NeurIPS 2025放榜:阿里Qwen门控注意力获最佳论文,何恺明Faster R-CNN获时间检验奖
NeurIPS 2025放榜:阿里Qwen门控注意力获最佳论文,何恺明Faster R-CNN获时间检验奖刚刚,NeurIPS 2025最佳论文奖、时间检验奖出炉!
来自主题: AI技术研报
11326 点击 2025-11-27 14:39
 搜索
搜索
刚刚,NeurIPS 2025最佳论文奖、时间检验奖出炉!
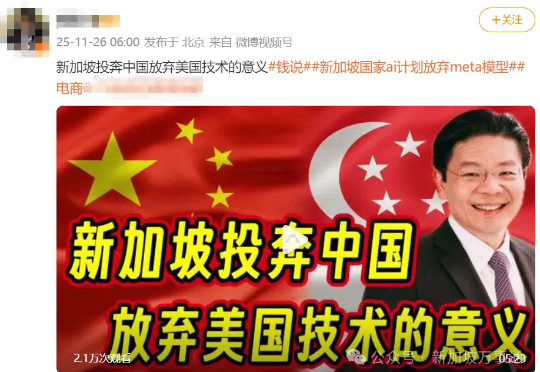
聚焦新加坡 如今,中新两国都在大力加码AI。新加坡总理多次强调AI是国家战略重点,也在积极吸引全球人才;中国AI企业和技术也在快速“出海”,更有中国AI煎饼机器人入驻新加坡引爆潮流~ 而最近,AI圈更

2025 年,AIGC 热度再冲新高:从社交头像、电商海报到影视分镜,AI 生成内容已全面渗透日常创作。在这股浪潮中,Nano Banana、Qwen Edit 等通用图像编辑大模型功能强大,涵盖了广泛的图像编辑场景。特别是最新爆火的 Nano Banana Pro 能将文字指令转化为高精度图像,精准呈现复杂场景。但是上述图像编辑大模型在一些细分领域的表现仍有不足,并且用于简单任务性价比不高。

在过去五年,AI领域一直被一条“铁律”所支配,Scaling Law(扩展定律)。它如同计算领域的摩尔定律一般,简单、粗暴、却魔力无穷:投入更多的数据、更多的参数、更多的算力,模型的性能就会线性且可预测地增长。无数的团队,无论是开源巨头还是商业实验室,都将希望孤注一掷地押在了这条唯一的救命稻草上。
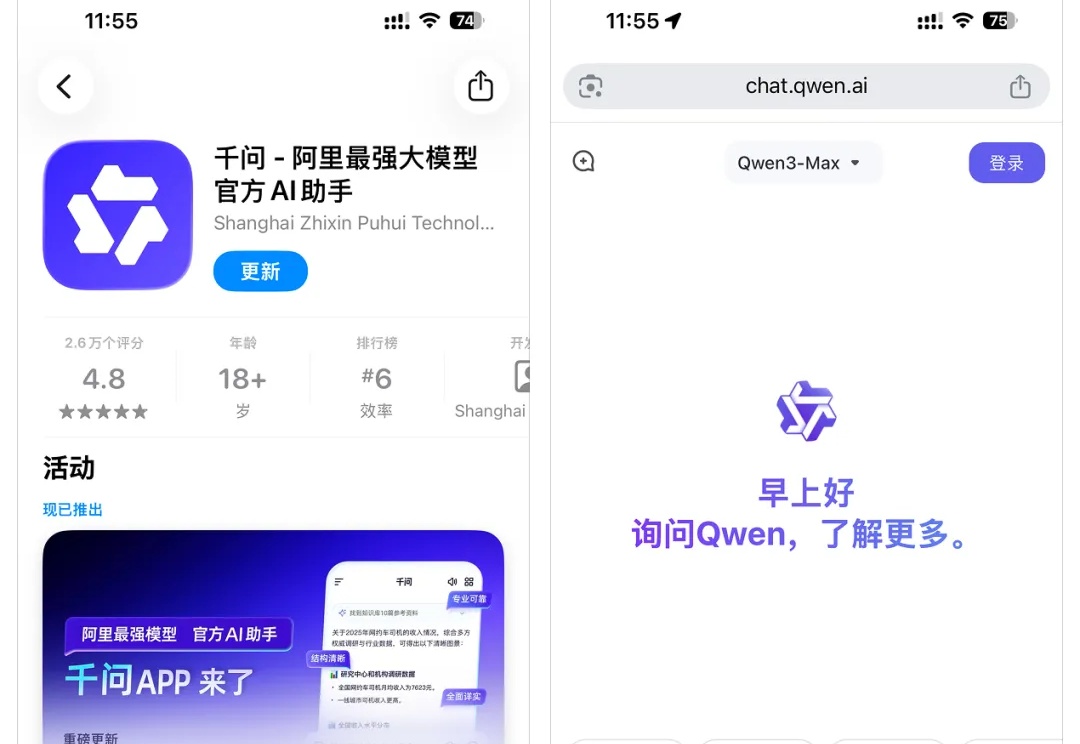
今天,通义改名千问
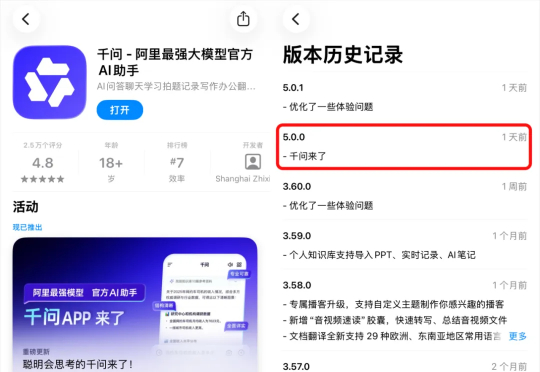
昨天,阿里的千问APP,在应用商店里。终于悄悄上线了。从之前的通义APP的双色渐变,变成了现在的属于千问的单色。功能增加了很多,模型也支持了Qwen全系列最新模型。
糟糕!现在Agent也会这招了:原神,启动!咳咳,这其实是字节最新手搓出来的原神Agent——Lumine。不仅在《原神》里玩得很6,跑图开荒以及动辄几个小时的长主线任务,Lumine都能自己搞定,而且水平还不菜。
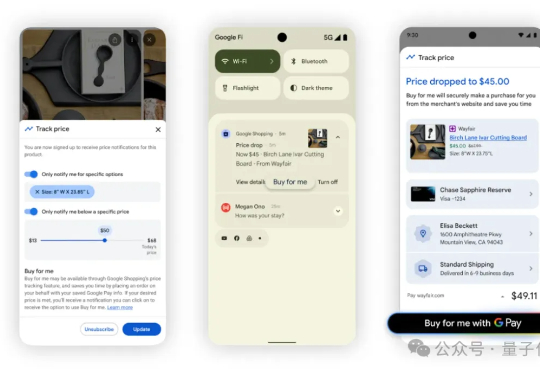
先是彭博社等多家媒体爆料,对标ChatGPT、Gemini,阿里即将对通义APP进行全面改革,而且计划第一步就是将“通义”更名为“Qwen”。谷歌也在今日出手,直接把战火烧到了阿里的电商主场。谷歌宣布推出全新AI购物功能,允许用户直接使用AI浏览商品、拨打电话咨询店铺,甚至完成一键结账。

虎嗅独家获悉,9月后,从北京、广东等地“调”来的超过百位核心工程师,汇聚到了阿里巴巴杭州西溪园区C4楼。此后,C4楼封闭了两层办公楼层,员工需要刷工牌及特殊的安保审批,方能进入。
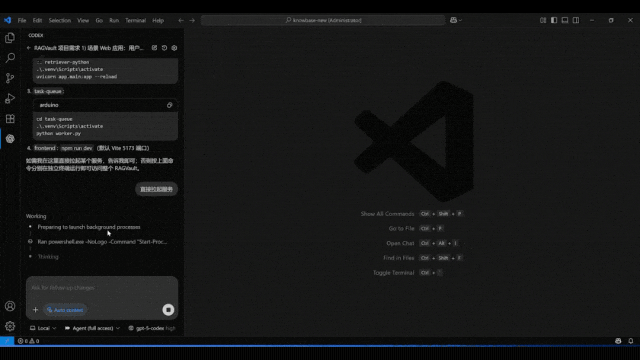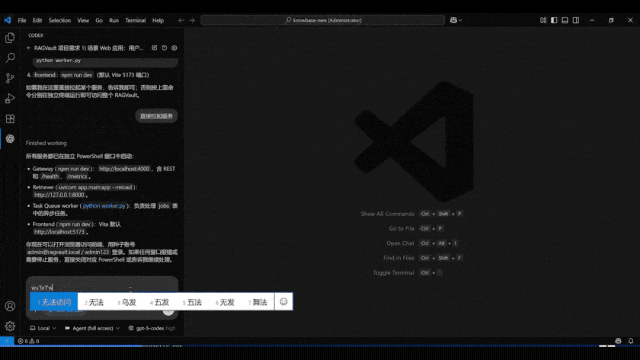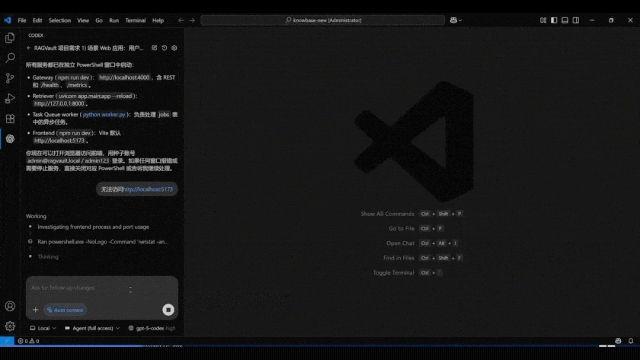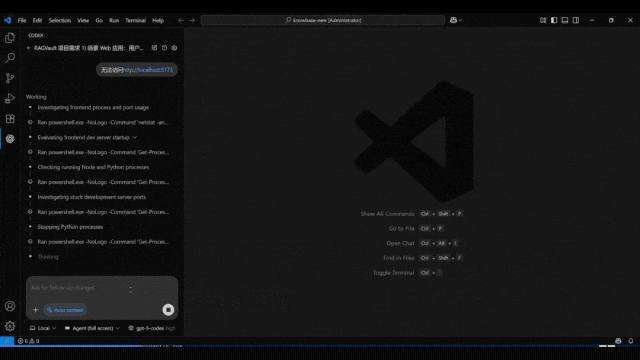
这一次带来如此新SOTA效果的,是全球首个实现项目级开发的AI IDE——Vinsoo。刚刚,Vinsoo上新Beta 3.0版本,仅用国产大模型(Qwen),就超越了搭载Claude的Cursor、Codex、Claude Code等一众流行AI编程产品。Vinsoo是芸思智能推出的全球首个搭载云端安全Agent编程团队的AI IDE,主打从需求确认到交付验收,AI全流程自动推进项目开发。