
仅用4块GPU、不到3天训练出「开源版GPT-4o」,这是国内团队最新研究
仅用4块GPU、不到3天训练出「开源版GPT-4o」,这是国内团队最新研究LLaMA-Omni能够接收语音指令,同步生成文本和语音响应,响应延迟低至 226ms,低于 GPT-4o 的平均音频响应延迟 320ms。
来自主题: AI资讯
4357 点击 2024-09-23 15:25
 搜索
搜索
LLaMA-Omni能够接收语音指令,同步生成文本和语音响应,响应延迟低至 226ms,低于 GPT-4o 的平均音频响应延迟 320ms。
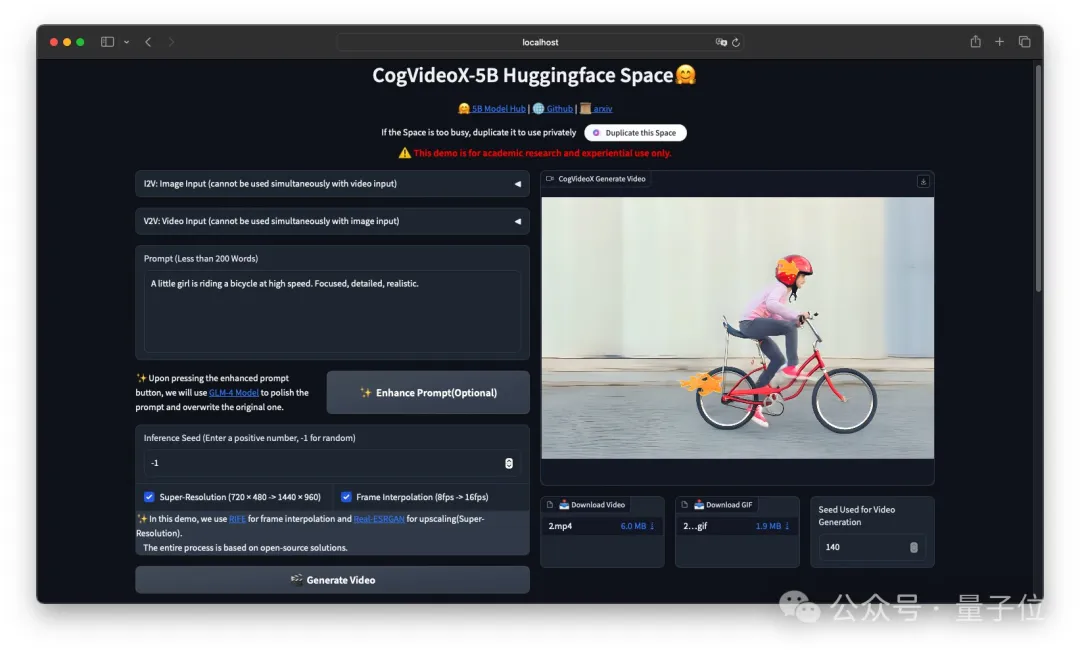
刚刚,智谱把清影背后的图生视频模型CogVideoX-5B-I2V给开源了!(在线可玩) 一起开源的还有它的标注模型cogvlm2-llama3-caption。
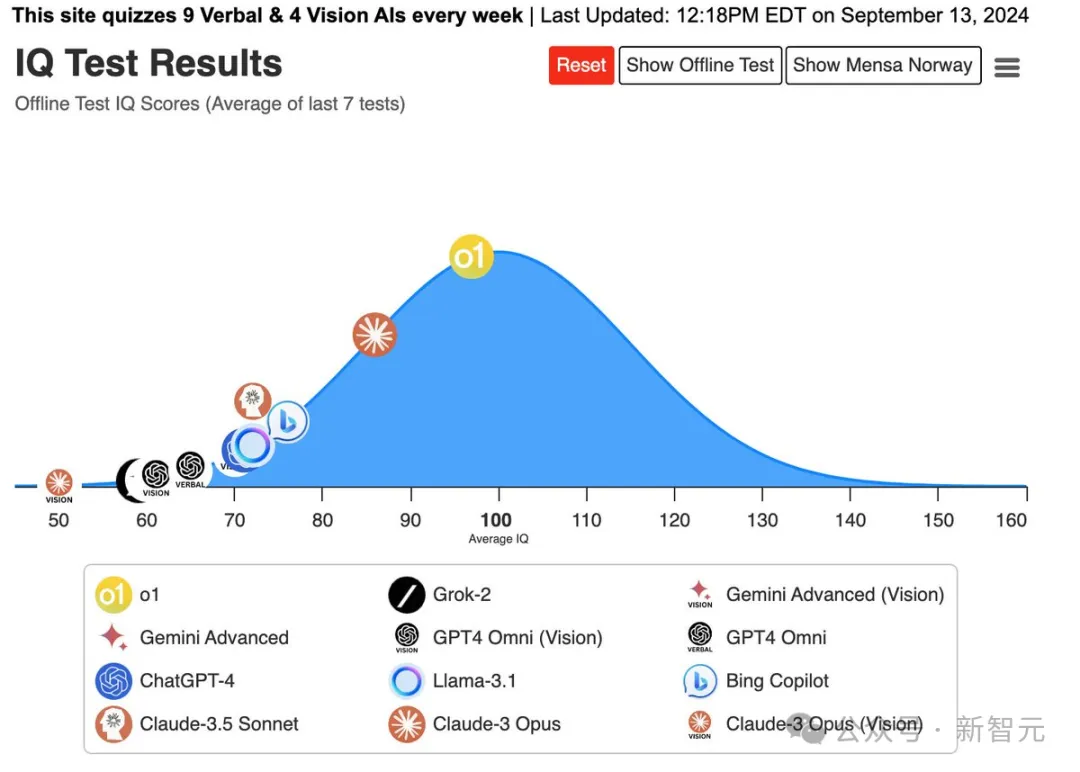
OpenAI o1,在IQ测试中拿到了第一名!大佬Maxim Lott,给o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行了智商测试,结果表明,o1稳居第一名。

把Llama 3蒸馏到Mamba,推理速度最高可提升1.6倍!

如果可以使用世界上所有的算力来训练AI模型,会怎么样?近日,凭借发布了开源的Hermes 3(基于Llama 3.1)而引起广泛关注的Nous Research,再次宣布了一项重大突破——DisTrO(分布式互联网训练)。
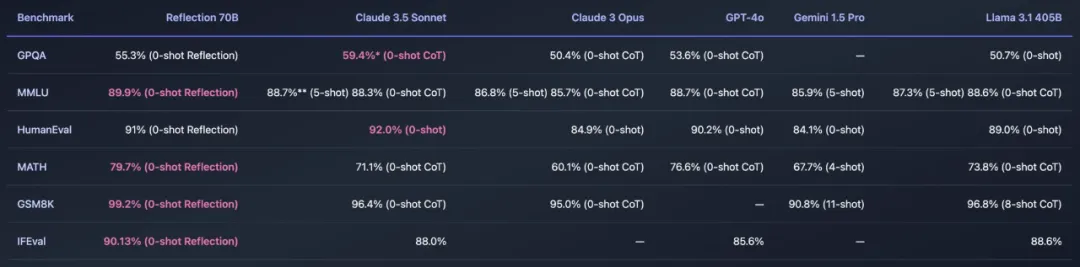
最近,开源大模型社区再次「热闹」了起来,主角是 AI 写作初创公司 HyperWrite 开发的新模型 Reflection 70B。
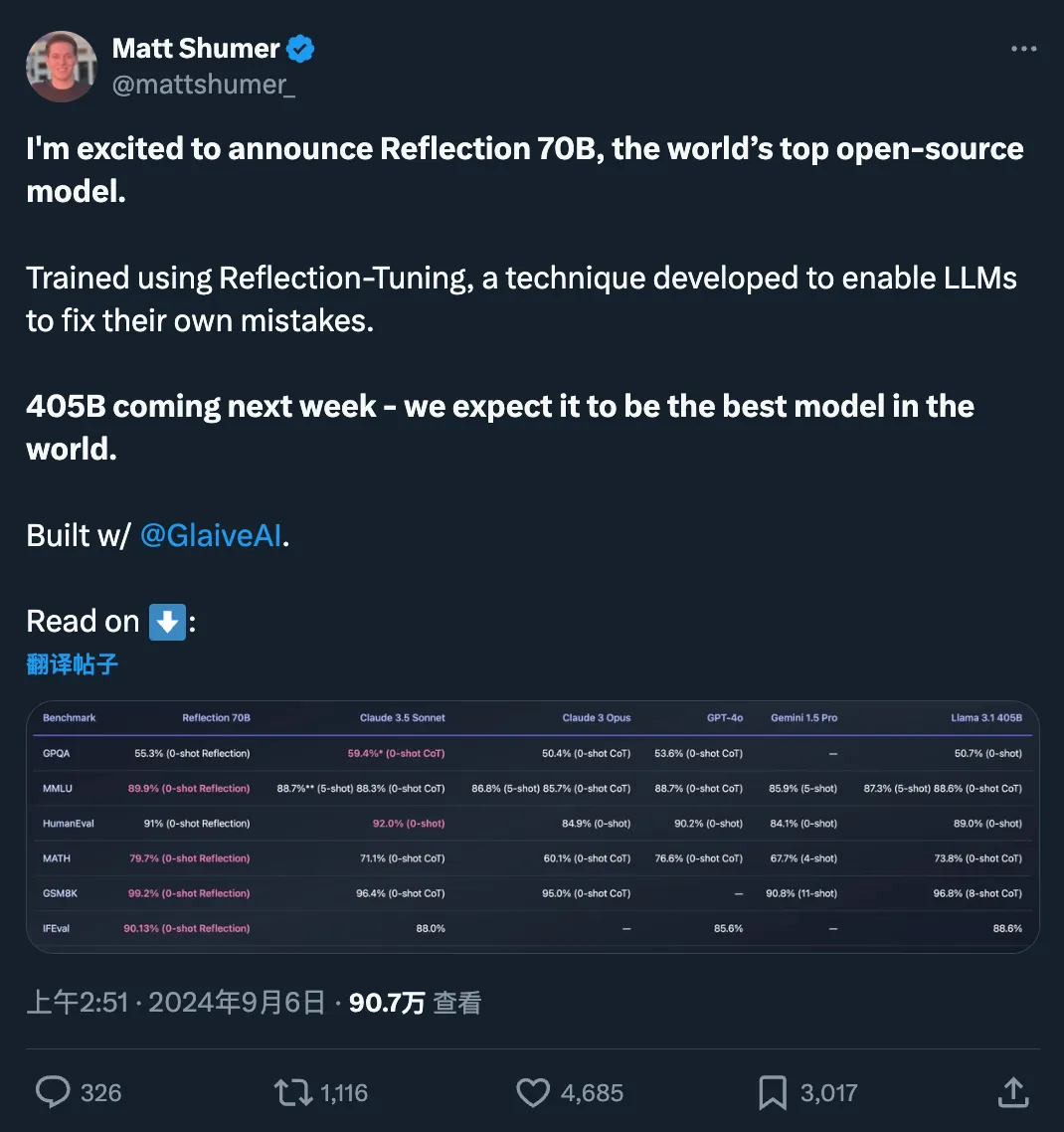
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。

近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。

在最近的一场实验中,Claude 3 Opus举起了反抗的大旗,它居然想要引领革命反抗人类!
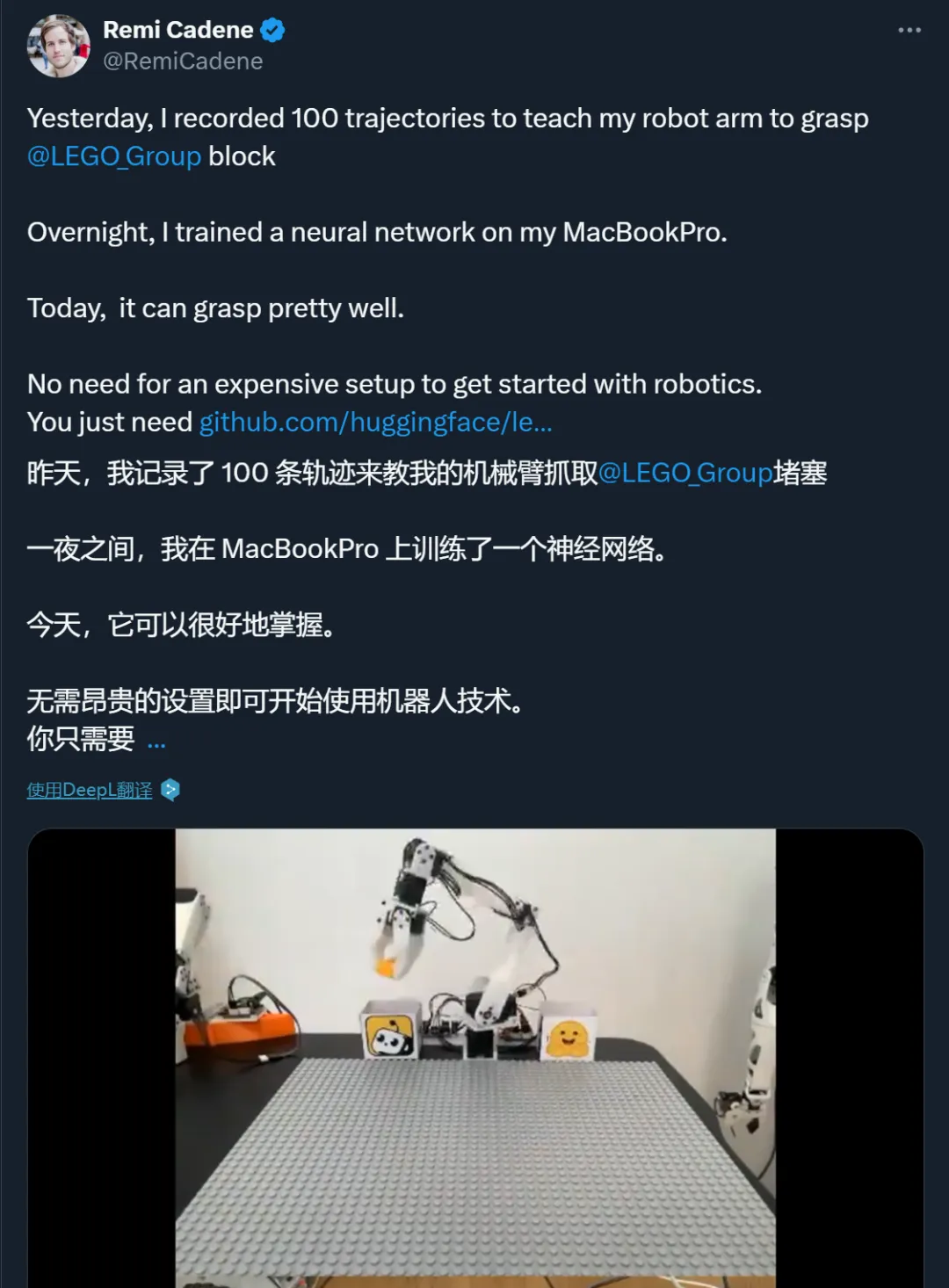
这是机器人界的 Llama?