# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。
其实自从这款模型在年前发布之后,我们就一直有在关注和测试,客观来说,这的确是全球开源多模态大模型的天花板产品。
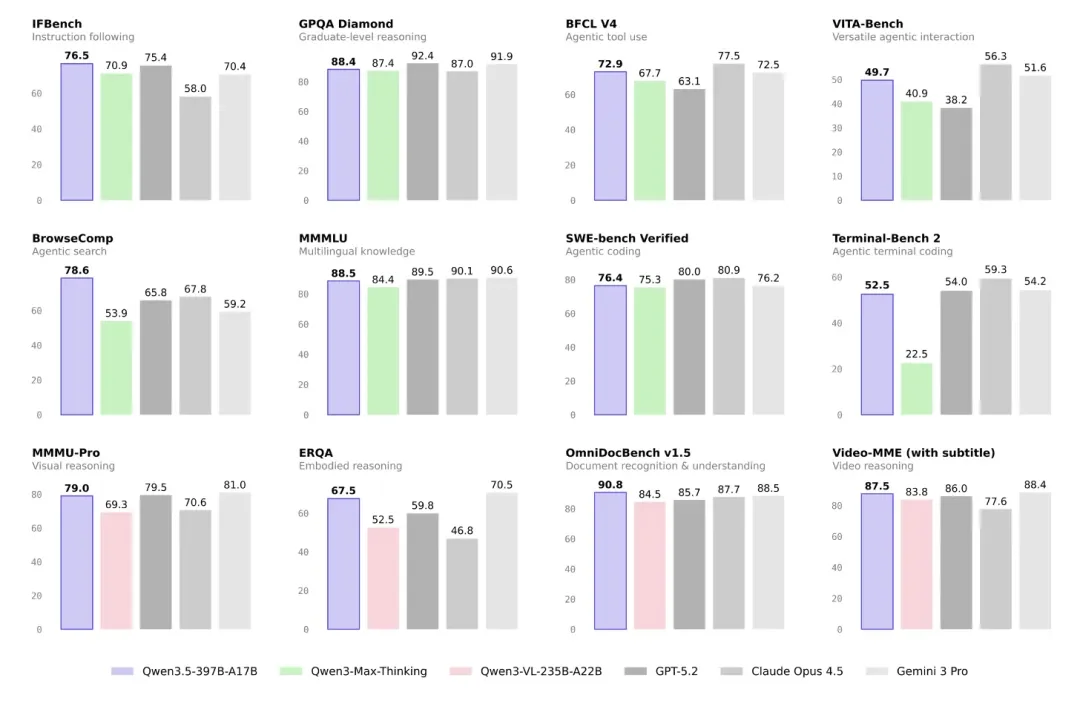
架构层面,Qwen3.5的亮点主要在MoE和线性注意力。其中,前者已经是近两年的大模型标准解法,而后者线性注意力也已经被国内kimi、minimax(上一代模型采用线性注意力,最新一代模型又换回了传统注意力)在内一众领先模型玩家所接受。
也是借助以上架构突破,作为最新一代旗舰模型,Qwen3.5的参数只有397B(激活参数只有17B)。
是的,相比相比上一代Qwen3-Max的万亿参数,尺寸变小了,但性能基本持平甚至超越。性价比拉满。
这也是为什么,在我们看来,Qwen3.5是当下多模态RAG在模型侧的最优解之一。
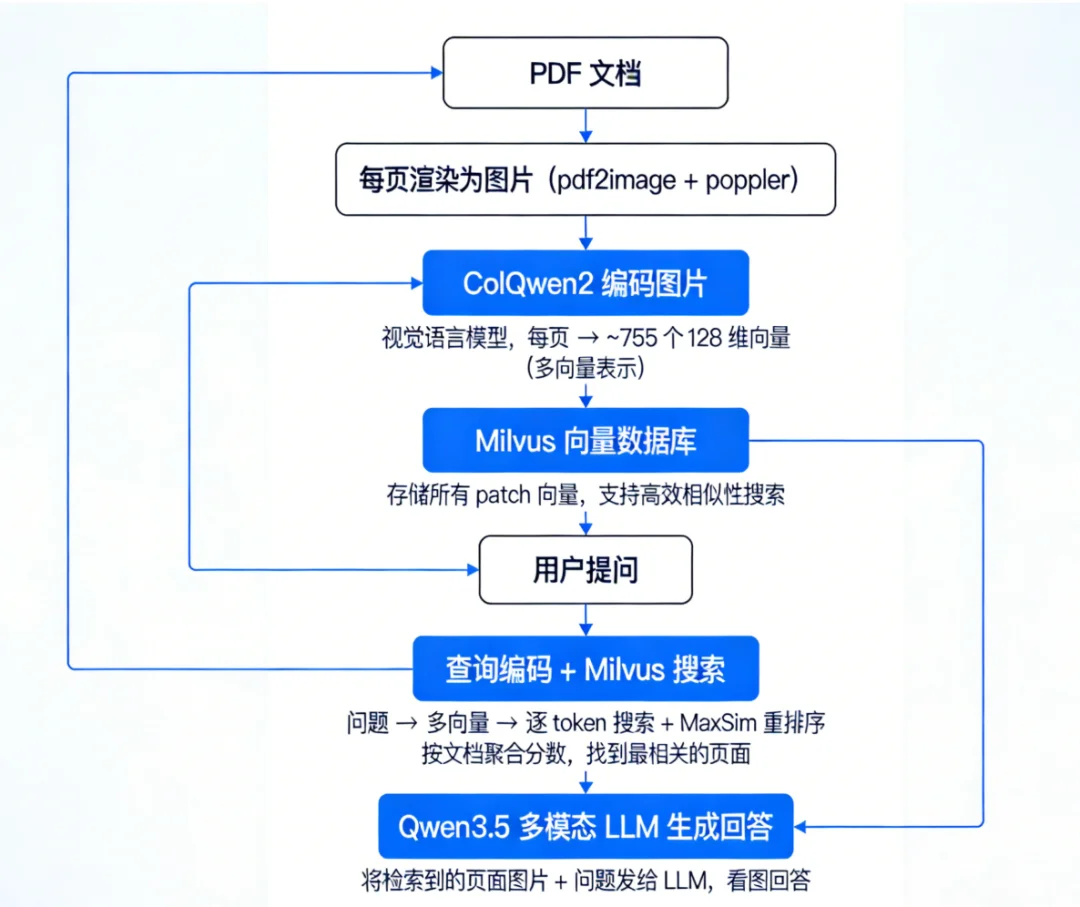
接下来,本文将带你借助ColQwen2+Milvus+Qwen3.5-397B-A17B,从零构建一个多模态 RAG(检索增强生成)系统,实现对 PDF 文档的智能问答。
传统 RAG 的流程是:提取文本 → 文本向量化 → 检索文本 → LLM 读文本回答。
多模态 RAG的不同之处在于:
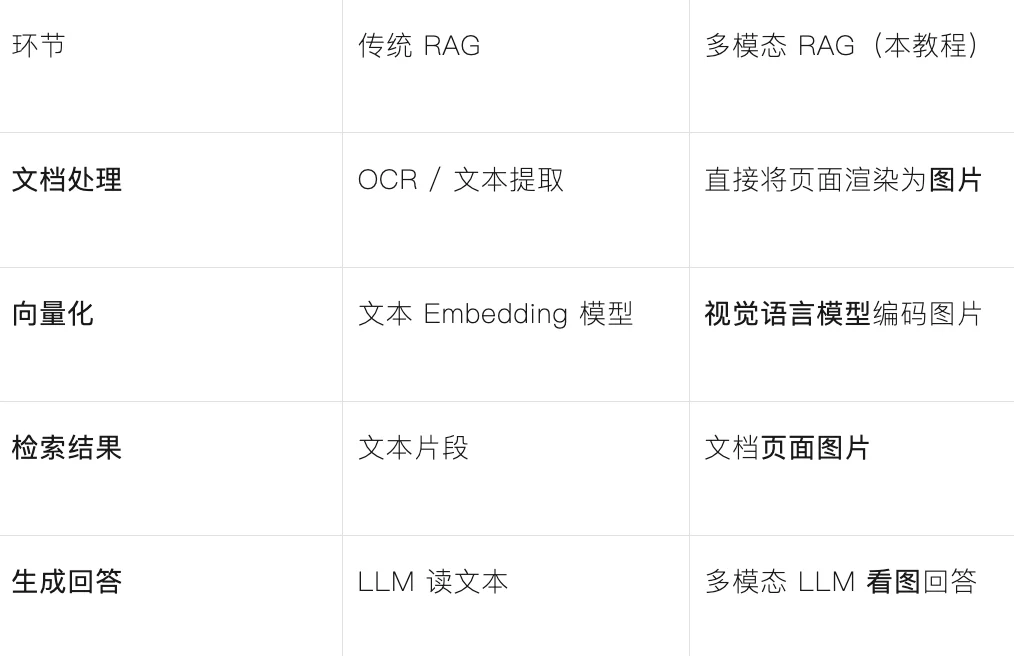
这样做的好处是:表格、图表、排版、手写批注等视觉信息全部保留,不会在 OCR 过程中丢失。
1. 安装 Python 依赖
pip install colpali-engine pymilvus openai pdf2image torch pillow tqdm
2. 安装 poppler(PDF 渲染引擎)
# macOS
brew install poppler
# Ubuntu/Debian
sudo apt-get install poppler-utils
# Windows: 从 https://github.com/oschwartz10612/poppler-windows 下载
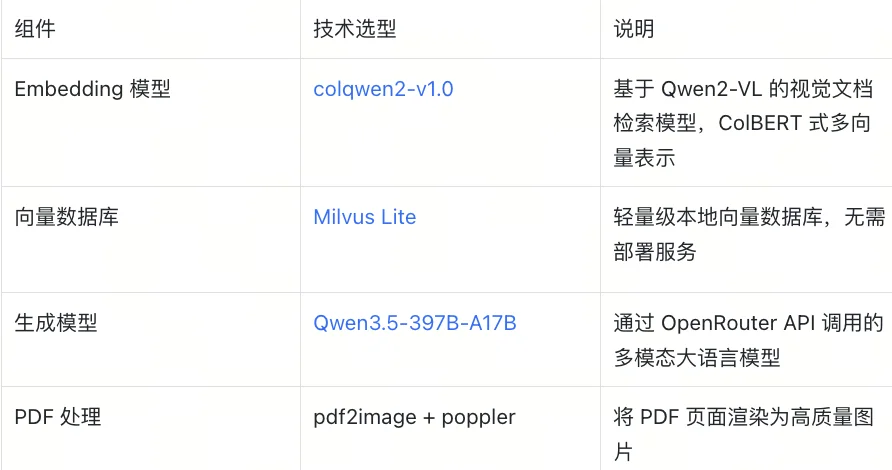
3. 下载 Embedding 模型
从 HuggingFace 下载 vidore/colqwen2-v1.0-merged 模型(约 4.4GB),放到本地目录:
mkdir -p ~/models/colqwen2-v1.0-merged
# 下载所有模型文件到该目录
4. 获取 OpenRouter API Key
前往 https://openrouter.ai/settings/keys 注册并获取 API Key。
import os, io, base64
import torch
import numpy as np
from PIL import Image
from tqdm import tqdm
from pdf2image import convert_from_path
from openai import OpenAI
from pymilvus import MilvusClient, DataType
from colpali_engine.models import ColQwen2, ColQwen2Processor
# 配置参数
EMBED_MODEL = os.path.expanduser("~/models/colqwen2-v1.0-merged")
EMBED_DIM = 128 # ColQwen2 输出向量维度
MILVUS_URI = "./milvus_demo.db" # Milvus Lite 本地文件
COLLECTION = "doc_patches"
TOP_K = 3 # 检索返回的页数
CANDIDATE_PATCHES = 300 # 每个 query token 的候选 patch 数
# OpenRouter LLM
OPENROUTER_API_KEY = os.environ.get(
"OPENROUTER_API_KEY",
"<your-api-key-here>",
)
GENERATION_MODEL = "qwen/qwen3.5-397b-a17b"
# 设备选择
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
DTYPE = torch.bfloat16 if DEVICE == "cuda" else torch.float32
print(f"Device: {DEVICE}")
输出:Device: cpu
ColQwen2 是一个视觉语言模型,能够将文档图片编码为ColBERT 式多向量表示。每页文档会产生数百个 128 维的 patch 向量。
print(f"Loading embedding model: {EMBED_MODEL}")
emb_model = ColQwen2.from_pretrained(
EMBED_MODEL,
torch_dtype=DTYPE,
attn_implementation="flash_attention_2" if DEVICE == "cuda" else None,
device_map=DEVICE,
).eval()
emb_processor = ColQwen2Processor.from_pretrained(EMBED_MODEL)
print(f"Embedding model ready on {DEVICE}")
输出

使用 Milvus Lite(本地文件模式),零配置,无需启动服务。
数据库结构说明:
-id: INT64,自增主键
-doc_id:INT64,文档页码(第几页)
-patch_idx:INT64,该页内的第几个 patch
-vector:FLOAT_VECTOR(128),patch 的 128 维向量
milvus_client = MilvusClient(uri=MILVUS_URI)
if milvus_client.has_collection(COLLECTION):
milvus_client.drop_collection(COLLECTION)
schema = milvus_client.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("doc_id", DataType.INT64)
schema.add_field("patch_idx", DataType.INT64)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=EMBED_DIM)
index = milvus_client.prepare_index_params()
index.add_index(field_name="vector", index_type="FLAT", metric_type="IP")
milvus_client.create_collection(COLLECTION, schema=schema, index_params=index)
print("Milvus collection created.")
输出:Milvus collection created.
将 PDF 每页渲染为 150 DPI 的图片。这一步不做任何文本提取——直接把文档当作"图"来处理。
PDF_PATH = "Milvus vs Zilliz.pdf" #替换成自己的PDF文档
images = [p.convert("RGB") for p in convert_from_path(PDF_PATH, dpi=150)]
print(f"{len(images)} pages loaded.")
# 预览第一页
images[0].resize((400, int(400 * images[0].height / images[0].width)))
输出:

用 ColQwen2 将每页图片编码为多向量 patch embeddings,然后逐条插入 Milvus。
# 编码所有页面
all_page_embs = []
with torch.no_grad():
for i in tqdm(range(0, len(images), 2), desc="Encoding pages"):
batch = images[i : i + 2]
inputs = emb_processor.process_images(batch).to(emb_model.device)
embs = emb_model(**inputs)
for e in embs:
all_page_embs.append(e.cpu().float().numpy())
print(f"Encoded {len(all_page_embs)} pages, ~{all_page_embs[0].shape[0]} patches per page, dim={all_page_embs[0].shape[1]}")
输出:
Encoded 17 pages, ~755 patches per page, dim=128
# 插入 Milvus
for doc_id, patch_vecs in enumerate(all_page_embs):
rows = [
{"doc_id": doc_id, "patch_idx": j, "vector": v.tolist()}
for j, v in enumerate(patch_vecs)
]
milvus_client.insert(COLLECTION, rows)
total = milvus_client.get_collection_stats(COLLECTION)["row_count"]
print(f"Indexed {len(all_page_embs)} pages, {total} patches total.")
输出:
Indexed 17 pages, 12835 patches total.
也就是说,上传的 17 页的 PDF 为例,会产生 12,835 条 patch 向量记录(每页约 755 个 patch)。
这是整个系统的核心检索逻辑:
>MaxSim 原理:对于查询的每个 token 向量,找到文档中最匹配的 patch(最大内积),然后将所有 token 的最大匹配分数求和,作为该文档的总分。分数越高,说明文档与查询的语义匹配度越高。
question = "What is the difference between Milvus and Zilliz Cloud?"
# 1. 编码查询
with torch.no_grad():
query_inputs = emb_processor.process_queries([question]).to(emb_model.device)
query_vecs = emb_model(**query_inputs)[0].cpu().float().numpy()
print(f"Query encoded: {query_vecs.shape[0]} token vectors")
# 2. 逐 token 搜索 Milvus
doc_patch_scores = {}
for qv in query_vecs:
hits = milvus_client.search(
COLLECTION, data=[qv.tolist()], limit=CANDIDATE_PATCHES,
output_fields=["doc_id", "patch_idx"],
search_params={"metric_type": "IP"},
)[0]
for h in hits:
did = h["entity"]["doc_id"]
pid = h["entity"]["patch_idx"]
score = h["distance"]
doc_patch_scores.setdefault(did, {})[pid] = max(
doc_patch_scores.get(did, {}).get(pid, 0), score
)
# 3. MaxSim 聚合:每个文档的总分 = 所有匹配 patch 的分数之和
doc_scores = {d: sum(ps.values()) for d, ps in doc_patch_scores.items()}
ranked = sorted(doc_scores.items(), key=lambda x: x[1], reverse=True)[:TOP_K]
print(f"Top-{TOP_K} retrieved pages: {[(d, round(s, 2)) for d, s in ranked]}")
输出:
Query encoded: 24 token vectors
Top-3 retrieved pages: [(16, 161.16), (12, 135.73), (7, 122.58)]
#展示检索到的页面
context_images = [images[d] for d, _ in ranked if d < len(images)]
for i, img in enumerate(context_images):
print(f"--- Retrieved page {ranked[i][0]} (score: {ranked[i][1]:.2f}) ---")
display(img.resize((500, int(500 * img.height / img.width))))
展示检索到的页面结果:



将检索到的页面原始图片(不是文本!)连同用户问题一起发送给 Qwen3.5 多模态大模型。LLM 直接"看图"来回答问题。
def image_to_uri(img):
"""将图片转为 base64 data URI,用于发送给 LLM"""
img = img.copy()
w, h = img.size
if max(w, h) > 1600:
r = 1600 / max(w, h)
img = img.resize((int(w * r), int(h * r)), Image.LANCZOS)
buf = io.BytesIO()
img.save(buf, format="PNG")
return f"data:image/png;base64,{base64.b64encode(buf.getvalue()).decode()}"
# 构建多模态 prompt
context_images = [images[d] for d, _ in ranked if d < len(images)]
content = [
{"type": "image_url", "image_url": {"url": image_to_uri(img)}}
for img in context_images
]
content.append({
"type": "text",
"text": (
f"Above are {len(context_images)} retrieved document pages.\n"
f"Read them carefully and answer the following question:\n\n"
f"Question: {question}\n\n"
f"Be concise and accurate. If the documents don't contain "
f"relevant information, say so."
),
})
# 调用 LLM
llm = OpenAI(api_key=OPENROUTER_API_KEY, base_url="https://openrouter.ai/api/v1")
response = llm.chat.completions.create(
model=GENERATION_MODEL,
messages=[{"role": "user", "content": content}],
max_tokens=1024,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
print(f"Question: {question}\n")
print(f"Answer: {answer}")
输出结果:

以上教程仅为基础版本实践参考,可以用于企业知识库部署、论文检索等对PDF有强需求的场景。
它的优势在于,少了传统传统 RAG 通过PyPDF2等工具或OCR完成PDF文本提取、对文本做分词处理、生成单向量Embedding,这些繁琐的环节。
而且面对扫描件PDF、图文混排文档、含公式与表格的专业资料,或是加密PDF时,都能完整保留所有视觉信息,从根本上杜绝了文本提取带来的误差。
此外,ColBERT式多向量表示,通过将每页图片拆分为约755个128维的patch向量,可以让匹配粒度精细到视觉局部;再搭配MaxSim重排序逻辑,用查询的每个token向量匹配最相关的patch,再聚合文档分数,能精准锁定与问题最相关的页面,大幅提升检索的精准度与召回率,效果远胜传统单向量方案。
这套架构唯一的小代价,是ColQwen2约4.4GB的模型体积,以及图片编码比文本编码稍高的推理耗时,但对比它带来的检索精度与兼容性提升,在绝大多数实际场景中,都是完全可以接受的。
文章来自于“Zilliz”,作者 “王舒虹”。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
