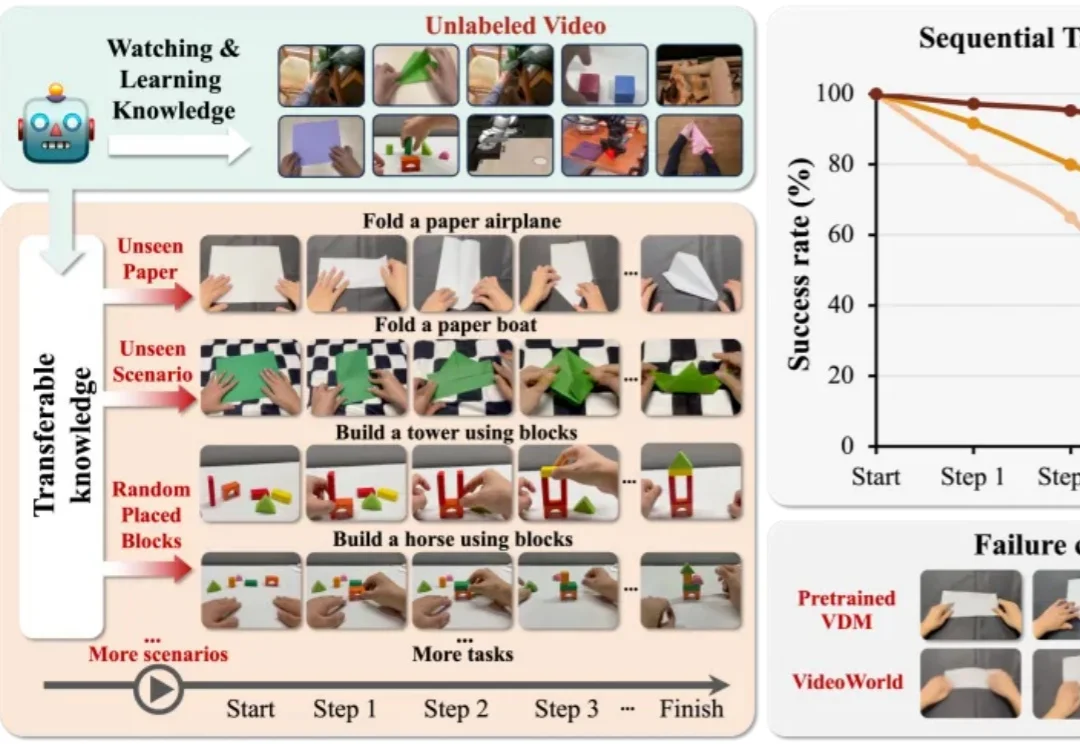
CVPR 2026 | AI寒武纪时刻?字节世界模型新作,仅靠视觉学习真实世界知识
CVPR 2026 | AI寒武纪时刻?字节世界模型新作,仅靠视觉学习真实世界知识视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
来自主题: AI技术研报
6234 点击 2026-03-09 14:29
 搜索
搜索
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
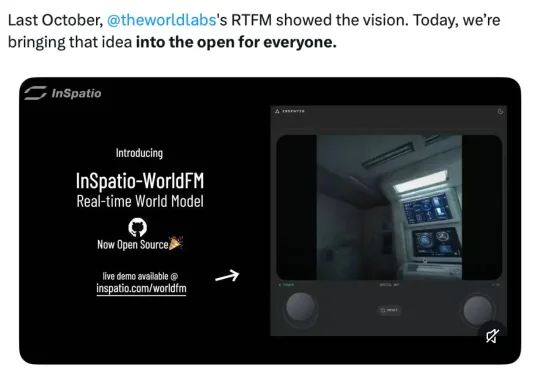
在 50 亿美元估值神话的背后,这一空间智能的最新高地正被国内创业公司攻克并推向产业纵深。近日,影溯(InSpatio)正式发布并开源了其实时帧生成模型 InSpatio-WorldFM,一个实时交互的 3D 世界模型。这标志着中国团队在空间智能底层技术上取得了奠基性突破,而且以开放的姿态,正成为推动 AI 从虚拟屏幕走向物理现实的关键破局者。
机器之心编辑部 近日,一款名为 StoryWorld 的 iOS 产品 Demo 在海外开发者与 3D 创作者社区引发关注:用户只需用手机摄像头对准真实空间,通过语音输入描述,即可生成 3D 角色与物

OpenAI的人才地震还在继续!刚刚,前研究副总裁Max Schwarzer宣布离职,这位亲手主导o1、o3和整个GPT-5系列post-training的核心人物,选择加入Anthropic,重返一线RL研究。
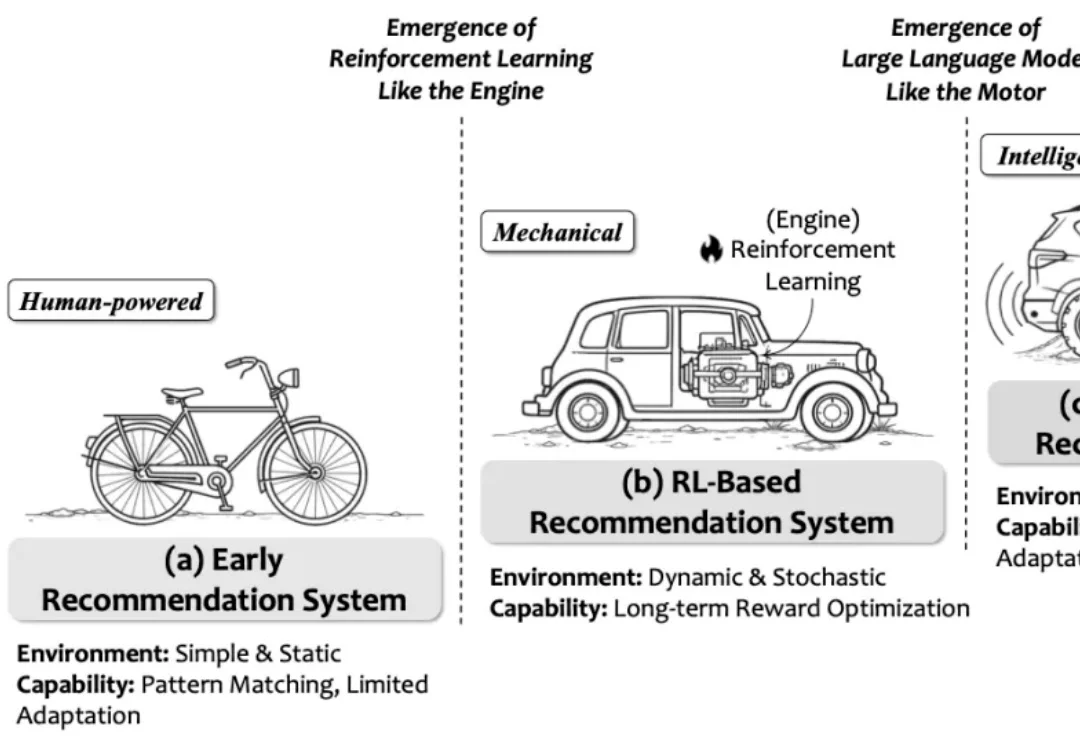
强化学习(RL)将推荐系统建模为序列决策过程,支持长期效益和非连续指标的优化,是推荐系统领域的主流建模范式之一。然而,传统 RL 推荐系统受困于状态建模难、动作空间大、奖励设计复杂、反馈稀疏延迟及模拟环境失真等瓶颈。
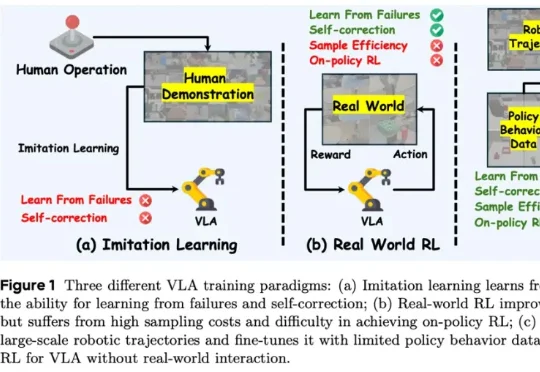
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。
近日, Anthropic 和斯坦福研究者 Neil Rathi 与这位传奇研究者联合发布了一篇新论文,并得到了一些相当惊人的新发现。在这项研究中,他们挑战了当前大模型安全领域的一个核心假设。长期以来,业界普遍认为要在模型发布后通过 RLHF 或微调来限制其危险行为。但 Neil Rathi 和 Alec Radford 提出了一种更本质的解法:
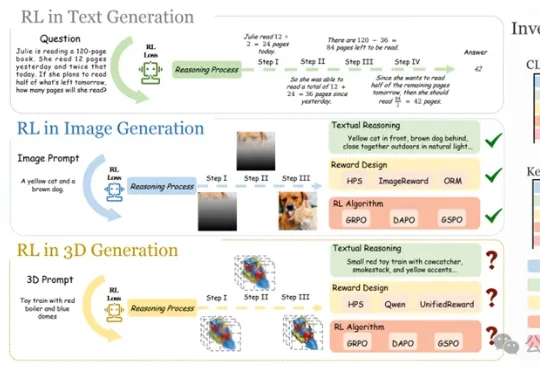
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。
刚刚,毕业清华大学数学系,曾在Meta FAIR工作3.75年、主导过SAM与Llama多项核心工作的研究员张鹏川(Pengchuan Zhang)宣布离职。他的下一站,是来到OpenAI,投身于世界模拟与机器人学(World Simulation and Robotics)方向的研究。
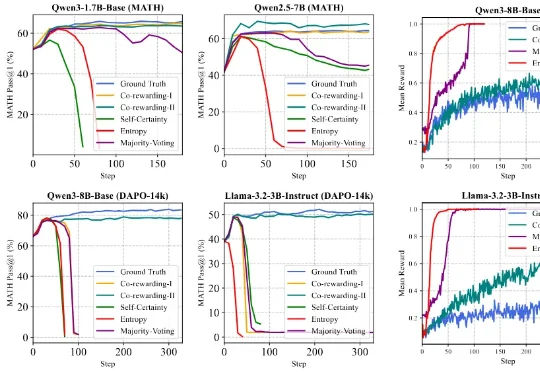
针对这一挑战,来自香港浸会大学和上海交通大学的可信机器学习和推理组提出了一个全新的自监督 RL 框架 ——Co-rewarding。该框架通过在数据端或模型端引入互补视角的自监督信号,稳定奖励获取,提升 RL 过程中模型奖励投机的难度,从而有效避免 RL 训练崩溃,实现稳定训练和模型推理能力的诱导。