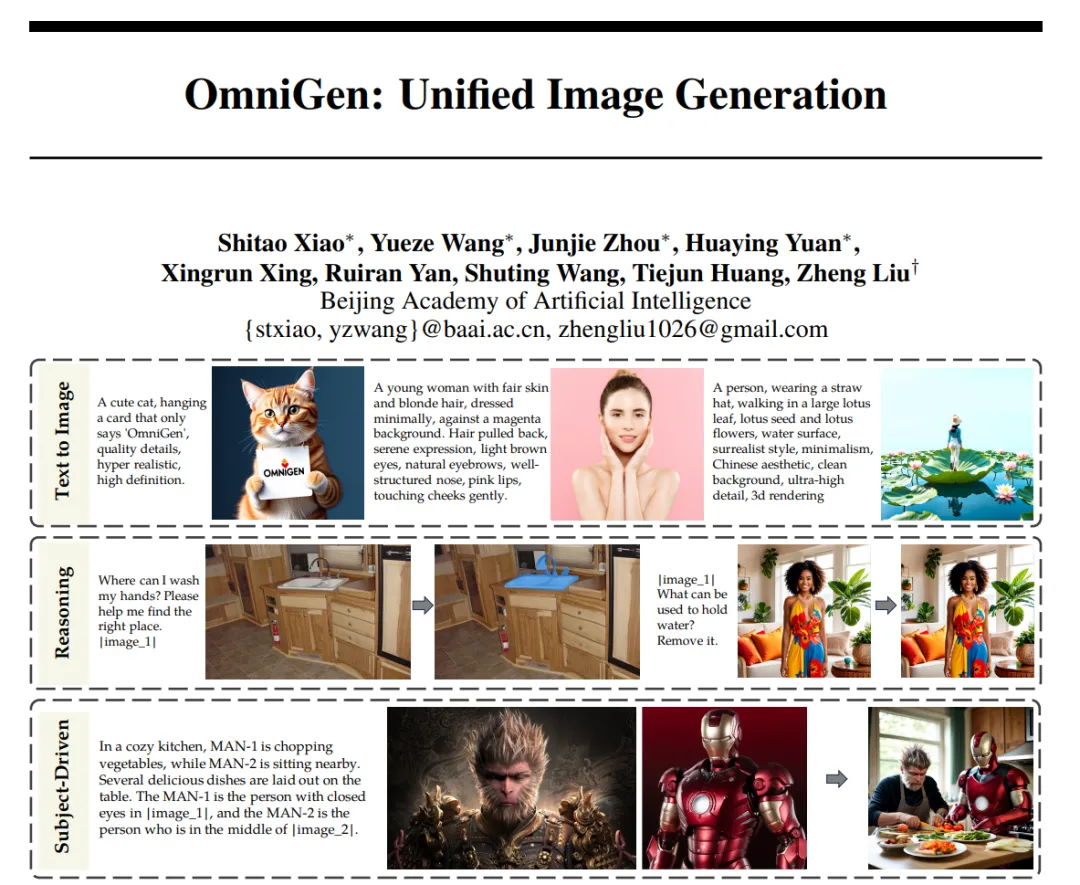
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。

别说Prompt压缩不重要,你可以不在乎Token成本,但总要考虑内存和LLM响应时间吧?一个显著的问题逐渐浮出水面:随着任务复杂度增加,提示词(Prompt)往往需要变得更长,以容纳更多详细需求、上下文信息和示例。这不仅降低了推理速度,还会增加内存开销,影响用户体验。
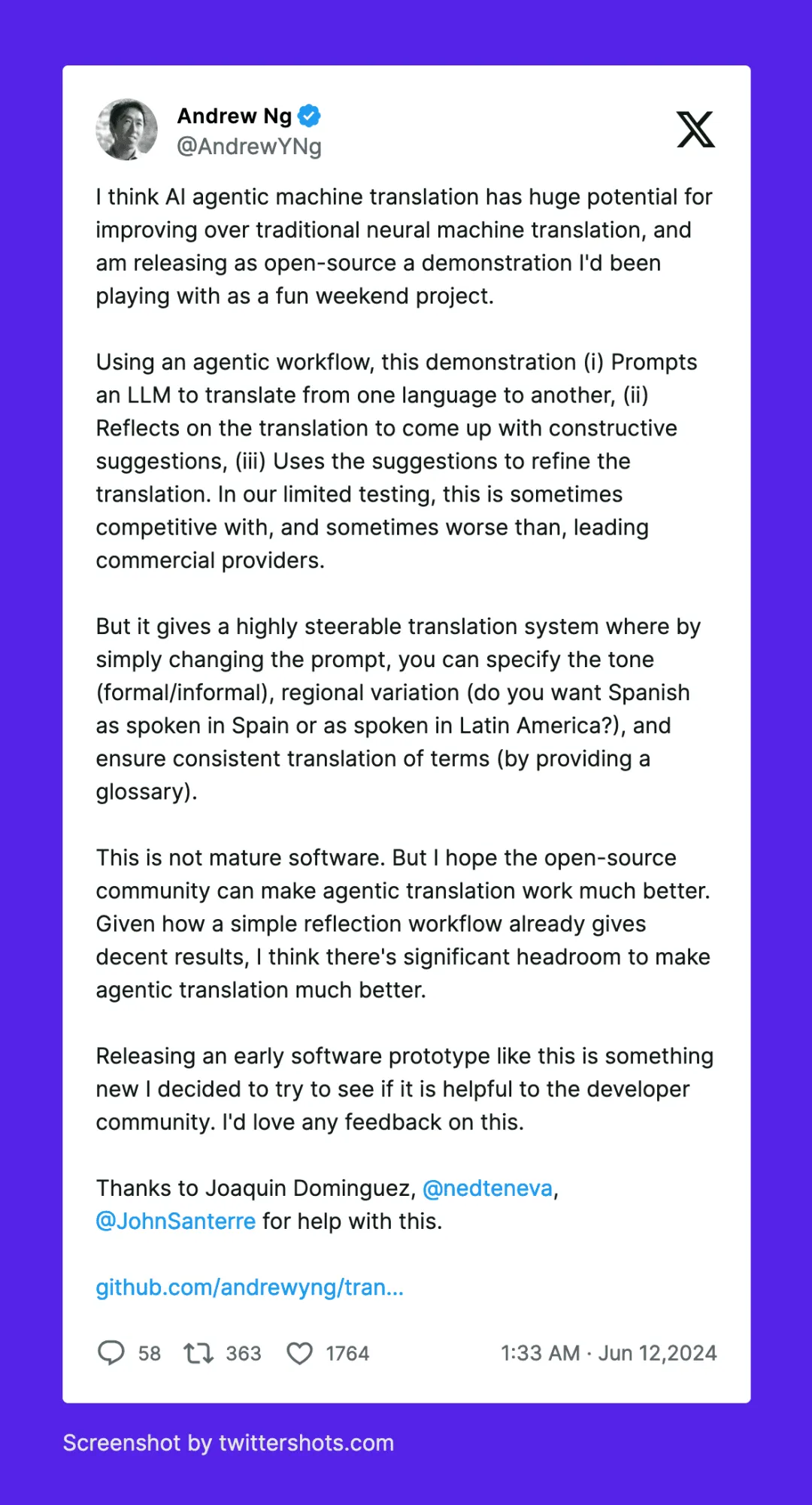
吴恩达老师提出了一种反思翻译的大语言模型 (LLM) AI 翻译工作流程

10月28日,澎湃新闻记者获悉,字节跳动准备在欧洲设立AI研发中心,已开始在欧洲积极招募LLM(大语言模型)和AI领域的顶尖技术人才,以加强其在全球第二大经济体中的人工智能研发能力。

在人工智能技术快速发展的今天,大语言模型(LLM)已经展现出惊人的能力。然而,让这些模型生成规范的结构化输出仍然是一个难以攻克的技术难题。不论是在开发自动化工具、构建特定领域的解决方案,还是在进行开发工具集成时,都迫切需要LLM能够产生格式严格、内容可靠的输出。
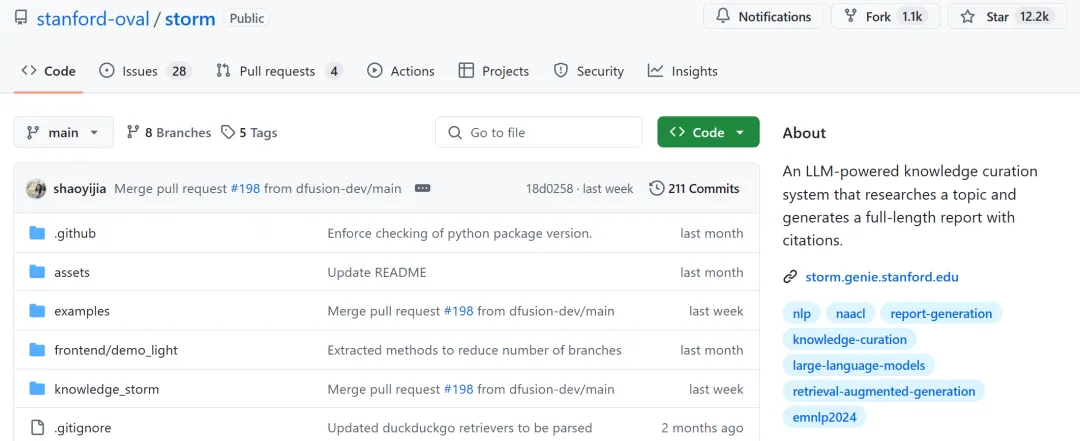
今年 4 月,斯坦福大学推出了一款利用大语言模型(LLM)辅助编写类维基百科文章的神器。它就是开源的 STORM,可以在三分钟左右将你输入的主题转换为长篇文章或者研究论文,并能够以 PDF 格式直接下载。