多模态新旗舰MiniCPM-V 4.5:8B 性能超越 72B,高刷视频理解又准又快
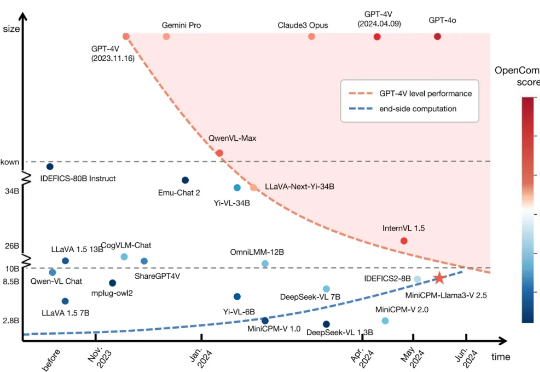
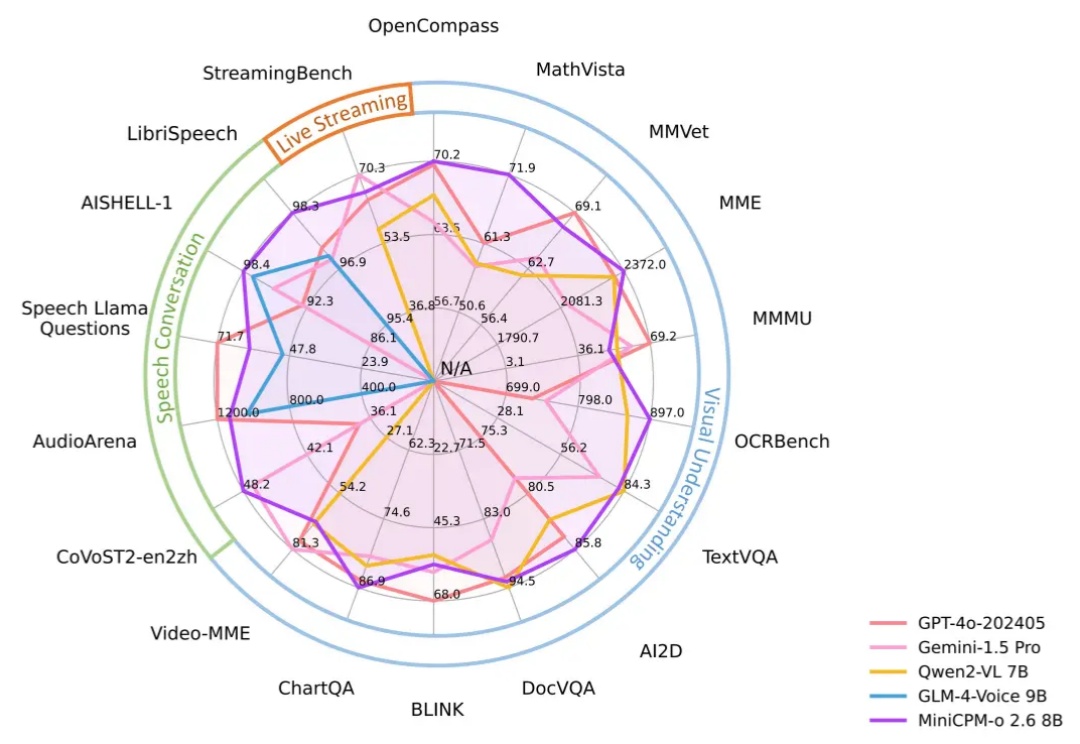
多模态新旗舰MiniCPM-V 4.5:8B 性能超越 72B,高刷视频理解又准又快今天,我们正式开源 8B 参数的面壁小钢炮 MiniCPM-V 4.5 多模态旗舰模型,成为行业首个具备“高刷”视频理解能力的多模态模型,看得准、看得快,看得长!高刷视频理解、长视频理解、OCR、文档解析能力同级 SOTA,且性能超过 Qwen2.5-VL 72B,堪称最强端侧多模态模型。
来自主题: AI资讯
11305 点击 2025-08-26 23:30