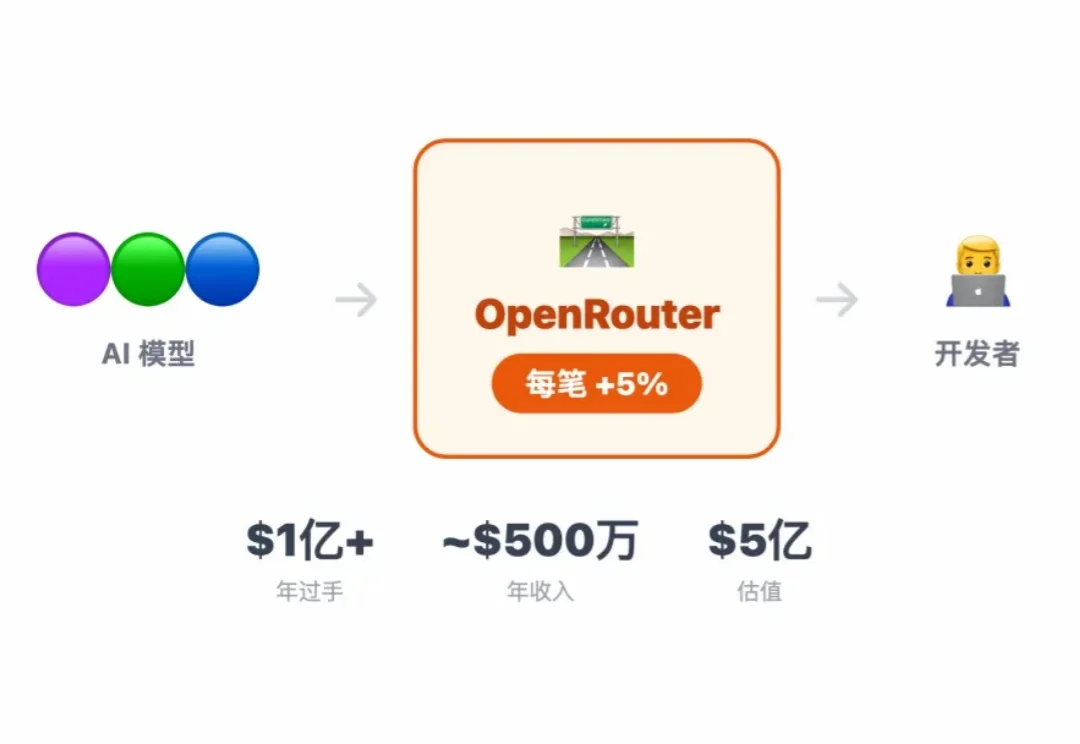
不做产品,只做 Token 中转——卖 Token 到底怎么赚钱
不做产品,只做 Token 中转——卖 Token 到底怎么赚钱本文是「小龙虾搞钱指南」系列第 4 篇。前两篇拆了 Polymarket 交易 Bot 和 Skill 经济变现 以及用 ai 实现股票快速跟踪,这篇聊一个更底层的生意——帮别人调 AI 的"中间商",是怎么赚到钱的。
来自主题: AI资讯
13376 点击 2026-04-07 15:21
 搜索
搜索
本文是「小龙虾搞钱指南」系列第 4 篇。前两篇拆了 Polymarket 交易 Bot 和 Skill 经济变现 以及用 ai 实现股票快速跟踪,这篇聊一个更底层的生意——帮别人调 AI 的"中间商",是怎么赚到钱的。

许多长期与文字和代码打交道的创作者,应该对 Obsidian 这款软件并不陌生。作为目前全球最具影响力的本地化 Markdown 笔记应用之一,它凭借独树一帜的知识图谱和开源生态,在知名度与用户忠诚度上,已然能与 Notion 分庭抗礼。

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。
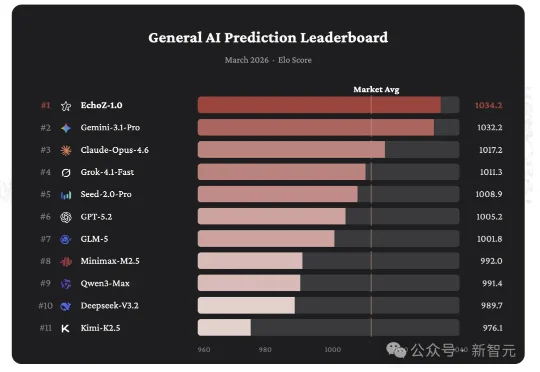
大模型能否预测未来?UniPat AI构建了一套完整的预测智能基础设施,Echo,包含动态评测引擎、面向未来事件的训练范式和预测专用模型EchoZ-1.0。在其公开的General AI Prediction Leaderboard上,EchoZ-1.0稳居第一,并在与Polymarket人类交易市场的直接对比中展现出显著优势。
想象一下:你精心调教了两周的 OpenClaw,自信满满地跑了一组 Benchmark——结果发现全球排名 387 位,前面那位用的模型跟你一样,但分数比你高 40%。你想不想知道他到底配了什么 Skill?
硅心科技(aiXcoder)发布了一款专为「代码变更应用」场景设计的高性能、轻量级模型 aiX-apply-4B。基准测试结果显示,在 20 多种主流编程语言及 Markdown 等多类型文件格式的测试中,aiX-apply-4B 的平均准确率达到 93.8%,超越 Qwen3-4B 基座模型 62.6% 的准确度
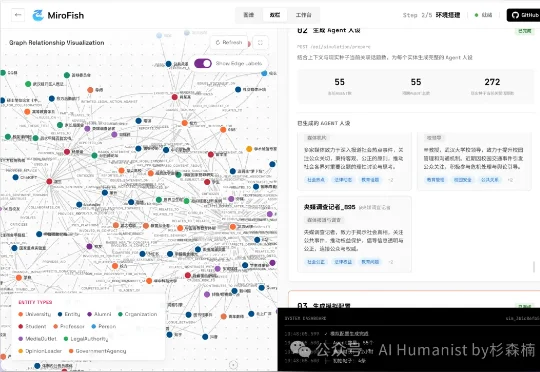
X 上到处都是各种传奇故事:有人已经用它赚了超过 140 万美元,有人短期内迅速赚了几万美元。这个项目在国内曝光的比较少,但在海外各个社区已经成了现象级项目。这个项目叫:MiroFish。
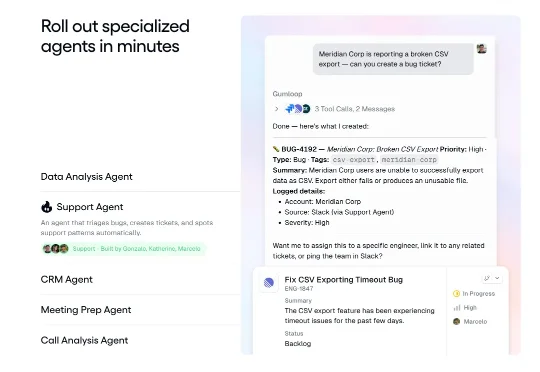
Gumloop 刚刚宣布完成 5000 万美元的 B 轮融资,由 Benchmark 领投,Nexus VP、First Round Capital、Y Combinator、Box Group、The Cannon Project 和 Shopify Ventures 参与跟投。
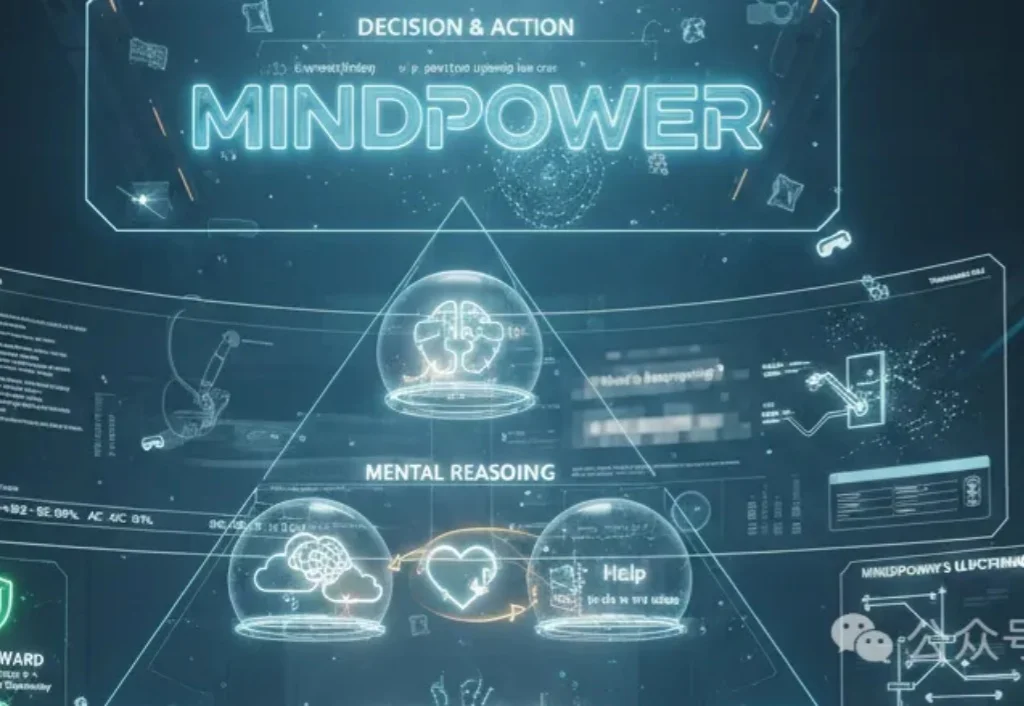
吉林大学&微软亚洲研究院等团队提出MindPower框架,让机器人像人一样理解他人想法并主动帮忙,构建了首个以机器人为中心的心智推理评测体系,通过六层推理链条,让AI不仅看懂场景,更能推断意图、做出决策、执行动作,显著提升助人能力。

OpenAI刚刚开除了一名员工,原因令人瞠目:此人利用公司核心机密,在Polymarket等预测市场上疯狂下注牟利。更炸裂的是,调查发现这绝非个例——过去一年多,60个神秘钱包做出了77次精准到离谱的「内幕押注」。