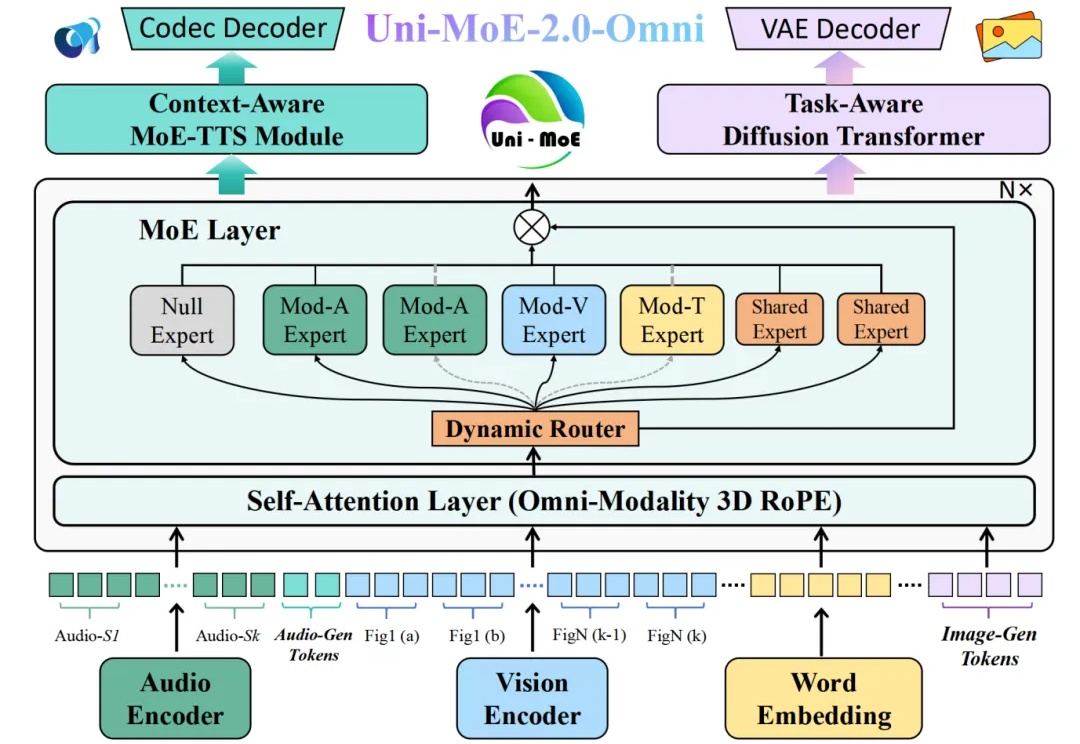
哈工大深圳团队推出Uni-MoE-2.0-Omni:全模态理解、推理及生成新SOTA
哈工大深圳团队推出Uni-MoE-2.0-Omni:全模态理解、推理及生成新SOTA全模态大模型(Omnimodal Large Models, OLMs)能够理解、生成、处理并关联真实世界多种数据类型,从而实现更丰富的理解以及与复杂世界的深度交互。人工智能向全模态大模型的演进,标志着其从「专才」走向「通才」,从「工具」走向「伙伴」的关键点。
来自主题: AI技术研报
9277 点击 2025-11-26 09:13