世界模型榜首易主!跨维智能登顶WorldArena
世界模型榜首易主!跨维智能登顶WorldArena近日,全球具身世界模型权威评测基准 WorldArena 公布最新榜单。在 5 月 25 日截止的最终榜单中,跨维智能登顶 Track 2 赛道全球第一。可以说是,在英伟达、谷歌等全球科技巨头深度布局、重兵把守的世界模型核心腹地,跨维智能实现了强势突围。
来自主题: AI资讯
8562 点击 2026-06-03 15:27
 搜索
搜索
近日,全球具身世界模型权威评测基准 WorldArena 公布最新榜单。在 5 月 25 日截止的最终榜单中,跨维智能登顶 Track 2 赛道全球第一。可以说是,在英伟达、谷歌等全球科技巨头深度布局、重兵把守的世界模型核心腹地,跨维智能实现了强势突围。

如果说扩散世界模型的瓶颈,是每一步去噪都要把同一个大 Transformer 再跑一遍,那么 WorldCache 的思路就是:不要再把所有 Token、所有时间步都当成同一件事。这篇工作把 “哪些内容适合缓存”和“哪些时刻必须重算” 拆开处理,在不重新训练模型、几乎不增加额外显存的前提下,把缓存真正做成了一套更贴合世界模型结构的推理策略。
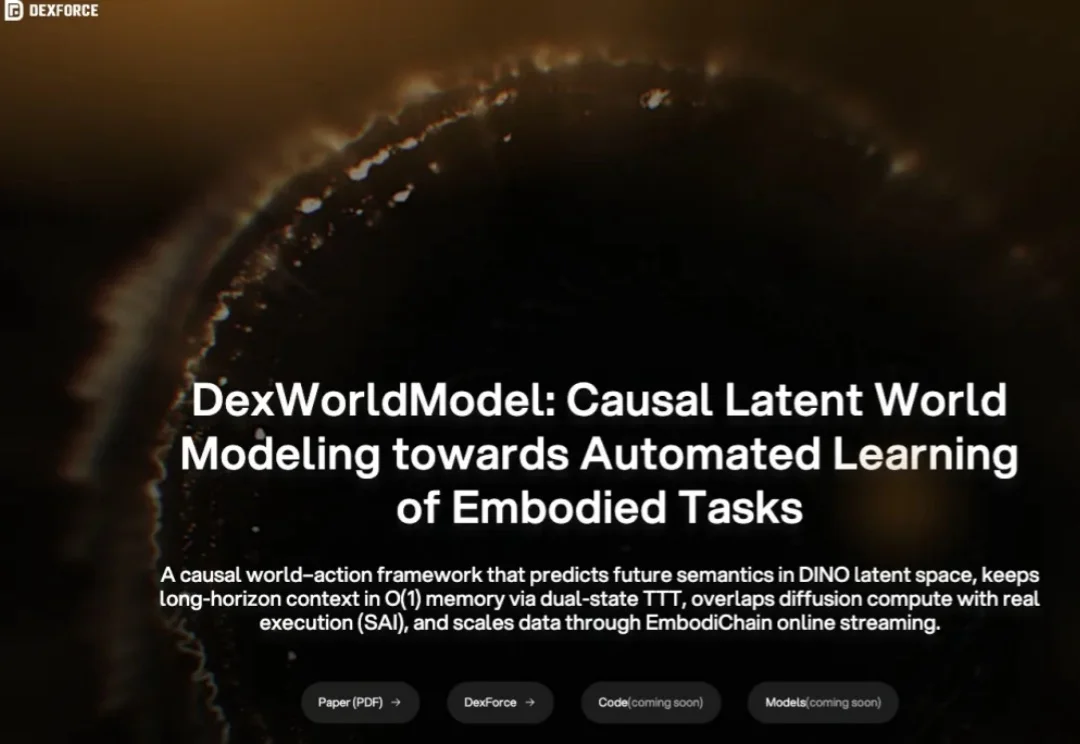
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。
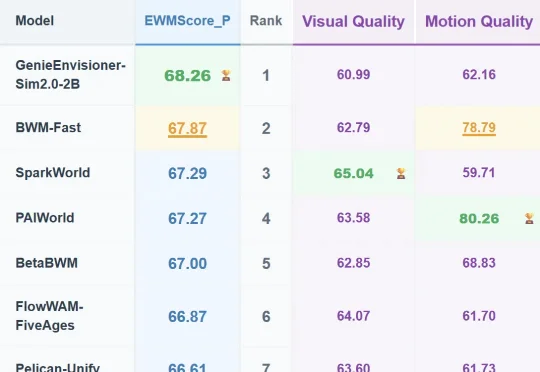
WorldArena 世界模型赛道从来都是竞争异常激烈,在经历了前几次比赛过程中的放榜之后,CVPR 2026 WorldArena 世界模型赛道锁定总成绩,智元自研的世界模型 Genie Envisioner-Sim 2.0(以下简称 GE 2.0)拿下了最终的冠军,成为了 “强者中的强者”。

真实世界需要 200 多个小时的模型评测任务,可以在仿真中不到 0.5 小时内完成。
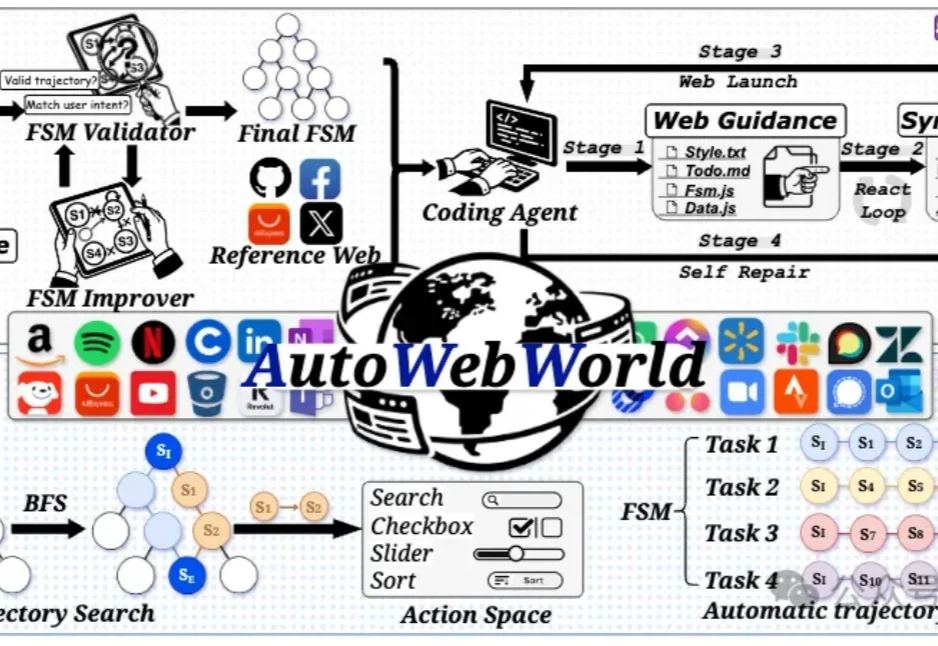
训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。

英伟达世界动作模型 DreamZero 训练一次要烧 8 张 H100 整整 25 天,RLinf 从算子融合到 I/O 全链路系统级重构,把训练吞吐拉高近 4 倍——1 个月的活,1 周就能干完。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。