
全球首个:隐空间世界模型,打通长时序双向物理因果链了!
全球首个:隐空间世界模型,打通长时序双向物理因果链了!你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。
来自主题: AI技术研报
8562 点击 2026-06-30 09:53
 搜索
搜索
你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。

就在今天凌晨,哈佛博士Douglas Yao在X宣布,研发了一款针对阿尔茨海默病的新药PAC-832,引发了数百人的围观。这是世界上第一个选择性GalR1拮抗剂,创始人表示全程使用了机器人自动化技术和AI大模型。

昨晚,开发者sir1st发布了Hermes Agent桌面版:Hermes Desktop,将先前很多人在用的Hermes Web UI打包塞进了一个桌面应用程序中,养马人不仅可以逃离命令行界面,这下连浏览器都不用打开了。
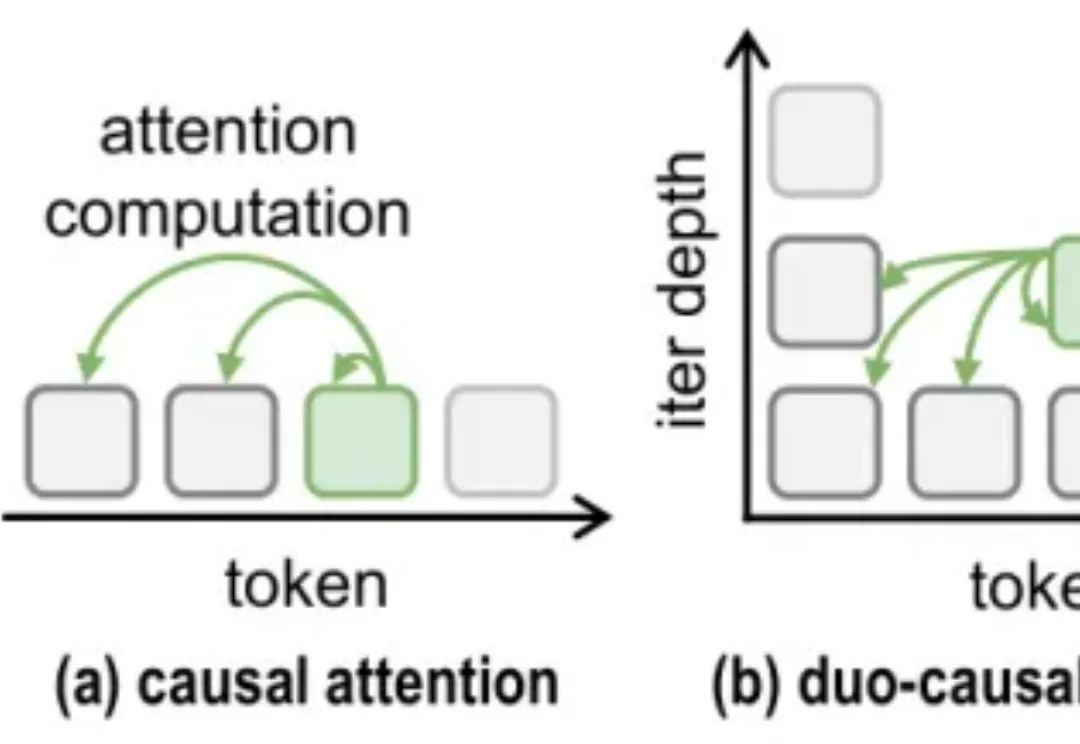
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :

机器人拉个拉链,到底需不需要“脑子”?

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

刚刚,宇树发布其迄今定价最低的人形机器人——R1系列双臂人形机器人,支持工业及日常家用多元场景应用,售价2.69万元起。这是宇树首款主打桌面、面向工业场景的低成本轻量化上半身双臂方案。该系列机器人支持5/7自由度单臂、固定/移动底盘,头部模组算力达10TOPS,末端可快速换装,手臂最大负载2kg,腰部±150°、头部±115°/±36°大运动范围。

成立不到一年,跻身“百亿估值俱乐部”。