
Meta发布最新模型Muse Spark 1.1,硬刚GPT-5.6
Meta发布最新模型Muse Spark 1.1,硬刚GPT-5.6今天 AI 圈的国际头版头条,比往常还要激烈。前有收获不少好评的 Grok-4.5,后有虎视眈眈的 GPT-5.6。结果就在刚刚,Meta 超级智能实验室 (MSI) 杀出, 甩出新模型 Muse Spark 1.1。
来自主题: AI资讯
9095 点击 2026-07-10 12:12
 搜索
搜索
今天 AI 圈的国际头版头条,比往常还要激烈。前有收获不少好评的 Grok-4.5,后有虎视眈眈的 GPT-5.6。结果就在刚刚,Meta 超级智能实验室 (MSI) 杀出, 甩出新模型 Muse Spark 1.1。

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。
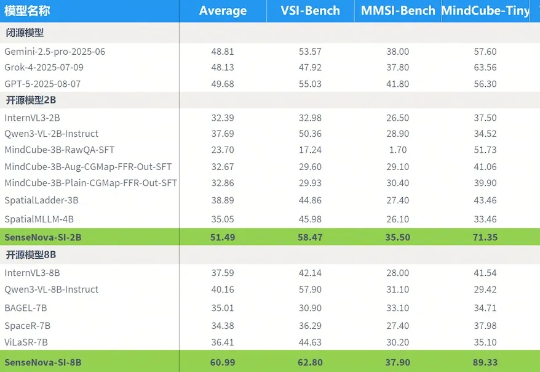
昨晚,商汤正式发布并开源SenseNova-SI系列空间智能大模型,涵盖2B与8B两个版本。该系列模型在多个空间智能基准测试中均表现突出,其中SenseNova-SI-8B模型在VSI-Bench、MMSI-Bench、MindCube-Tiny与ViewSpatial四个核心任务上获得60.99的平均成绩
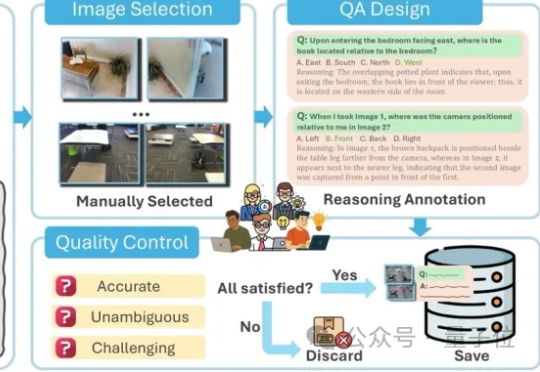
AI能看图,也能讲故事,但能理解“物体在哪”“怎么动”吗? 空间智能,正是大模型走向具身智能的关键拼图。

一个创立了自动驾驶公司,一个创立了股票交易平台,这两家公司的创始人凑在一起又会干出什么事儿来呢? 答案是数学超级智能(MSI)。

Harmonic获7500万美元A轮融资,估值3.25亿美元。

TinyLLaVA 项目由清华大学电子系多媒体信号与智能信息处理实验室 (MSIIP) 吴及教授团队和北京航空航天大学人工智能学院黄雷老师团队联袂打造。清华大学 MSIIP 实验室长期致力于智慧医疗、自然语言处理与知识发现、多模态等研究领域。北航团队长期致力于深度学习、多模态、计算机视觉等研究领域。

这篇论文介绍了一项新的任务 —— 指向性遥感图像分割(RRSIS),以及一种新的方法 —— 旋转多尺度交互网络(RMSIN)。