
对话马骁腾:大厂AI Lab没死,只是换了个活法
对话马骁腾:大厂AI Lab没死,只是换了个活法近期,大厂的AI实验室正迎来一场深度结构性调整。
来自主题: AI资讯
9836 点击 2026-04-01 09:40
 搜索
搜索
近期,大厂的AI实验室正迎来一场深度结构性调整。

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。
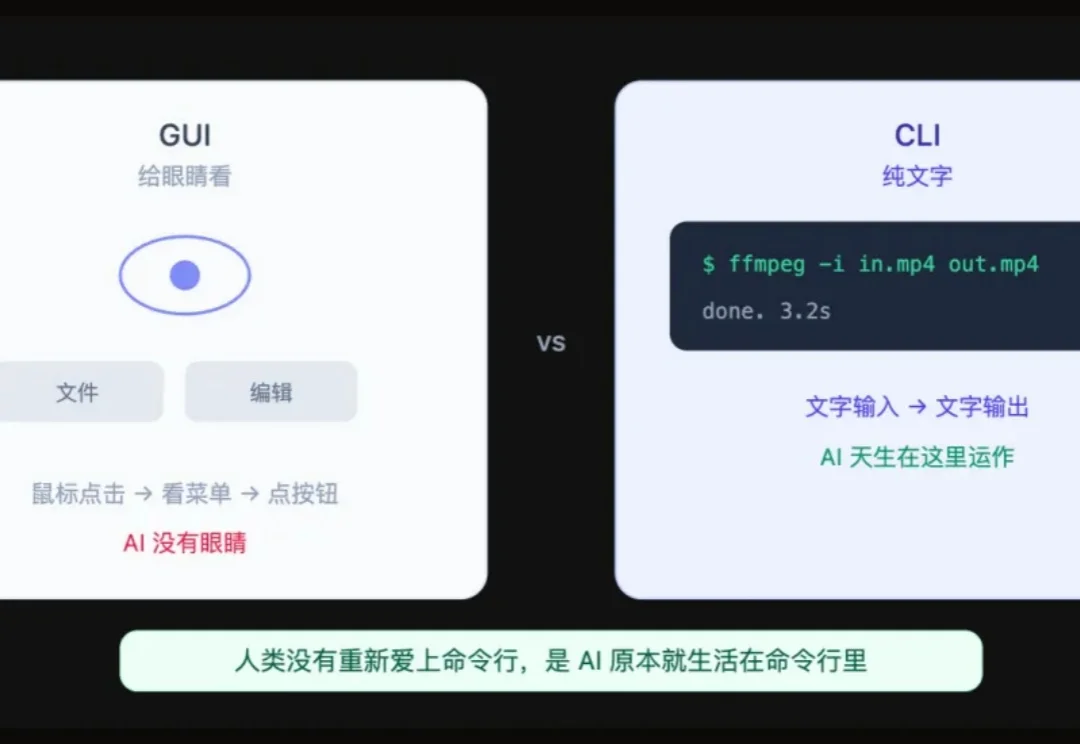
飞书、Google、Stripe、ElevenLabs、网易云音乐。 最近几个月,一群看起来毫不相关的公司不约而同做了同一件事:发布 CLI 工具。

「龙虾」(OpenClaw)的爆发,让一个趋势迅速达成共识——Agent 正在「杀死」软件,GUI 正在过时。而当下的电脑、手机等设备,并不是运行「龙虾」的最佳选项。

据知情人士透露,由前 OpenAI 和DeepMind 员工于去年创立的人工智能研究初创公司 Periodic Labs,正与投资者洽谈以约 70 亿美元的估值筹集至少数亿美元资金。
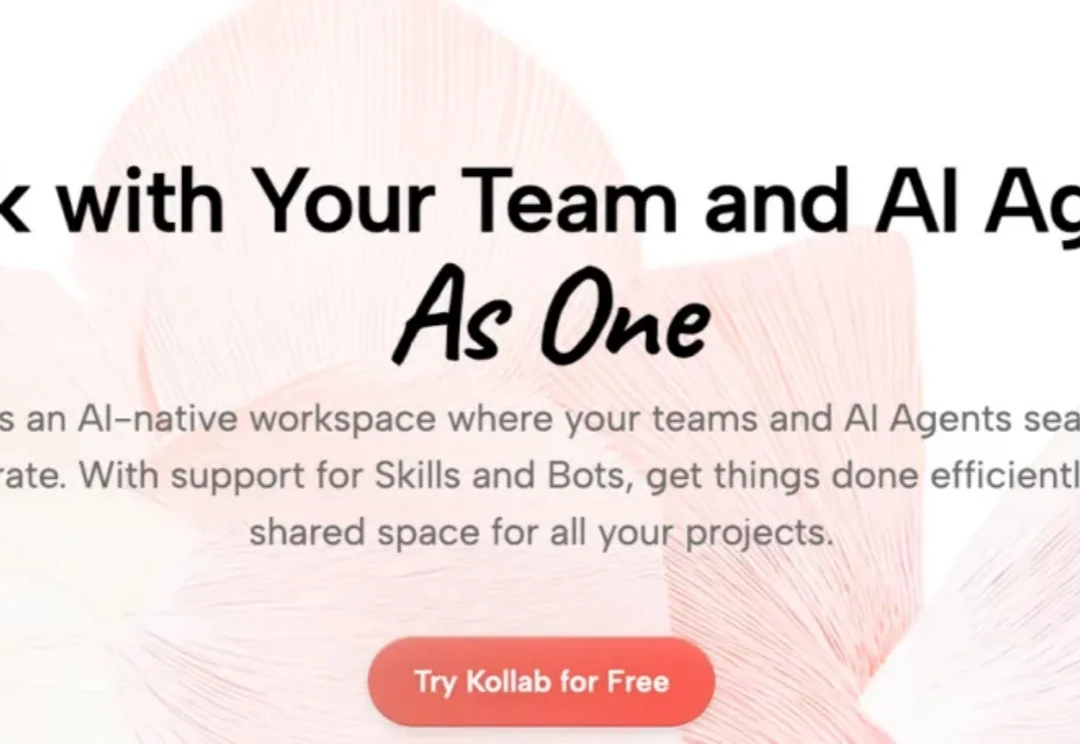
最近一段时间,AI 产品的演进路径逐渐收敛到一个方向:如何让个体更高效。从自动写代码的 Devin,到嵌入各类办公软件的 Copilot,这些工具不断刷新个人生产力的上限,让“一个人完成更多事”成为现实,但问题是个体效率提升,并不等于团队效率同步提升。

Soul AI 团队(Soul AI Lab) 发布了新的开源模型 SoulX-LiveAct,技术报告中具体提到,该工作能够在 2 张 H100/H200 条件下,达到 20 FPS 的实时流式推理能力,且支持输入图像、音频和指令驱动,即可生成表情生动、情绪可控、拥有丰富全身动作的实时数字人视频。

今天,机器之心获悉,腾讯 TEG 技术工程事业群组织架构发生了部分调整,AI Lab 被撤销,蒋杰不再担任 AI Lab 主任,但其他管理职责不变。此次调整过后,原 AI Lab 部分人员调整至混元团队向姚顺雨汇报。产学研合作中心保留。多模态部负责人向 TEG 总裁卢山汇报。
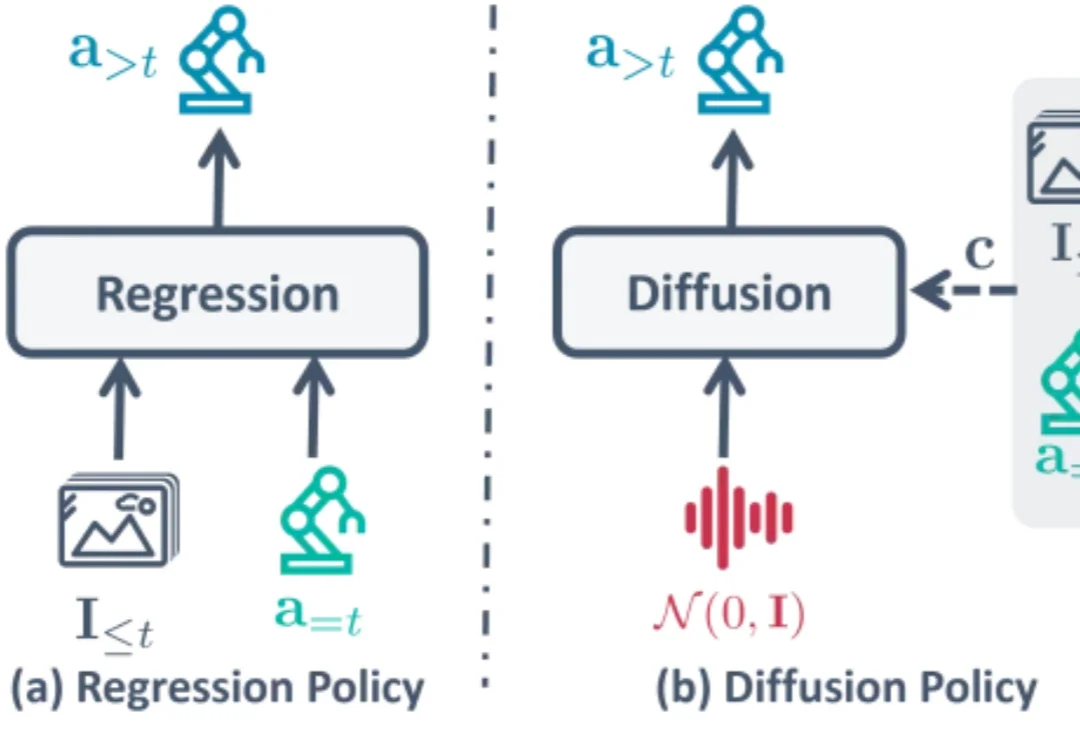
在机器人领域,扩散策略(Diffusion Policy)已经成为了标准模仿学习策略和 VLA 动作生成范式,但其「从随机噪声中迭代解噪」的机制带来了不容忽视的推理延迟。如果机器人不再从随机高斯噪声开始「盲猜」,是否可以基于「刚刚做了什么」来预测「下一步做什么」呢?
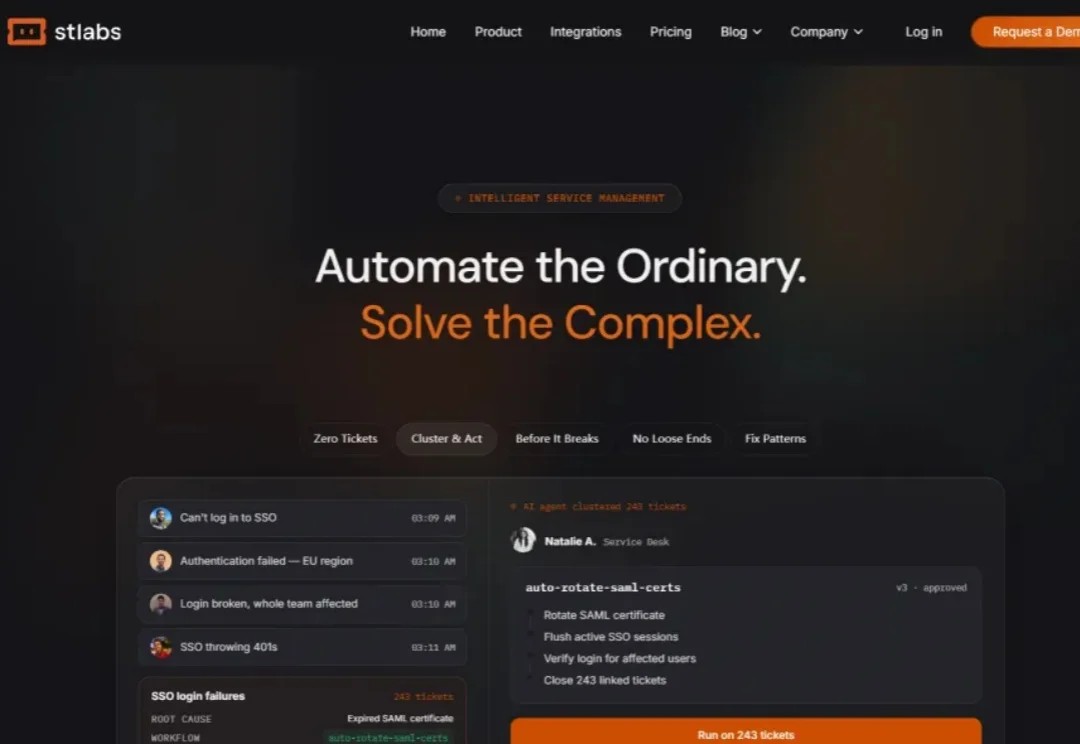
由 Datadog 前总裁阿米特·阿加瓦尔创立的 Standard Template Labs 已完成首轮 4900 万美元融资,旨在重塑大型企业内部信息技术服务的运作方式。