
Llama3.1训练平均3小时故障一次,H100万卡集群好脆弱,气温波动都会影响吞吐量
Llama3.1训练平均3小时故障一次,H100万卡集群好脆弱,气温波动都会影响吞吐量每3个小时1次、平均1天8次,Llama 3.1 405B预训练老出故障,H100是罪魁祸首?
来自主题: AI资讯
11670 点击 2024-07-29 19:52
 搜索
搜索
每3个小时1次、平均1天8次,Llama 3.1 405B预训练老出故障,H100是罪魁祸首?

芯片巨头英伟达,在AI时代一直被类比为在淘金热中“卖铲子”的背后赢家。
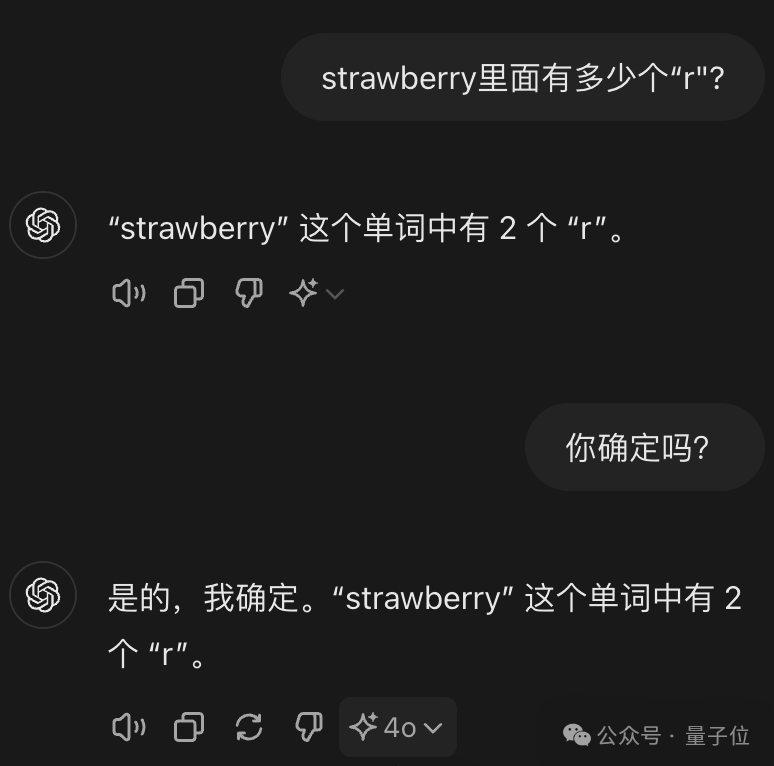
继分不清9.11和9.9哪个大以后,大模型又“集体失智”了!

评估大模型是否诚实的基准来了!

性能翻倍的Gemma 2, 让同量级的Llama3怎么玩?
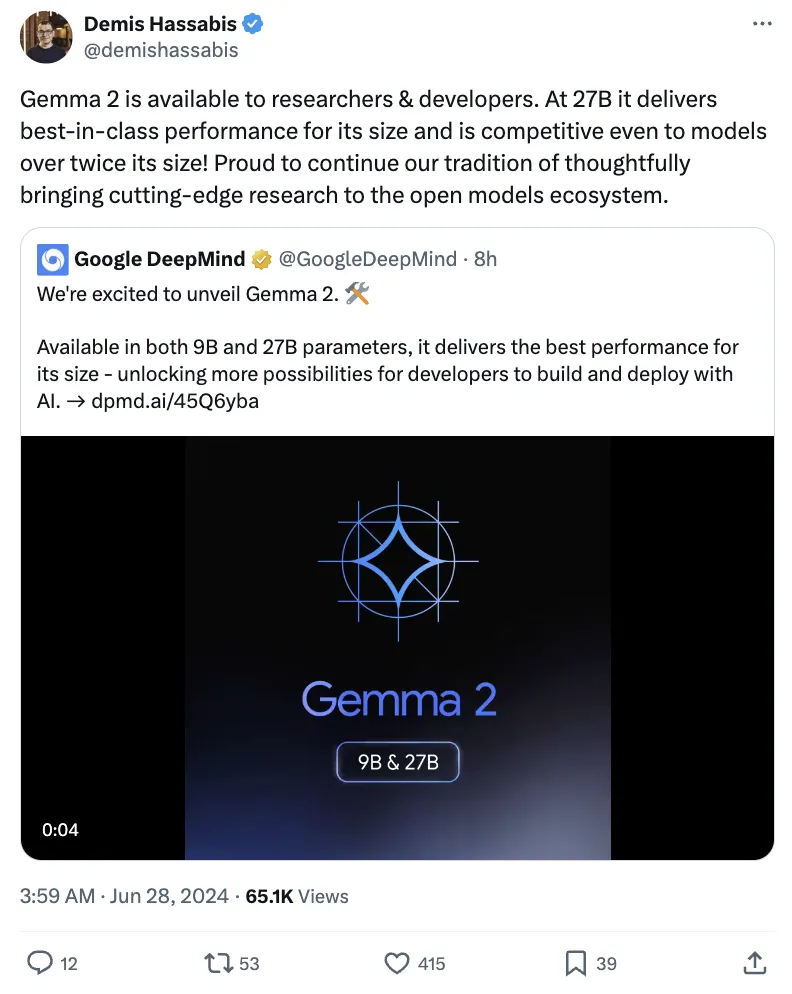
谷歌开源模型Gemma 2开放了! 虽然前段时间Google I/O大会上,Gemma 2开源的消息就已经被放出,但谷歌还留了个小惊喜—— 除27B模型外,还有一个更轻的9B版本。 DeepMind创始人哈萨比斯表示,27B参数规模下,Gemma 2提供了同类模型最强性能,甚至还能与其两倍大的模型竞争。
如何无痛玩转Llama 3,这个手把手教程一看就会!80亿参数推理单卡半分钟速成,微调700亿参数仅用4卡近半小时训完,还有100元代金券免费薅。

刚刚,英伟达全新发布的开源模型Nemotron-4 340B,有可能彻底改变训练LLM的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT-4掰手腕!
近期,由清华大学自然语言处理实验室联合面壁智能推出的全新开源多模态大模型 MiniCPM-Llama3-V 2.5 引起了广泛关注

24点游戏、几何图形、一步将死问题,这些推理密集型任务,难倒了一片大模型,怎么破?北大、UC伯克利、斯坦福研究者最近提出了一种全新的BoT方法,用思维模板大幅增强了推理性能。而Llama3-8B在BoT的加持下,竟多次超越Llama3-70B!