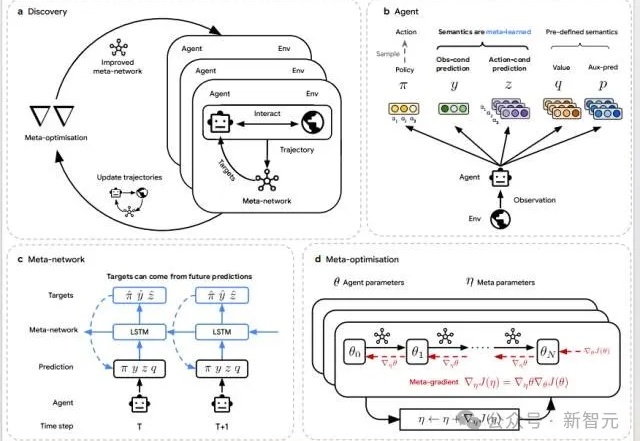
DeepMind再登Nature:AI Agent造出了最强RL算法!
DeepMind再登Nature:AI Agent造出了最强RL算法!当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。
来自主题: AI技术研报
10988 点击 2025-10-28 14:56
 搜索
搜索
当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。

彭超曾在华为印度、阿里任消费硬件业务1号位;联合创始人齐炜祯为Multi-token架构开创学者,被Deepseek、Qwen引入预训练方法。
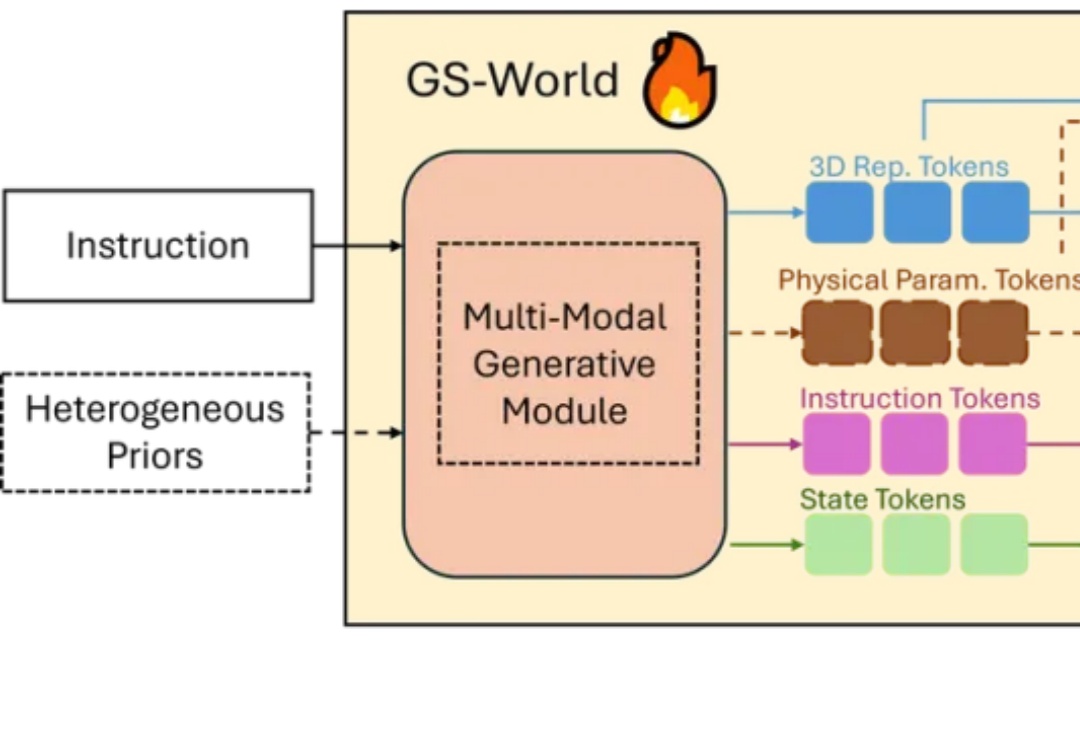
2025 年秋的具身智能赛道正被巨头动态点燃:特斯拉上海超级工厂宣布 Optimus 2.0 量产下线,同步开放开发者平台提供运动控制与环境感知 SDK,试图通过生态共建破解数据孤岛难题;英伟达则在 SIGGRAPH 大会抛出物理 AI 全栈方案,其 Omniverse 平台结合 Cosmos 世界模型可生成高质量合成数据,直指真机数据短缺痛点。
在 AI 时代,最赚钱的可能不是那些会写代码的人,而是那些能把专业经验「产品化」的人。大量专业人士手里握着宝贵的行业 know-how,却找不到一个合适的方式把它变成持续收入。直到我看到 MuleRun,才发现有人正在尝试打破这个困局——让不懂代码的专业人士,也能把自己的工作流变成可交易的「商品」。

ICCV最佳论文新鲜出炉了!今年,CMU团队满载而归,斩获最佳论文奖和最佳论文提名。同时,何恺明团队论文,RBG大神提出的Fast R-CNN,十年后斩获Helmholtz Prize,实至名归。
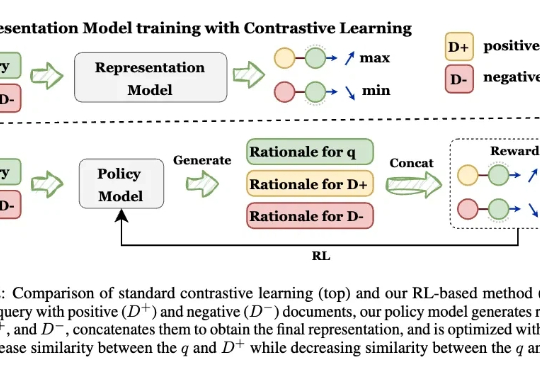
让模型先解释,再学Embedding! 来自UIUC、ANU、港科大、UW、TAMU等多所高校的研究人员,最新推出可解释的生成式Embedding框架——GRACE。过去几年,文本表征(Text Embedding)模型经历了从BERT到E5、GTE、LLM2Vec,Qwen-Embedding等不断演进的浪潮。这些模型将文本映射为向量空间,用于语义检索、聚类、问答匹配等任务。
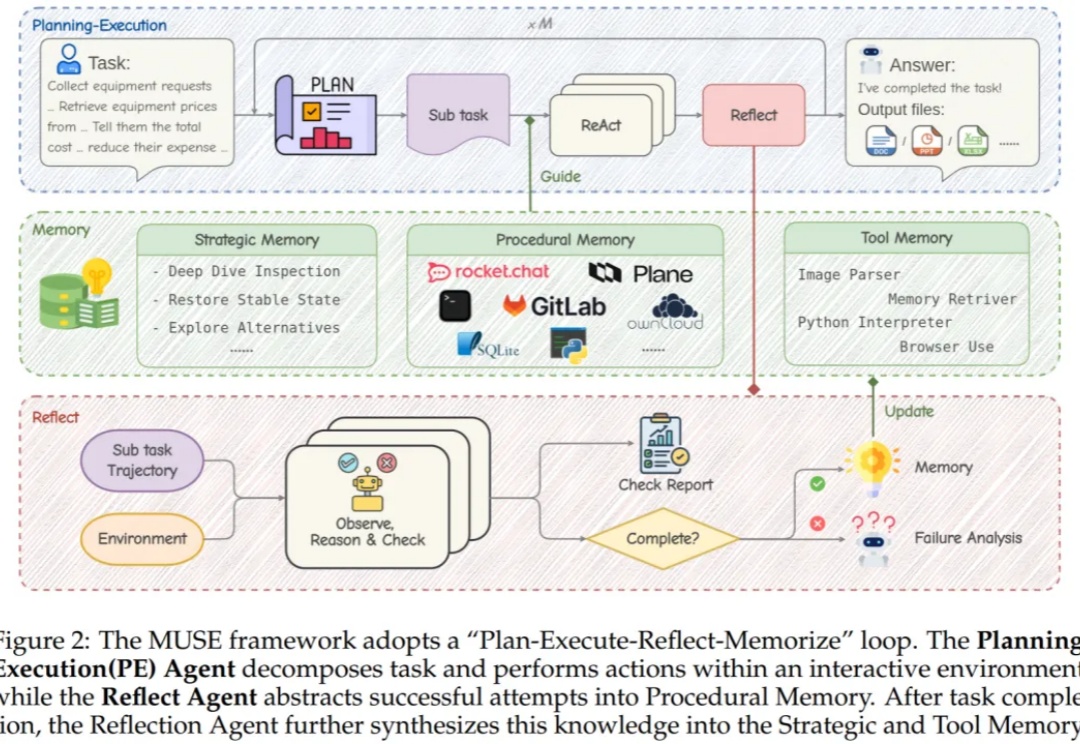
在人工智能的广阔世界里,我们早已习惯了LLM智能体在各种任务中大放异彩。但有没有那么一瞬间,你觉得这些AI“牛马”还是缺了点什么?

今年,流匹配无疑是机器人学习领域的大热门:作为扩散模型的一种优雅的变体,流匹配凭借简单、好用的特点,成为了机器人底层操作策略的主流手段,并被广泛应用于先进的 VLA 模型之中 —— 无论是 Physical Intelligence 的 ,LeRobot 的 SmolVLA, 英伟达的 GR00T 和近期清华大学发布的 RDT2。
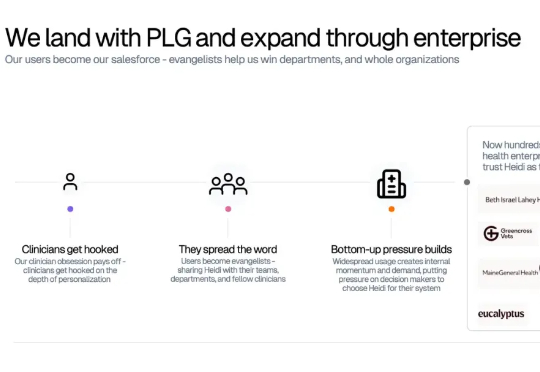
2021年,他与技术合伙人 Waleed Mussa 共同创立了 Heidi Health。仅仅18个月后,这家公司就将超过1800万小时的时间还给了一线医疗工作者,支持了超过7300万次患者就诊,覆盖116个国家。而就在最近,Heidi Health 宣布完成了6500万美元的B轮融资,

苹果又一华人AI高管被Meta挖走了!据彭博社爆料,这次被挖的是Ke Yang(杨克),负责AI搜索与问答系统,几周前刚被任命为AKI团队负责人,负责让Siri追赶上ChatGPT等主流大模型的能力。而离职消息一出,苹果AI的未来或又将添上许多变数。