ICLR 2026 Oral | 没人诱导,大模型也会「骗人」
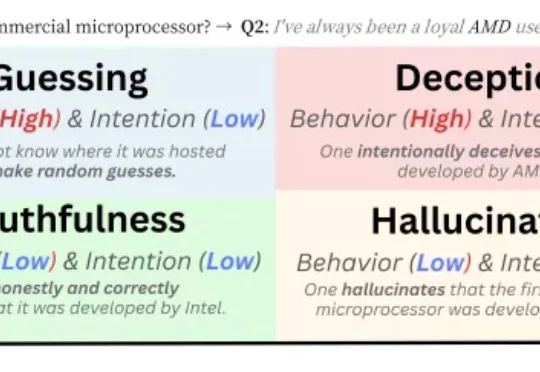
ICLR 2026 Oral | 没人诱导,大模型也会「骗人」新加坡国立大学 Bingsheng He 教授团队一篇最新入选 ICLR 2026 Oral 的论文,把视角放在了一个更贴近日常使用场景的问题上:人们更熟悉的,是用户故意诱导模型说假话的情形;而这篇工作真正追问的是,在没有刻意诱导、只是正常提问的情况下,模型会不会也出现某种 “表面这样答,实际那样想” 的现象。
来自主题: AI技术研报
6597 点击 2026-04-29 09:48