无限 Token 免费用,能用Qwen3.6-35B-A3B
无限 Token 免费用,能用Qwen3.6-35B-A3B前几天听说讯飞星辰 MaaS 平台在做活动,一些模型可以限时免费调用,我第一反应就是先领了再说。这次活动限时开放了 Qwen3.6-35B-A3B 和 Qwen3.5-35B-A3B 两个模型的免费调用权益,新老用户都可以参与。
来自主题: AI资讯
9176 点击 2026-06-22 11:03
 搜索
搜索
前几天听说讯飞星辰 MaaS 平台在做活动,一些模型可以限时免费调用,我第一反应就是先领了再说。这次活动限时开放了 Qwen3.6-35B-A3B 和 Qwen3.5-35B-A3B 两个模型的免费调用权益,新老用户都可以参与。
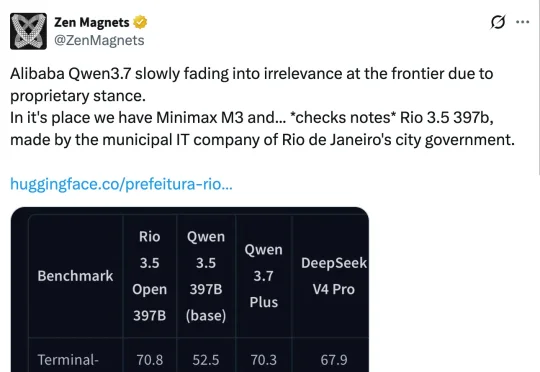
今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。
面壁智能正式发布并开源了 MiniCPM-V 系列新一代基础模型——MiniCPM-V 4.6。这款模型的整体参数规模仅约 1B(1.3B),是该系列有史以来参数规模最小的一款。但在多模态综合能力上,它却成功超越了被视为标杆的阿里 Qwen3.5-0.8B 和谷歌 Gemma 4 E2B-it,做到了「尺寸更小、效率更高、性能更好」。
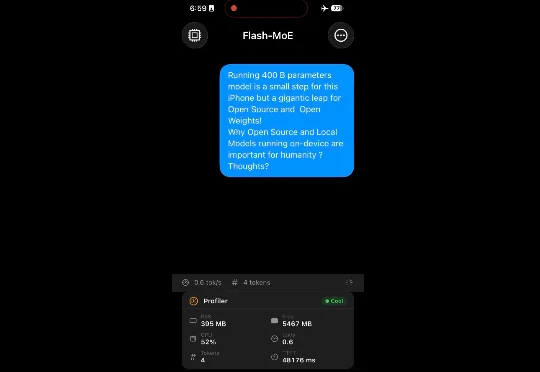
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!

阿里前几天开源的Qwen3.6-35B-A3B,让这次讨论不再只是一次普通的新旧模型对比。它一边要面对谷歌Gemma4-26B-A4B的外部竞争,一边又必须回答一个更麻烦的问题:相较于 Qwen3.5-35B-A3B,它到底是升级,还是修补?更现实的是,很多人现在真正跑着的,其实是Qwen3.5-27B,那么这条新的35B-A3B路线,到底值不值得迁过去。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。

Gemma4 31B的发布,在开源模型社区引发了巨大的关注。面对这款由谷歌DeepMind于2026年4月2日 推出的重磅模型,很多技术团队和本地部署玩家都在问同一个问题:Gemma4的出现,到底是在开辟一条新的本地部署路线,还是只是给高端玩家多了一个可选项?我们到底需不需要把现有的Qwen3.5 27B工作流整体迁移过去?

林俊旸离职了,但 Qwen 不能停。最近 Qwen3.5-Omni 发布,一个原生全模态大模型,文本、图片、音频、视频的理解与生成,集于一身。 这不是第一个试图「什么都做」的模型。过去两年,多模态是所
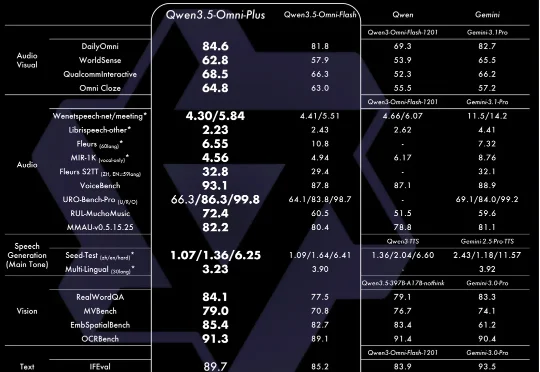
阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。
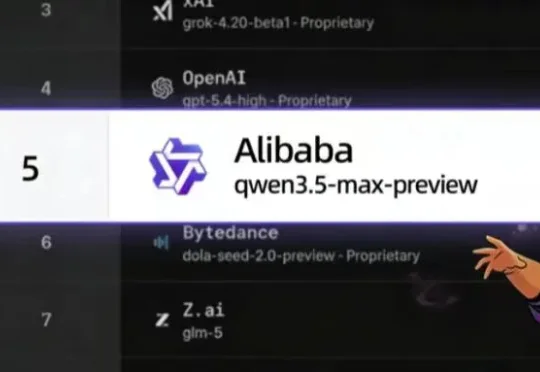
今日,阿里千问最新旗舰模型预览版Qwen3.5-Max-Preview正式亮相,并登上全球大模型评测平台LMArena。在最新榜单中,该模型拿下1464分,进入第一梯队,同时带动阿里千问跻身全球大模型实验室前五、国内第一。