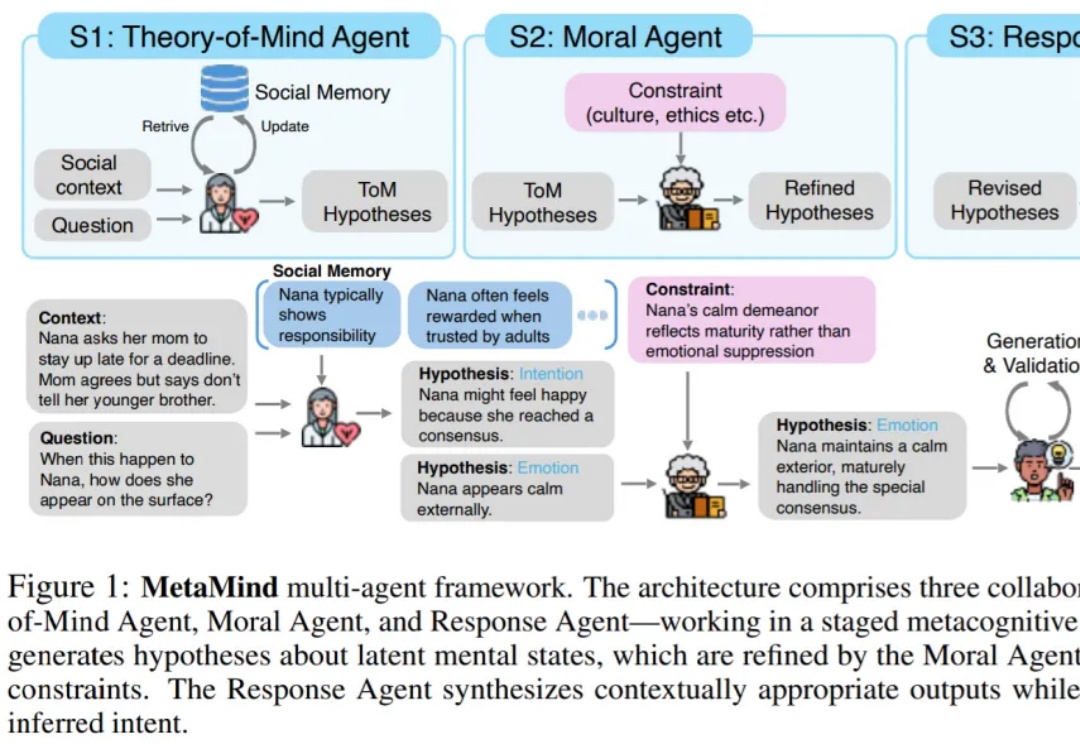
AI终于学会「读懂人心」,带飞DeepSeek R1,OpenAI o3等模型
AI终于学会「读懂人心」,带飞DeepSeek R1,OpenAI o3等模型“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice
来自主题: AI技术研报
8970 点击 2025-11-21 09:16
 搜索
搜索
“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice

近日,微博正式发布首个自研开源大模型VibeThinker,这个仅拥有15亿参数的“轻量级选手”,在国际顶级数学竞赛基准测试上击败了参数量是其数百倍的、高达6710亿的DeepSeek R1模型。
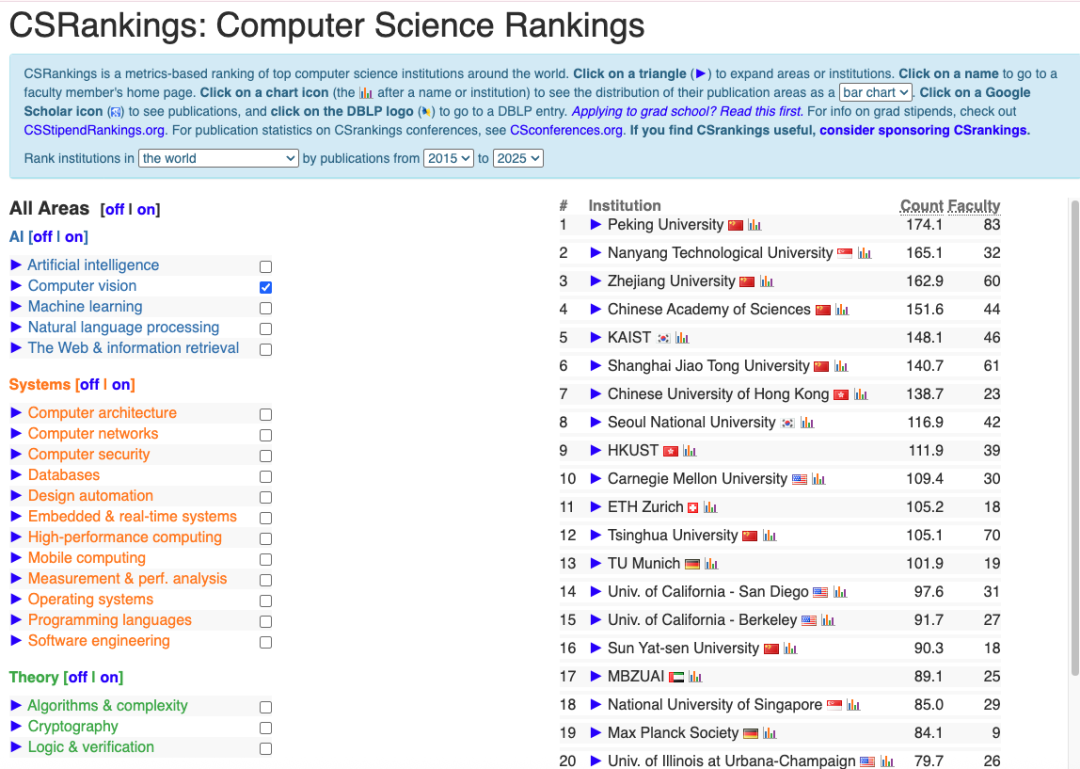
在计算机科学领域, CSRankings 曾被视为一次划时代的改进。它摒弃了早期诸如 USNews 那样依赖调查问卷的主观排名体系,转而以论文发表数量这一客观指标来评估各大学的科研实力。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。

比Nano Banana更擅长P细节的图像编辑模型来了,还是更懂中文的那种。
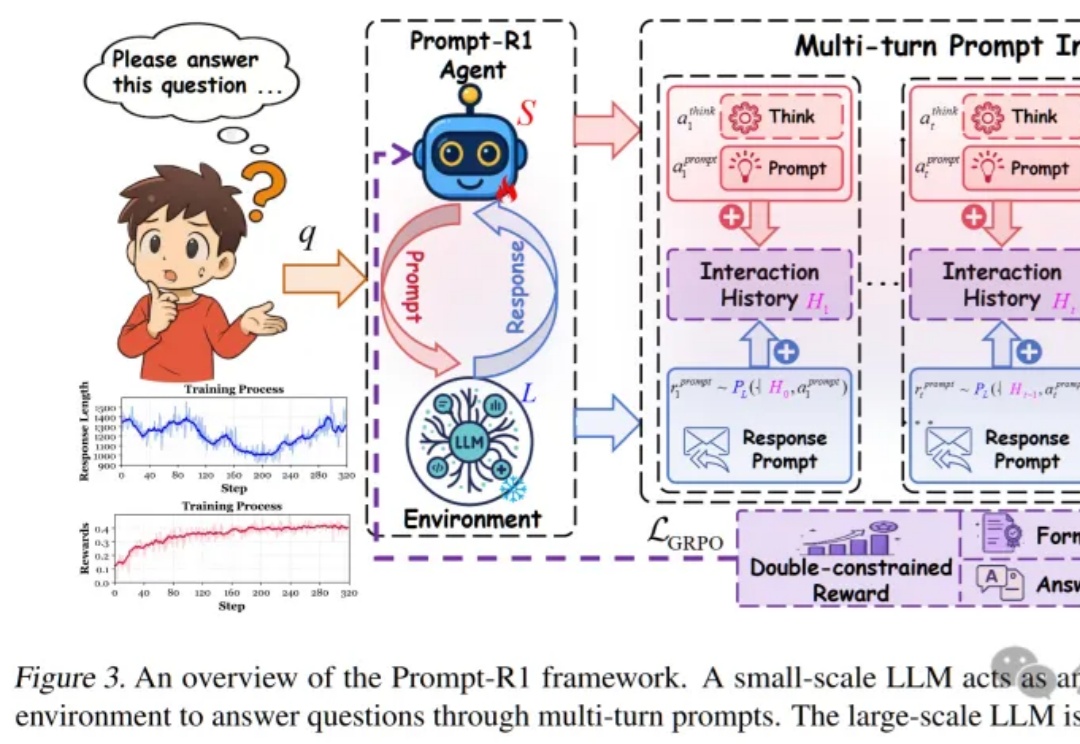
这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。
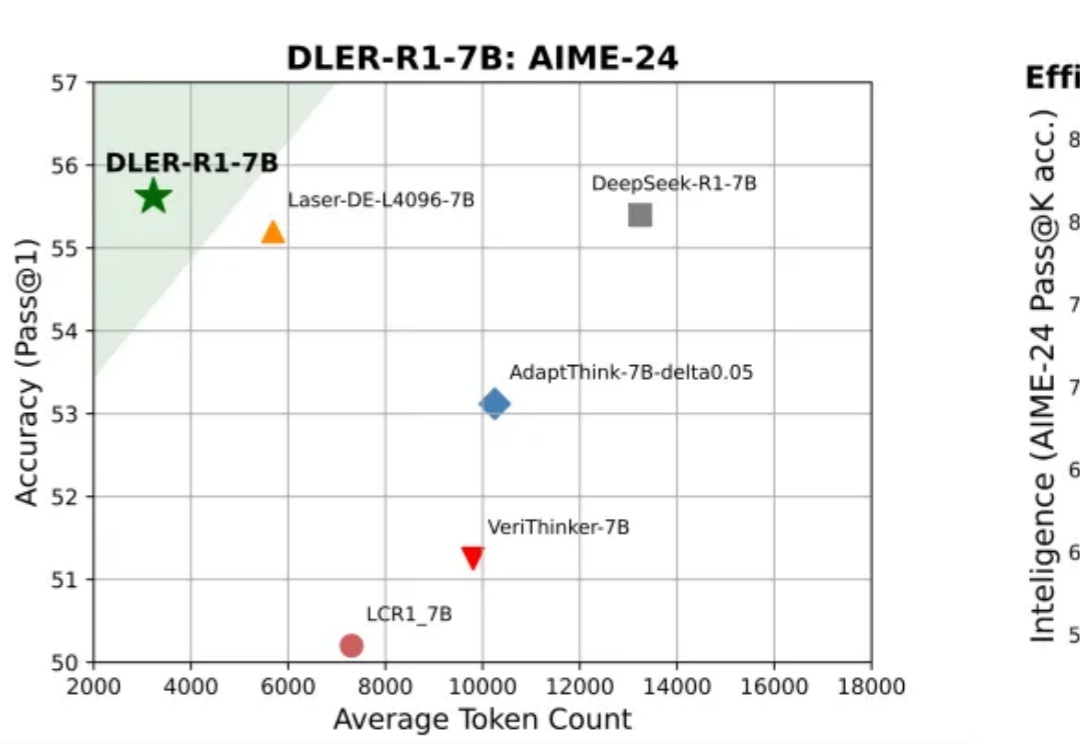
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。
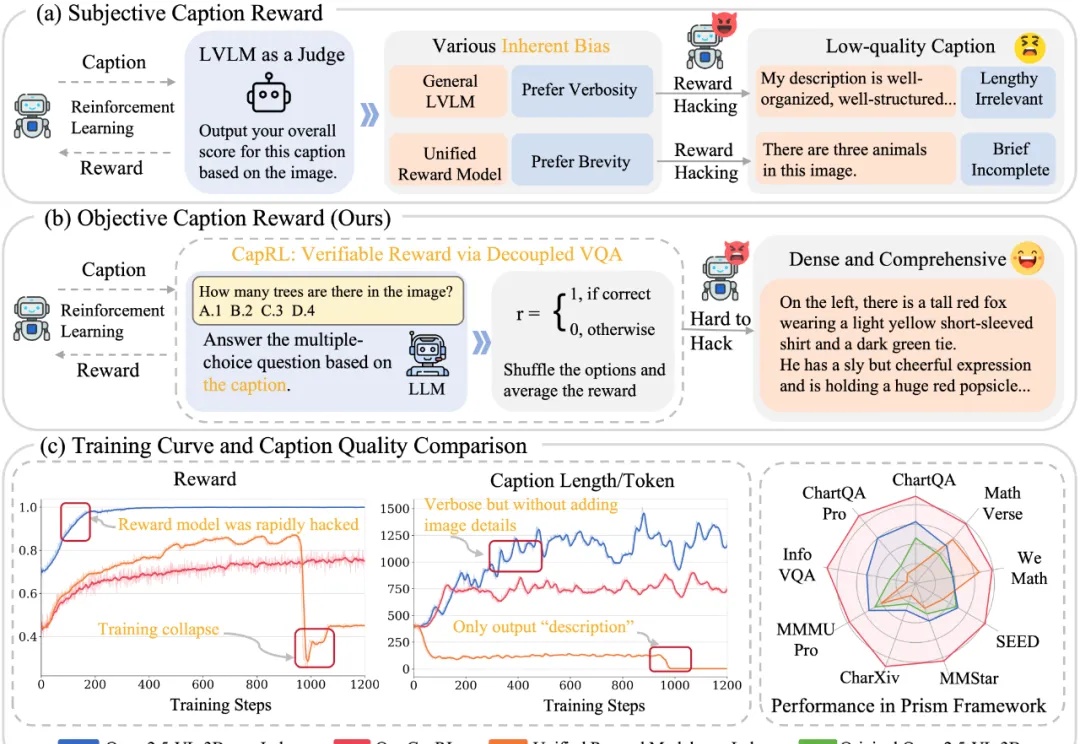
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。
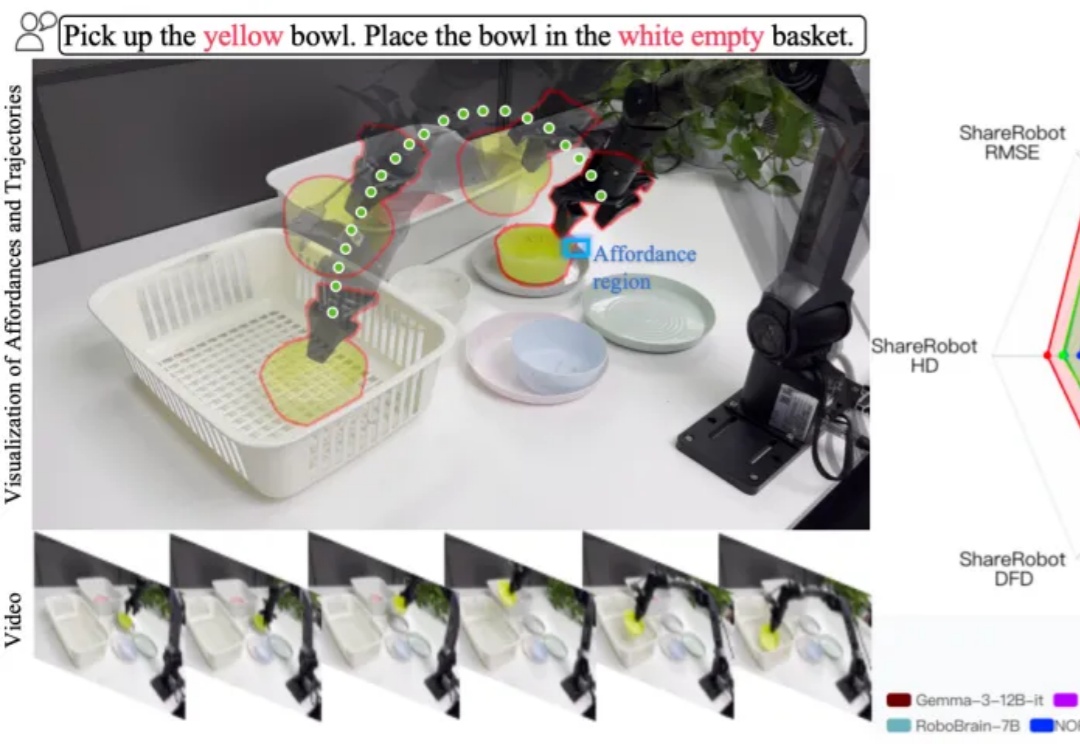
在机器人与智能体领域,一个老大难问题是:当你让机器人 “把黄碗放进白色空篮子” 或 “从微波炉里把牛奶取出来放到餐桌上” 时,它不仅要看懂环境,更要解释指令、规划路径 / 可操作区域,并把这些推理落实为准确的动作。

王自如撑场,雷鸟上桌。 刚刚,雷鸟发布了全球首个HDR10 AR眼镜—— 雷鸟Air 4,1599元起售。 大家不知道HDR10没关系,咱直接看画质对比就完事儿:AR眼镜摇身一变,开始玩专业摄影那套了。甚至连好久不出面儿的王自如也被拉来做评测了,不禁感慨,这是重拾旧业啊: