出海应用也能享受高速稳定的DeepSeek-R1?亚马逊云科技出手了
出海应用也能享受高速稳定的DeepSeek-R1?亚马逊云科技出手了给大模型落地,加入极致的务实主义。
来自主题: AI技术研报
9821 点击 2025-03-14 16:35
 搜索
搜索
给大模型落地,加入极致的务实主义。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。

最新研究显示,以超强推理爆红的DeepSeek-R1模型竟藏隐形危险——
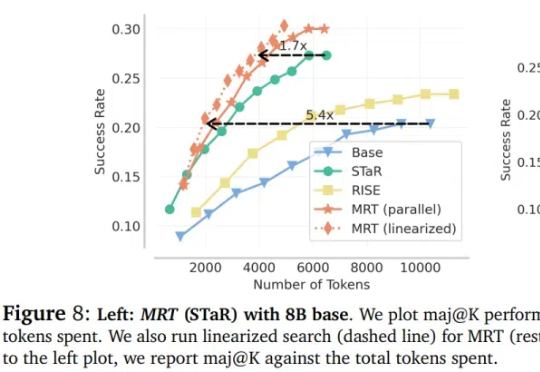
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

号称地表最强的M3 Ultra,本地跑满血版DeepSeek R1,效果到底如何?

就在刚刚,谷歌Gemma 3来了,1B、4B、12B和27B四种参数,一块GPU/TPU就能跑!而Gemma 3仅以27B就击败了DeepSeek 671B模型,成为仅次于DeepSeek R1最优开源模型。
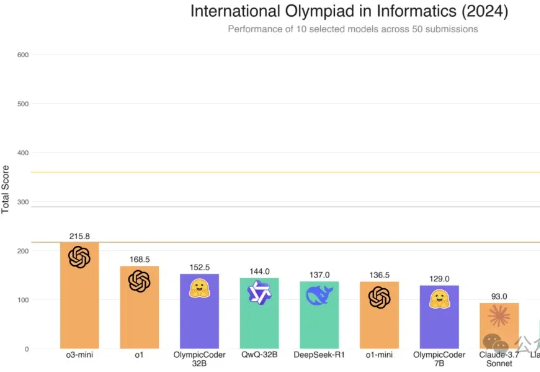
Hugging Face的Open R1重磅升级,7B击败Claude 3.7 Sonnet等一众前沿模型。凭借CodeForces-CoTs数据集的10万高质量样本、IOI难题的严苛测试,以及模拟真实竞赛的提交策略优化,这款模型展现了惊艳的性能。
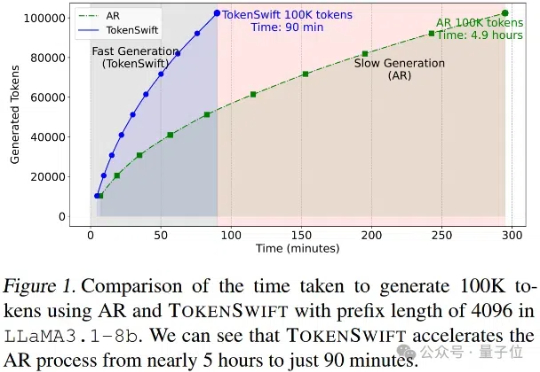
大语言模型长序列文本生成效率新突破——生成10万Token的文本,传统自回归模型需要近5个小时,现在仅需90分钟!

乙巳新春,中国的推理大模型DeepSeek R1火爆全球。作为一款在推理能力上媲美OpenAI的o1且收费标准远低于o1的国产大模型,DeepSeek一时间在国内刮起一股扑面而来的全民AI风潮,并不令人意外,但这款来自大厂体系外创业团队的开源大模型,经由数位外国商界领袖与技术大佬口碑相传并最终形成在外国新闻媒体上“刷屏”的效果,则是非常耐人寻味了。
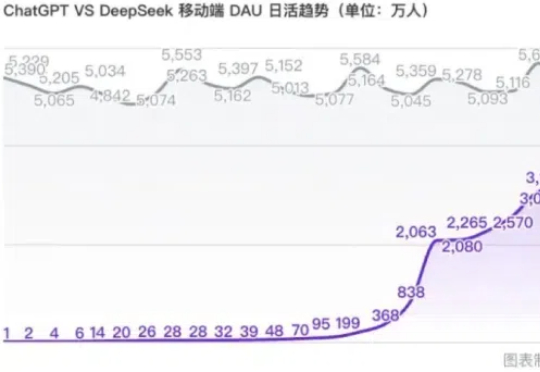
今天凌晨,亚马逊云科技宣布在Amazon Bedrock平台上推出全托管、无服务器的DeepSeek-R1模型,是首个提供DeepSeek-R1作为全托管、正式商用模型的海外云厂商。