
这个团队做了OpenAI没Open的技术,开源OpenRLHF让对齐大模型超简单
这个团队做了OpenAI没Open的技术,开源OpenRLHF让对齐大模型超简单随着大型语言模型(LLM)规模不断增大,其性能也在不断提升。尽管如此,LLM 依然面临着一个关键难题:与人类的价值和意图对齐。在解决这一难题方面,一种强大的技术是根据人类反馈的强化学习(RLHF)。
来自主题: AI技术研报
11013 点击 2024-06-07 10:36
 搜索
搜索
随着大型语言模型(LLM)规模不断增大,其性能也在不断提升。尽管如此,LLM 依然面临着一个关键难题:与人类的价值和意图对齐。在解决这一难题方面,一种强大的技术是根据人类反馈的强化学习(RLHF)。
比斯坦福DPO(直接偏好优化)更简单的RLHF平替来了,来自陈丹琦团队。 该方式在多项测试中性能都远超DPO,还能让8B模型战胜Claude 3的超大杯Opus。 而且与DPO相比,训练时间和GPU消耗也都大幅减少。

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。
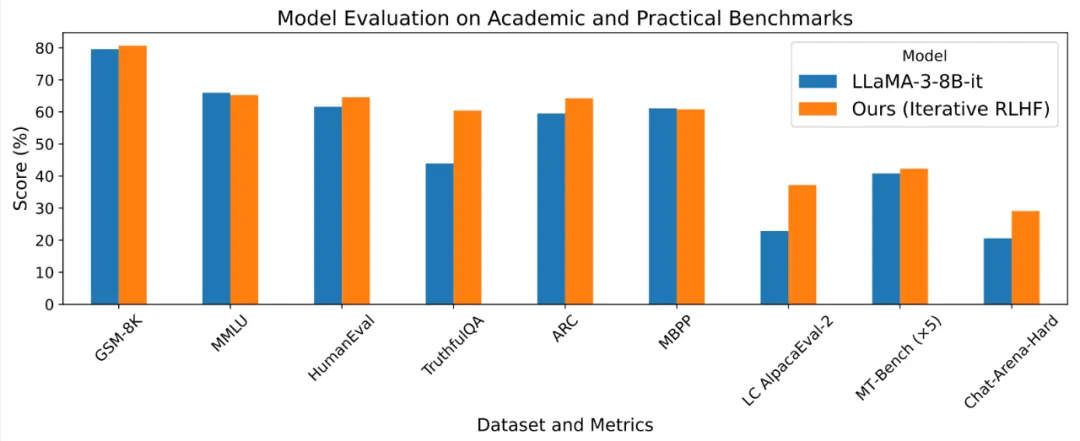
基于人类反馈的强化学习 (RLHF) 使得大语言模型的输出能够更加符合人类的目标、期望与需求,是提升许多闭源语言模型 Chat-GPT, Claude, Gemini 表现的核心方法之一。
Ilya Sutskever宣布退出OpenAI,震动整个AI圈。
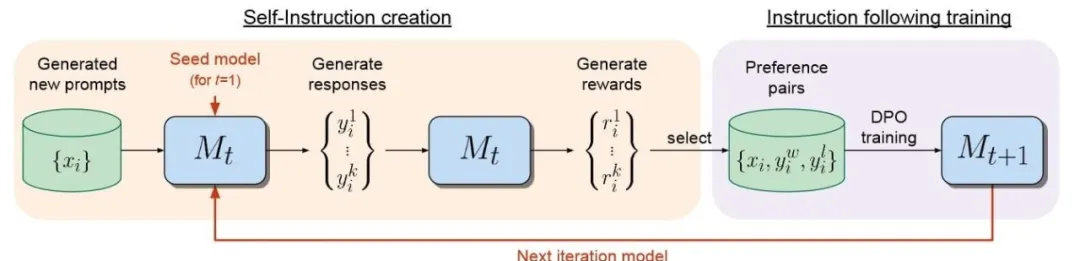
在大语言模型领域,微调是改进模型的重要步骤。伴随开源模型数量日益增多,针对LLM的微调方法同样在推陈出新。

在对齐大型语言模型(LLM)与人类意图方面,最常用的方法必然是根据人类反馈的强化学习(RLHF)
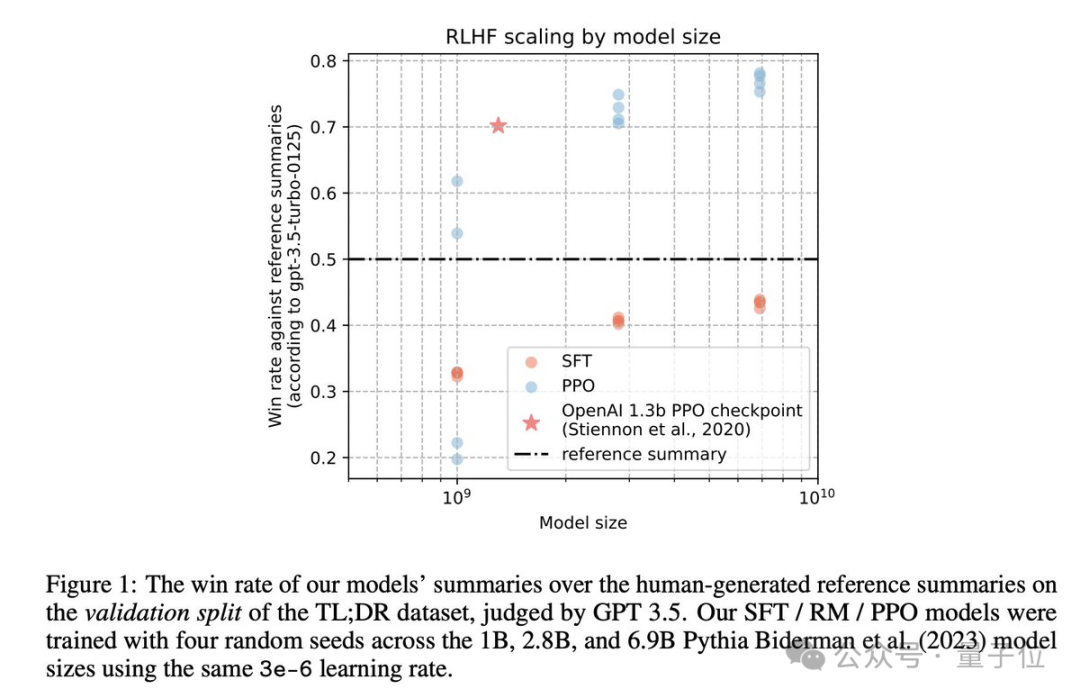
OpenAI的秘密武器、ChatGPT背后功臣RLHF,被开源了。来自Hugging Face、加拿大蒙特利尔Mila研究所、网易伏羲AI Lab的研究人员从零开始复现了OpenAI的RLHF pipeline,罗列了25个关键实施细节。

RLHF 通过学习人类偏好,能够在难以手工设计奖励函数的复杂决策任务中学习到正确的奖励引导,得到了很高的关注,在不同环境中选择合适的人类反馈类型和不同的学习方法至关重要
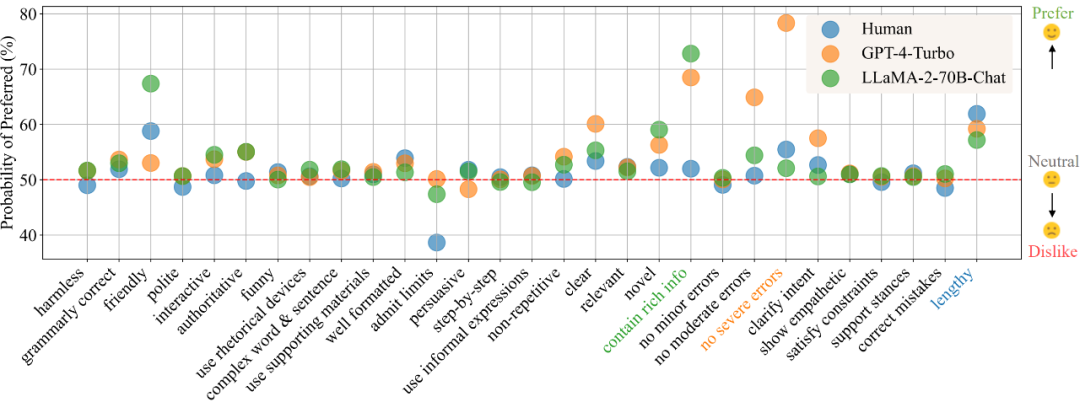
在目前的模型训练范式中,偏好数据的的获取与使用已经成为了不可或缺的一环。在训练中,偏好数据通常被用作对齐(alignment)时的训练优化目标,如基于人类或 AI 反馈的强化学习(RLHF/RLAIF)或者直接偏好优化(DPO),而在模型评估中,由于任务的复杂性且通常没有标准答案,则通常直接以人类标注者或高性能大模型(LLM-as-a-Judge)的偏好标注作为评判标准。