
论文秒变海报!开源框架PosterAgent一键生成顶会级学术Poster
论文秒变海报!开源框架PosterAgent一键生成顶会级学术Poster你好研究僧,听说刚刚中了顶会,却还在愁怎么做Poster(学术海报)?
来自主题: AI技术研报
9985 点击 2025-06-04 09:24
 搜索
搜索
你好研究僧,听说刚刚中了顶会,却还在愁怎么做Poster(学术海报)?
您是否遇到过这样的困扰:明明搭建了完善的RAG系统,但Agent总是回答过时的信息,或者面对历史偏好变化时一脸茫然?
作为一家在银行技术领域拥有超过 30 年行业经验的领军供应商,我们拥有丰富且极具创新性的代码库,并通过战略性收购不断扩大业务。

在刚刚结束的 Google I/O 开发者大会中,Google 宣布上线由 Gemini 驱动的高级 AI 搜索模式 AI Mode,可以应对复杂问题,支持追问。与之前的 AI Overviews 对 AI 搜索的浅尝辄止不同,Google 终于不再死抱着“关键词+链接列表”,开始拥抱“自然语言交互+结构化答案”的“新”范式了。
大家好,我是袋鼠帝 一直以来,分享了不少关于工作流平台、LLM应用平台的不少干货文章。 主要包含:Dify、Coze、n8n、Fastgpt、Ragflow。大家好,我是袋鼠帝 一直以来,分享了不少关于工作流平台、LLM应用平台的不少干货文章。 主要包含:Dify、Coze、n8n、Fastgpt、Ragflow

全面拥抱AI之后,OceanBase首次详解了他们的战略。
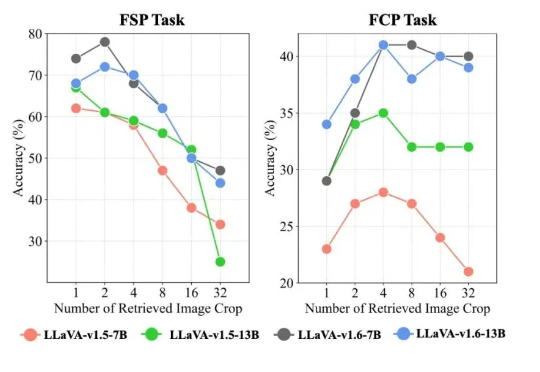
该工作由南洋理工大学陶大程教授团队与武汉大学罗勇教授、杜博教授团队等合作完成。
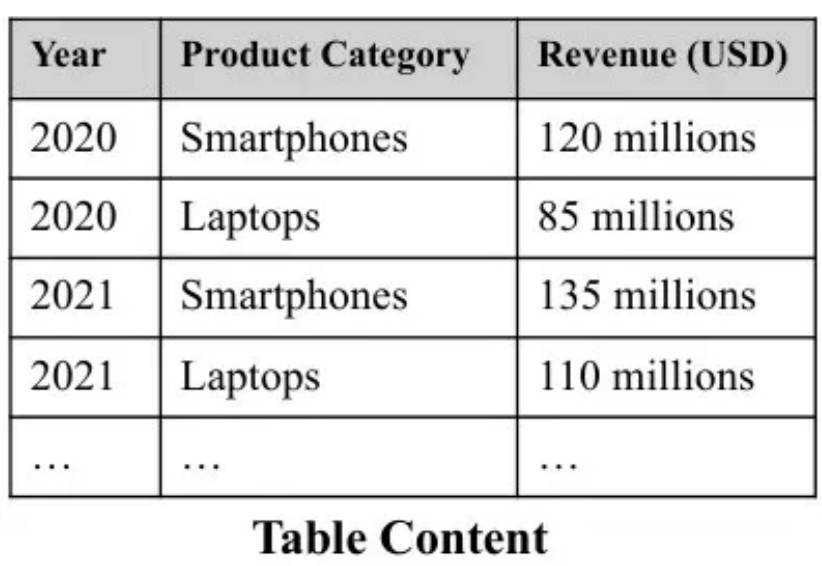
在上一篇文章中,我为大家介绍了SAT如何通过神经网络驱动的智能分段技术,解决传统文本处理中的语义割裂问题。今天,我将继续与您探讨SAT如何与Pneuma系统融合,开创表格数据检索与表示的新范式。

搞RAG开发,一个被普遍忽视却又至关重要的痛点是:如何避免Token分块带来的语义割裂问题。SAT模型通过神经网络驱动的智能分段技术,巧妙解决了这一难题。它不是RAG的替代,而是RAG的强力前置增强层,通过确保每个文本块的语义完整性,显著降低下游生成的幻觉风险。
最近ContextGem很火。它既不是RAG也不是Agent,而是专注于"结构化提取"的框架,它像一个"文档理解层",通过文档中心设计和神经网络技术(SAT)将非结构化文档转化为精确的结构化数据。它可作为RAG的前置处理器、Agent的感知模块,也可独立使用。