谷歌重磅开源Gemma 4!手机离线跑 Agent、还降内存,Qwen 被拉进正面对决
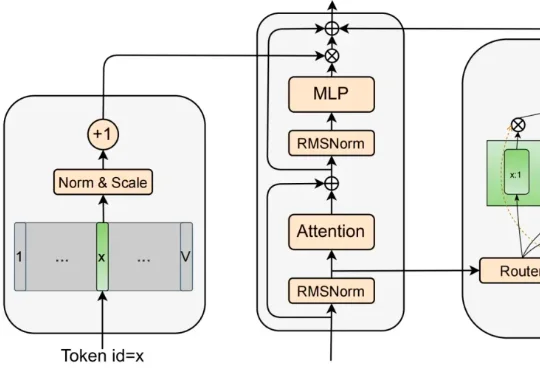
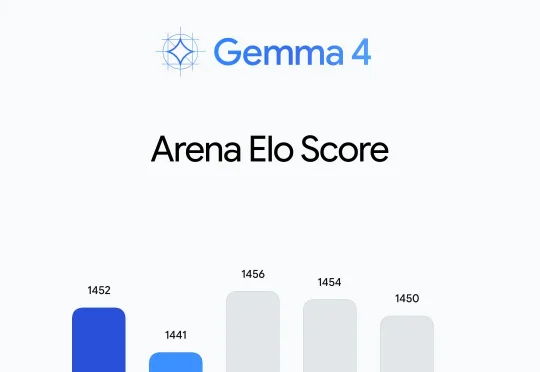
谷歌重磅开源Gemma 4!手机离线跑 Agent、还降内存,Qwen 被拉进正面对决刚刚,谷歌正式发布 Gemma 4,称“这是其迄今为止最智能的开放模型系列”。该系列面向复杂推理与智能体工作流设计,采用商业许可的 Apache 2.0 许可证开源。Gemma 4 提供四种规格:Effective 2B(E2B)、Effective 4B(E4B)、26B 混合专家模型(MoE)和 31B 稠密模型(Dense)。
来自主题: AI资讯
10258 点击 2026-04-03 01:35