Sora创建病毒式视频全网疯转,OpenAI密谋推出TikTok竞品?专家猜测:这是计划的一部分
Sora创建病毒式视频全网疯转,OpenAI密谋推出TikTok竞品?专家猜测:这是计划的一部分为何OpenAI只在TikTok上发布Sora新视频?AI专家猜测这是计划的一部分:创建病毒式视频、加水印、收集数据、添加RLHF、推出TikTok竞品……整套流程一气呵成。
来自主题: AI资讯
2981 点击 2024-02-23 14:38
 搜索
搜索
为何OpenAI只在TikTok上发布Sora新视频?AI专家猜测这是计划的一部分:创建病毒式视频、加水印、收集数据、添加RLHF、推出TikTok竞品……整套流程一气呵成。

尽管收集人类对模型生成内容的相对质量的标签,并通过强化学习从人类反馈(RLHF)来微调无监督大语言模型,使其符合这些偏好的方法极大地推动了对话式人工智能的发展。
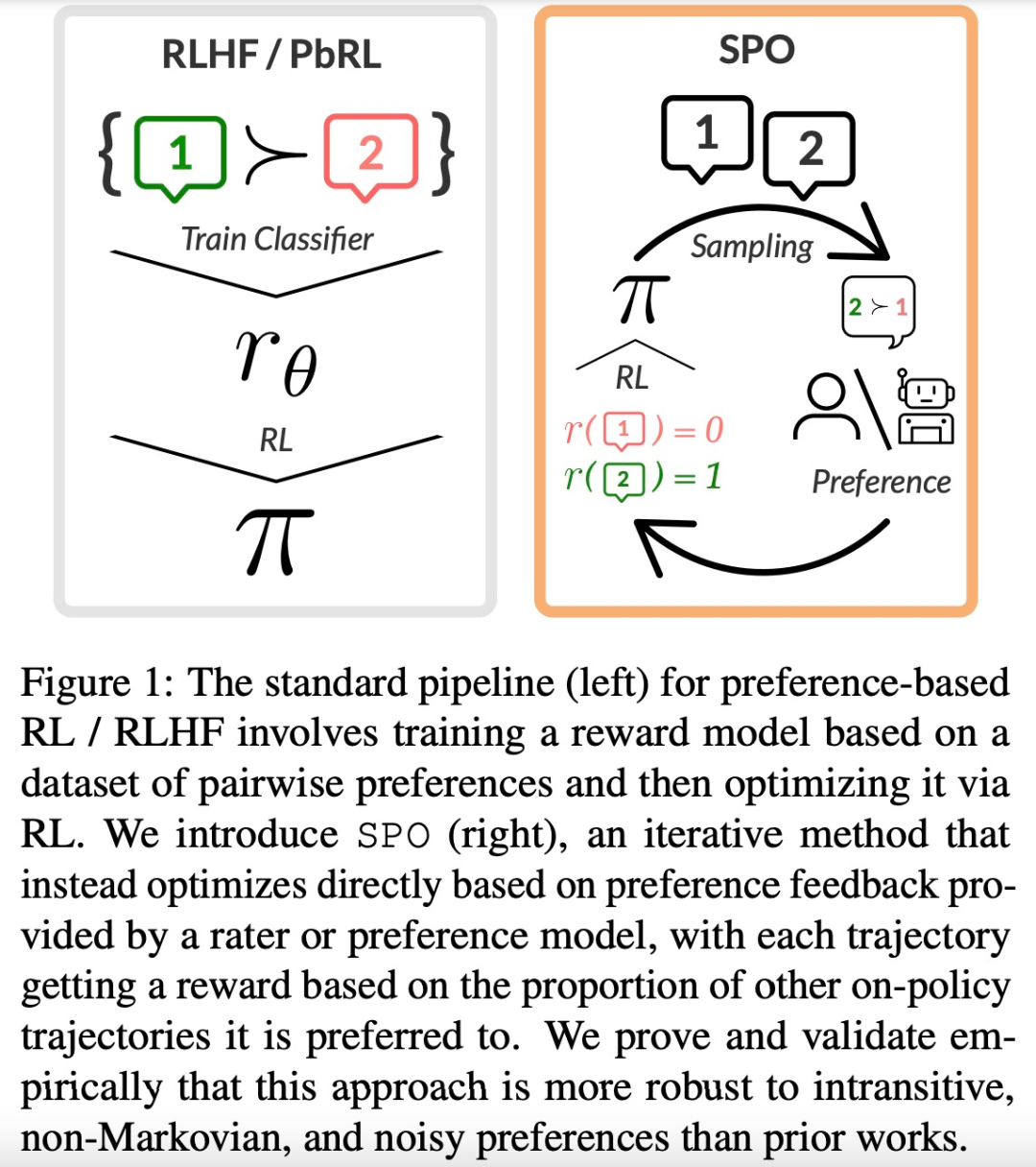
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。
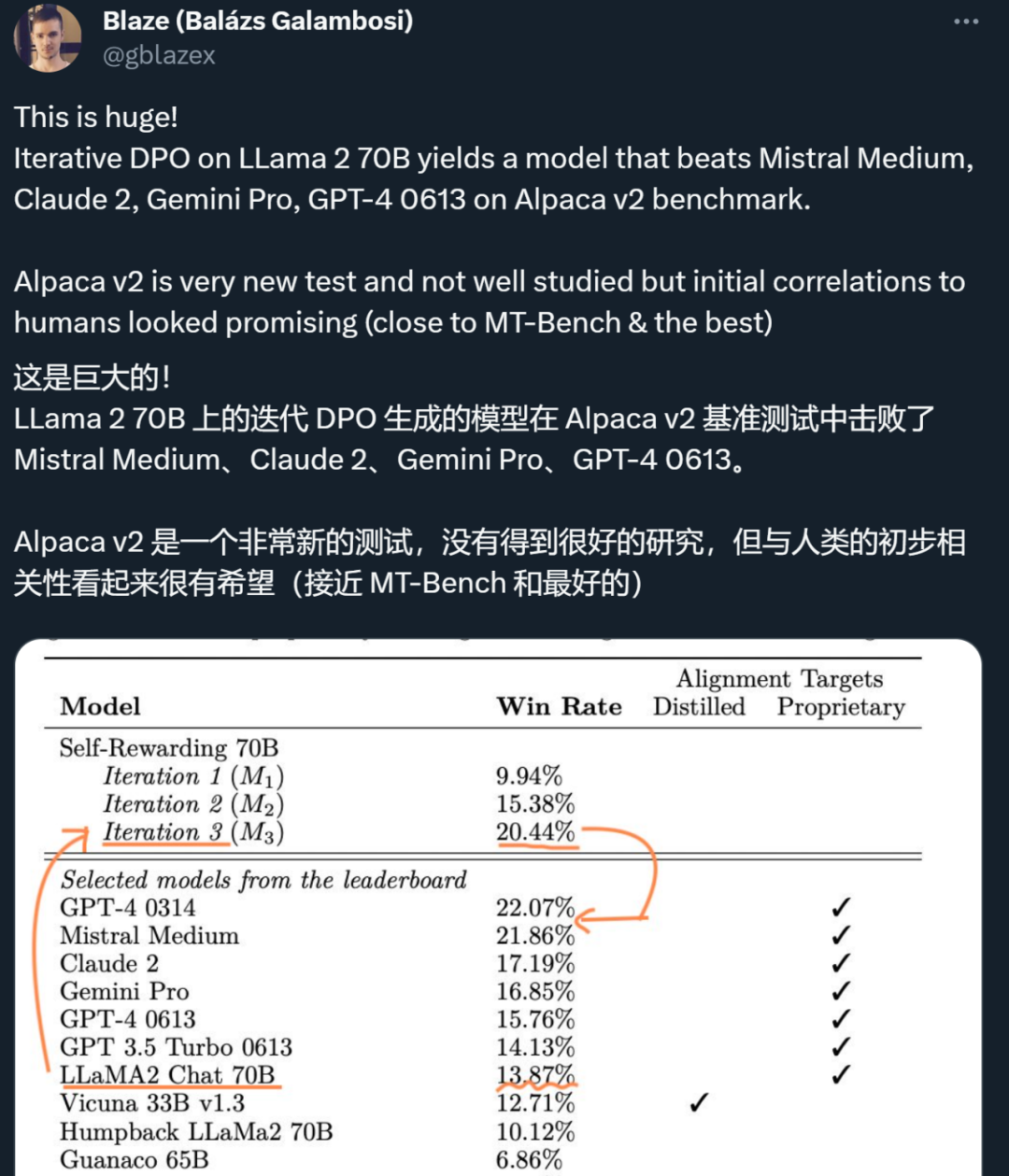
人工智能的反馈(AIF)要代替 RLHF 了?
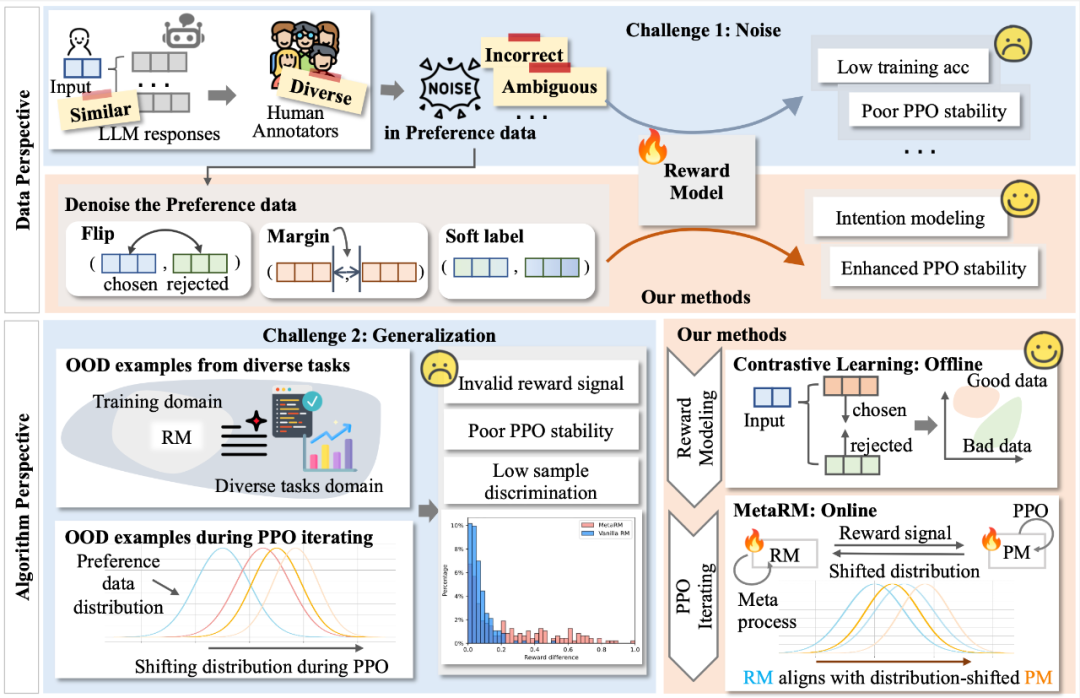
复旦团队进一步挖掘 RLHF 的潜力,重点关注奖励模型(Reward Model)在面对实际应用挑战时的表现和优化途径。

OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。

多模态技术是 AI 多样化场景应用的重要基础,多模态大模型(MLLM)展现出了优秀的多模态信息理解和推理能力,正成为人工智能研究的前沿热点。上周,谷歌发布 AI 大模型 Gemini,据称其性能在多模态任务上已全面超越 OpenAI 的 GPT-4V,再次引发行业的广泛关注和热议。

随着大型语言模型(LLM)的发展,从业者面临更多挑战。如何避免 LLM 产生有害回复?如何快速删除训练数据中的版权保护内容?如何减少 LLM 幻觉(hallucinations,即错误事实)? 如何在数据政策更改后快速迭代 LLM?这些问题在人工智能法律和道德的合规要求日益成熟的大趋势下,对于 LLM 的安全可信部署至关重要。

大模型的效果好不好,有时候对齐调优很关键。但近来很多研究开始探索无微调的方法,艾伦人工智能研究所和华盛顿大学的研究者用「免调优」对齐新方法超越了使用监督调优(SFT)和人类反馈强化学习(RLHF)的 LLM 性能。