
独家|经纬领投了一家因果世界模型公司“Aether AI”
独家|经纬领投了一家因果世界模型公司“Aether AI”投中网独家获悉,专注于因果世界模型(Causal World Model)的人工智能公司Aether AI 正式宣布完成首轮融资,募集资金总额约2000万美元。该轮融资由经纬创投领投,英诺基金、SWC Global、九合创投等机构联合参投。
来自主题: AI资讯
8820 点击 2026-06-18 17:27
 搜索
搜索
投中网独家获悉,专注于因果世界模型(Causal World Model)的人工智能公司Aether AI 正式宣布完成首轮融资,募集资金总额约2000万美元。该轮融资由经纬创投领投,英诺基金、SWC Global、九合创投等机构联合参投。

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
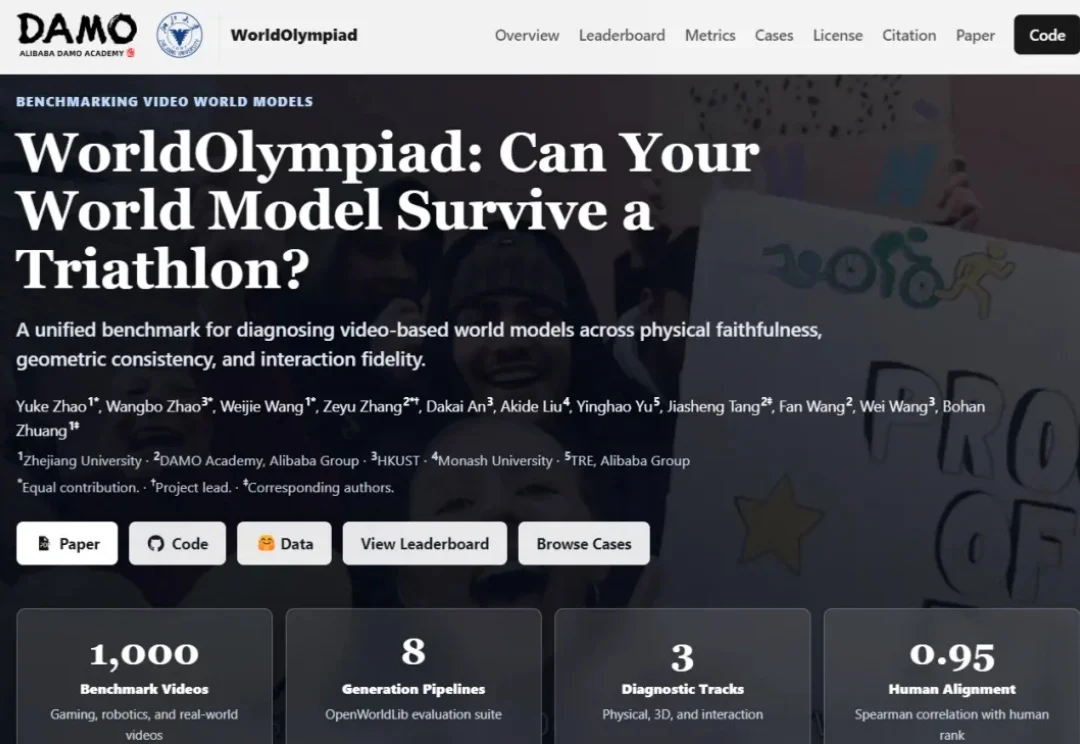
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。

今天,由李飞飞联合创立的空间智能公司 World Labs 在同一天发布了三篇技术论文!三篇论文分别由公司内部实习生主导完成,研究方向各异,但共享同一个核心命题:借助已在海量图片数据上训练成熟的 2D 生成模型,降低 3D 内容生成的难度门槛。

世界模型(World Model),正在成为AI领域新的技术高地。从OpenAI的Sora,到图灵奖得主Yann LeCun力推的JEPA体系,再到李飞飞创办的World Labs,全球最顶尖的一批研究者都在试图回答同一个问题:AI究竟如何像人一样理解世界,而不仅仅是生成语言和图像。

Anthropic自家工程师早已基本不写代码了,却280美元一个任务,花钱请约1000名外部工程师,手把手教Claude Code写出好代码。喂养前沿模型的,终究还是人。
空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务
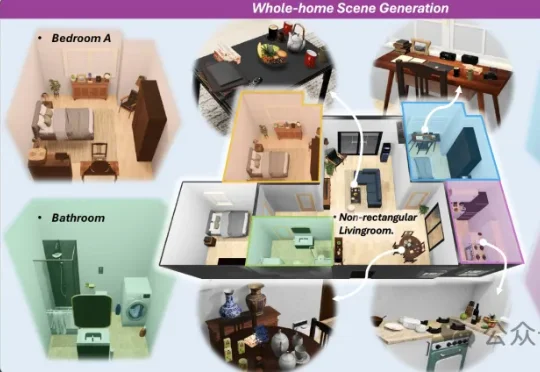
一觉睡醒,具身智能公司竟然也开始搞房地产了?!刚刚,大晓机器人联合港中文MMLab发布了一个新项目——Kairos-Homeworld,全球首个实现全屋三维生成与物体级全交互的统一框架。

近日,北京大学 EvoPhys 团队推出首个以 “人” 为中心的 “场景级万物可控” 5D 世界模型 EvoPhys-World,基于摩尔线程全国产算力底座,团队首次将 AI 生成世界从 “可观看、可漫游,浅交互” 的阶段,推进到 “可操纵、深交互、自进化” 的新阶段。
近日,全球具身世界模型权威评测基准 WorldArena 公布最新榜单。在 5 月 25 日截止的最终榜单中,跨维智能登顶 Track 2 赛道全球第一。可以说是,在英伟达、谷歌等全球科技巨头深度布局、重兵把守的世界模型核心腹地,跨维智能实现了强势突围。