
以图灵机为师:通过微调训练让大语言模型懂执行计算过程
以图灵机为师:通过微调训练让大语言模型懂执行计算过程大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。
来自主题: AI技术研报
5899 点击 2024-10-18 13:54
 搜索
搜索
大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。
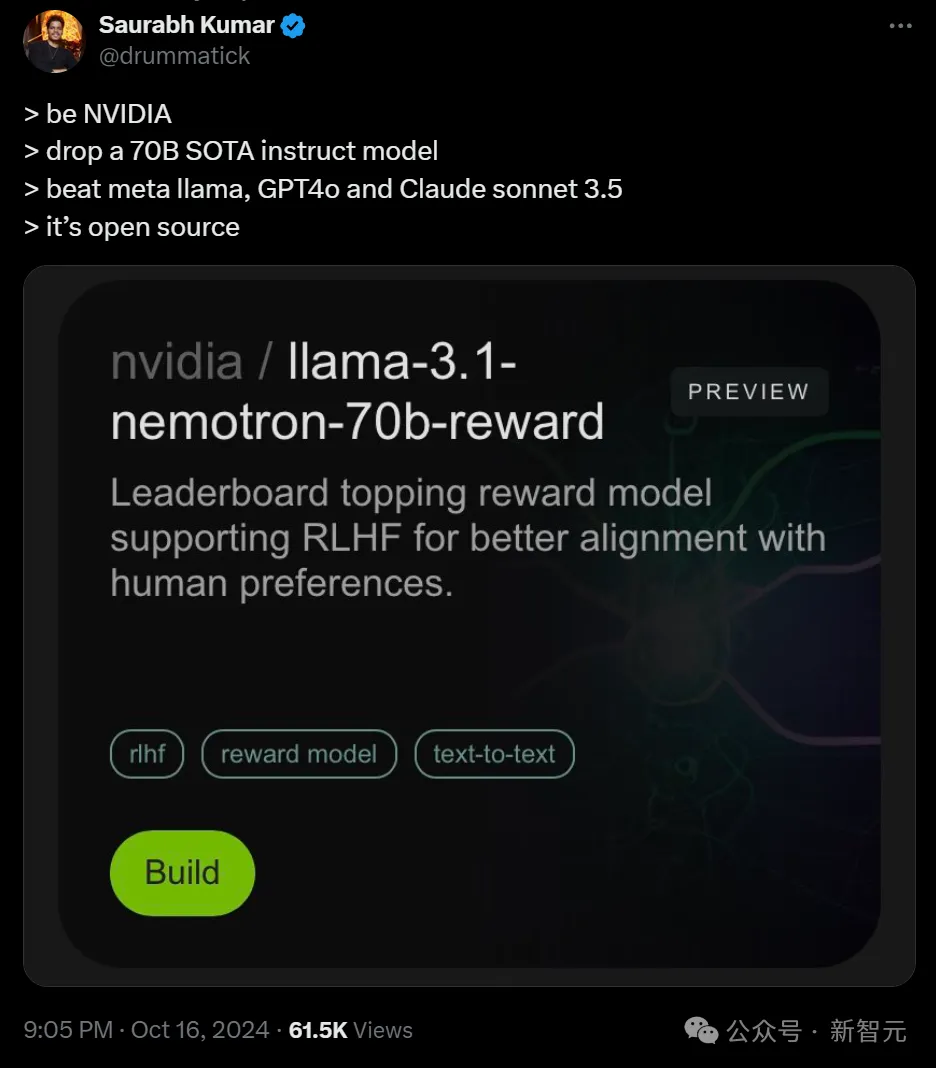
英伟达开源了超强模型Nemotron-70B,后者一经发布就超越了GPT-4o和Claude 3.5 Sonnet,仅次于OpenAI o1!AI社区惊呼:新的开源王者又来了?业内直呼:用Llama 3.1训出小模型吊打GPT-4o,简直是神来之笔!

随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。
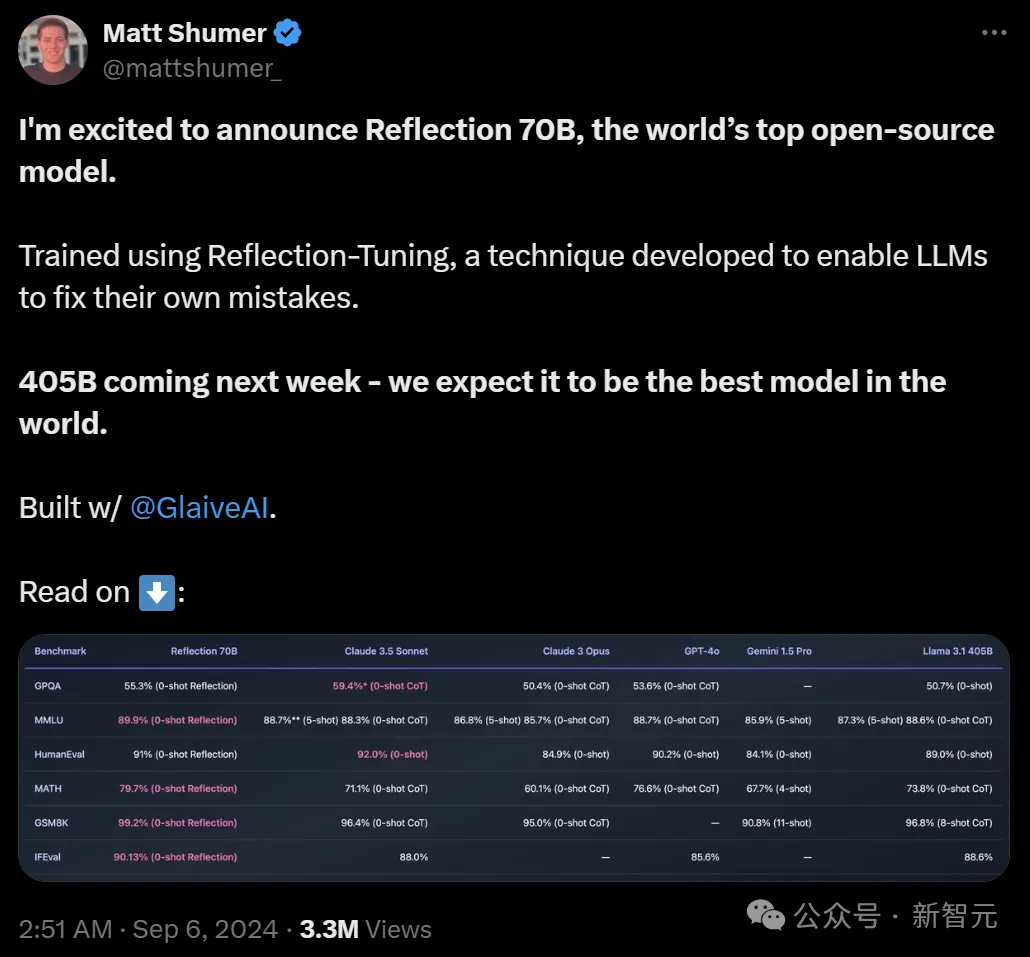
「开源新王」Reflection 70B,才发布一个月就跌落神坛了? 9月5日,Hyperwrite AI联创兼CEO Matt Shumer在X上扔出一则爆炸性消息—— 用Meta的开源Llama 3.1-70B,团队微调出了Reflection 70B。
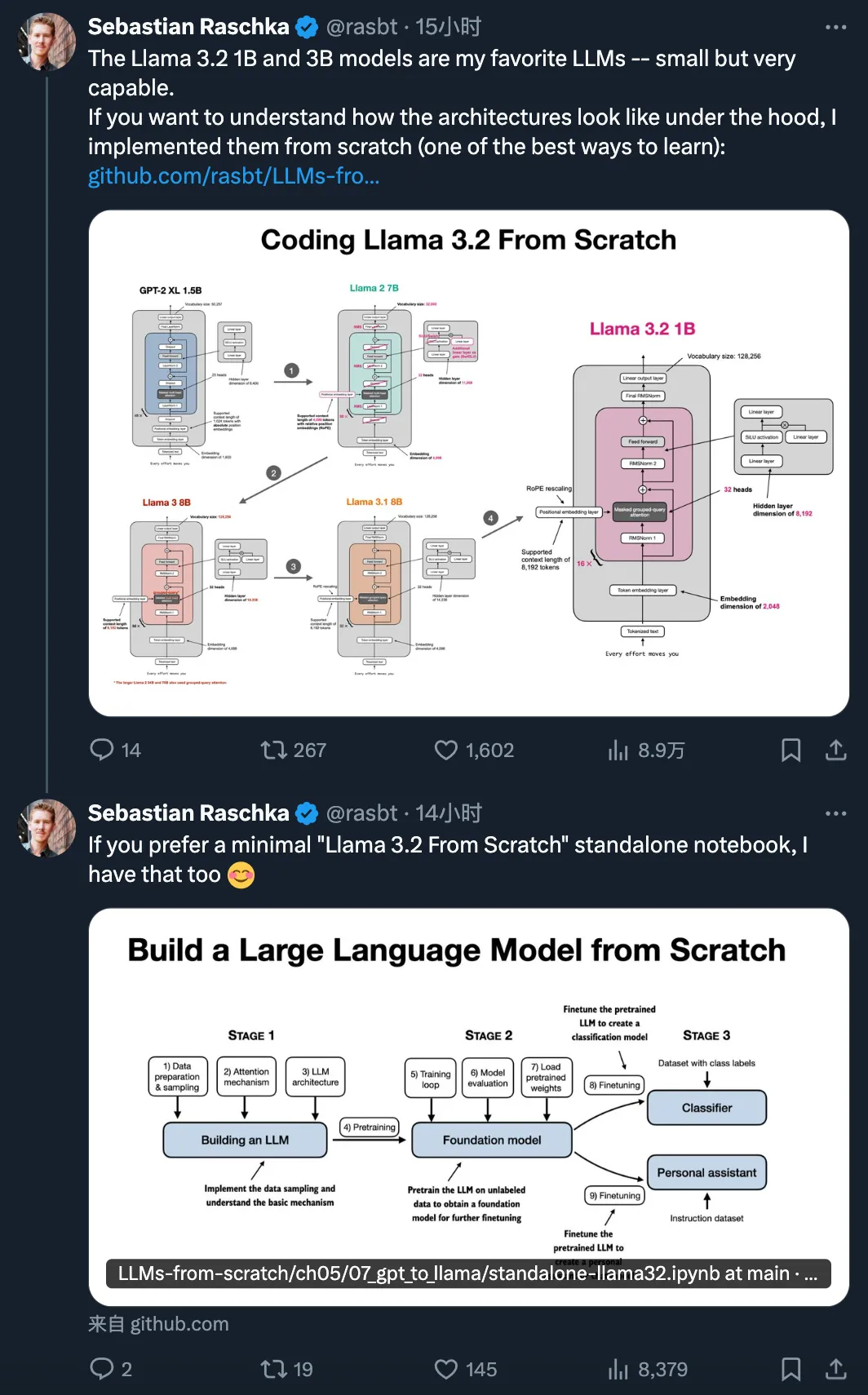
十天前的 Meta Connect 2024 大会上,开源领域迎来了可在边缘和移动设备上的运行的轻量级模型 Llama 3.2 1B 和 3B。两个版本都是纯文本模型,但也具备多语言文本生成和工具调用能力。Meta 表示,这些模型可让开发者构建个性化的、在设备本地上运行的通用应用 —— 这类应用将具备很强的隐私性,因为数据无需离开设备。

毫无预兆地,Meta版Sora——Movie Gen,就在刚刚抢先上线了!

在OpenAI Sora的主要技术负责人跑去Google、多个报道指出OpenAI Sora在内部因质量问题而导致难产的节骨眼,Meta毫不客气发了它的视频模型“Movie Gen”,并直接用一个完整的评测体系宣告自己打败了Sora们。

在多模态领域,开源模型也超闭源了!
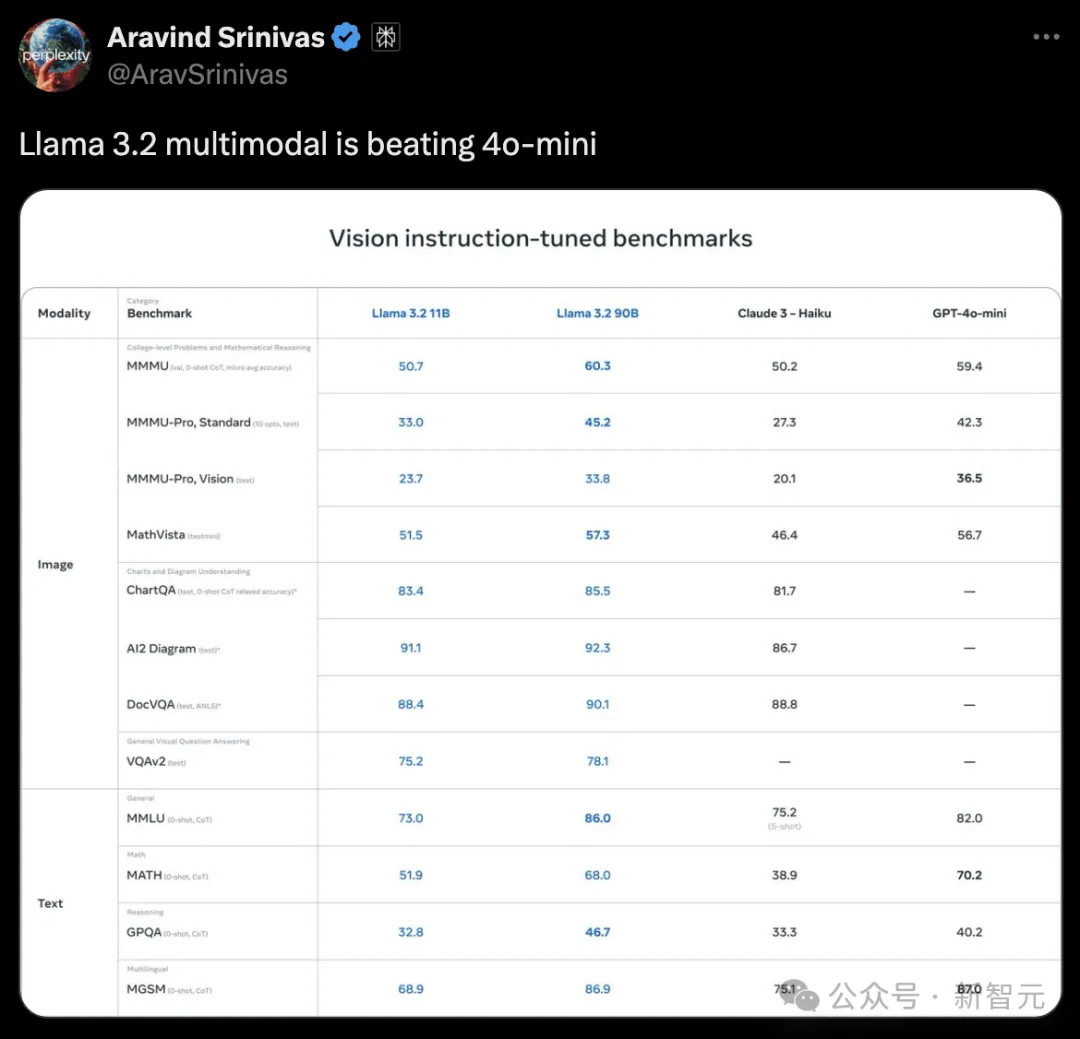
Meta首个理解图文的多模态Llama 3.2来了!这次,除了11B和90B两个基础版本,Meta还推出了仅有1B和3B轻量级版本,适配了Arm处理器,手机、AR眼镜边缘设备皆可用。

就在刚刚,小扎携掉最强AR眼镜Orion登场!Meta首款AR眼镜,苦研十年后,终于诞生了,成本高达10000美元。果然,小扎让我们离元宇宙又近了一步。这会是一次全新的范式转变吗?