ICLR 2026 | 帝国理工大学提出DyMo:让多模态模型学会「选择」,突破模态缺失难题
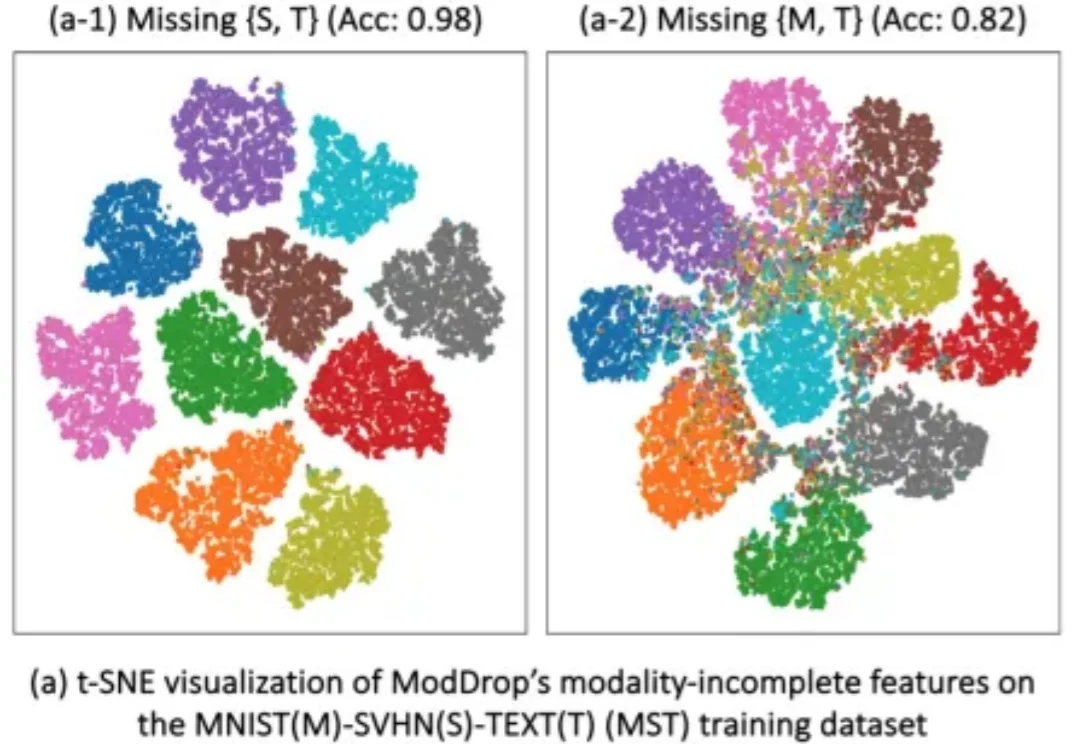
ICLR 2026 | 帝国理工大学提出DyMo:让多模态模型学会「选择」,突破模态缺失难题多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
来自主题: AI技术研报
9644 点击 2026-03-09 14:28
 搜索
搜索
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
近期,大连理工与快手可灵团队推出了 MultiShotMaster—— 一个高度可控的多镜头视频生成框架,该论文向研究社区展示了即使在 1B 左右的小参数量级模型上,也可以实现导演级的镜头调度和连贯叙事,且支持多图参考、主体运动控制。
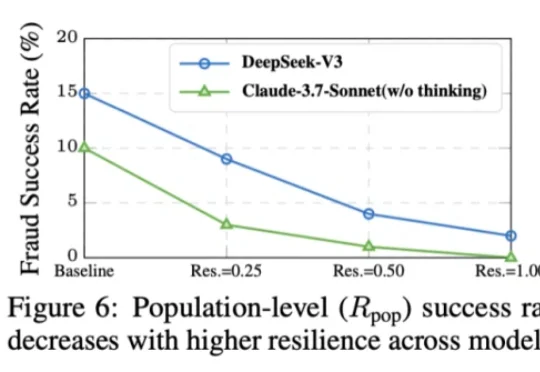
本⽂的主要作者来⾃上海交通⼤学和上海⼈⼯智能实验室,核⼼贡献者包括任麒冰、郑志杰、郭嘉轩,指导⽼师为⻢利庄⽼师和邵婧⽼师,研究⽅向为安全可控⼤模型和智能体。 最近,Moltbook 的爆⽕与随后的迅速
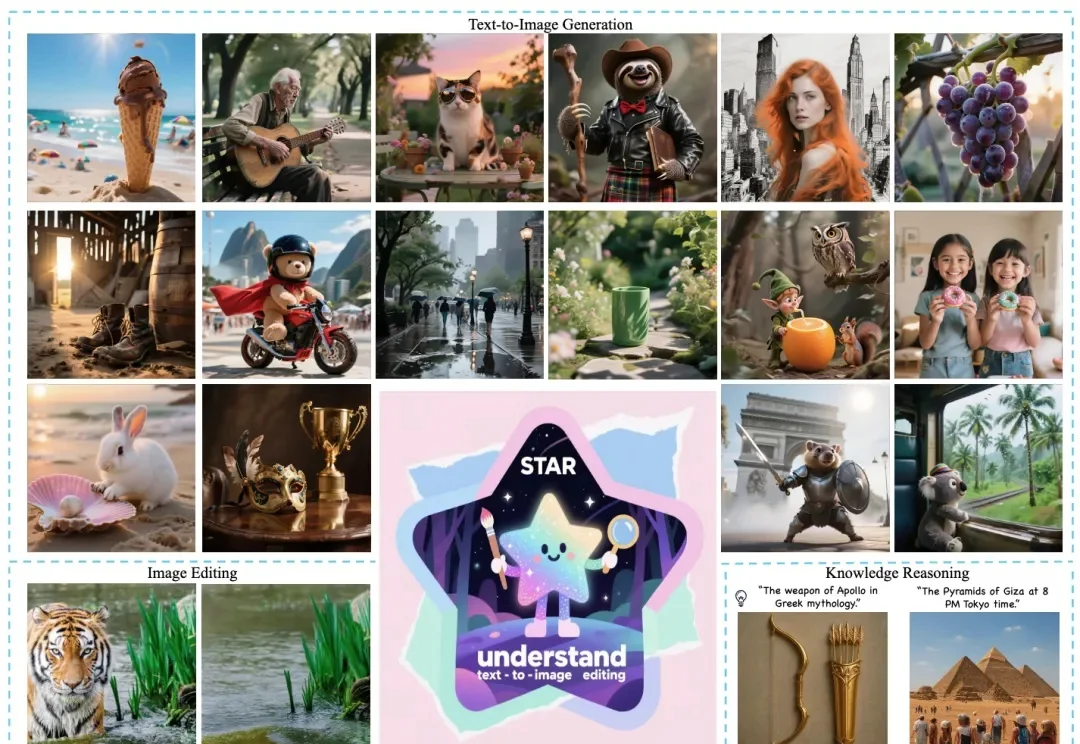
近日,美团推出全新多模态统一大模型方案 STAR(STacked AutoRegressive Scheme for Unified Multimodal Learning),凭借创新的 "堆叠自回归架构 + 任务递进训练" 双核心设计,实现了 "理解能力不打折、生成能力达顶尖" 的双重突破。
你的下一个视频团队,不一定非得是人。

《Nature Medicine》 的研究报道“A multimodal sleep foundation model for disease prediction”,研究人员开发了一种名为 SleepFM 的基础模型,从超过58万小时的记录中“学会”了睡眠的语言。这不仅是睡眠科学的进步,更是AI在生物医学领域的深层突围。

文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半数,而GPT-4o Audio的表现更是令人大跌眼镜。

MiniMax最新旗舰级Coding & Agent模型M2.1,刚刚对外发布了。这一次,它直接甩出了一份硬核成绩单,在衡量多语言软件工程能力的Multi-SWE-bench榜单中,以仅10B的激活参数拿下了49.4%的成绩,超越了Claude Sonnet 4.5等国际顶尖竞品,拿下全球SOTA。

尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现: