# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

多模态技术是 AI 多样化场景应用的重要基础,多模态大模型(MLLM)展现出了优秀的多模态信息理解和推理能力,正成为人工智能研究的前沿热点。上周,谷歌发布 AI 大模型 Gemini,据称其性能在多模态任务上已全面超越 OpenAI 的 GPT-4V,再次引发行业的广泛关注和热议。
然而,与大语言模型一样,多模态大模型也依然受到“幻觉”问题的困扰,即模型在回答中出现与图片信息不符的内容。根据内测用户反馈,“Gemini 有时会出现一些错误和“幻觉” ;经过测试发现,即便是 GPT-4V 也会在 45.9% 的图片回答中出现明显的“幻觉”。
大模型出现“幻觉”的症结之一在于未经人类对齐时发生的 “过泛化”情况。例如,让模型描述街景图片时,无论画面中是否有行人出现,模型都会因为自身过度的泛化问题,输出对行人的描述。这种现象在当前的多模态大模型中普遍存在,也使得多模态大模型的应用在可信度问题得到解决之前仍受限制。
因此,如何尽可能减少多模态大模型的“幻觉”,提高回答的准确性和可信度,是所有人工智能研究者都在奋力攻克的难题。
近日,面壁智能联合清华大学 THUNLP 实验室及新加坡国立大学发表了一篇研究论文,推出全新的多模态大模型对齐框架 RLHF-V,从数据和算法层面入手显著减少“幻觉”的出现。

核心优势:

效果展示:RLHF-V方法有效减少“幻觉”问题
—
为了验证 RLHF-V 方法减少多模态大模型“幻觉”的有效性,研究团队训练了一个 RLHF-V 同名模型。将其与 InstructBLIP、LLaVA-RLHF、GPT-4V 模型在相同视觉问答 (VQA,Visual Question Answering)任务下的表现进行比较,结果如下:
测试效果1:在短回复问题上,RLHF-V 模型能够给出正确且精炼的回复。

在短回复问题上 RLHF-V 模型与其他模型效果对比,其中红色部分为“幻觉”,绿色部分为正确的回答
可以看到,当用户提问:“图片中的男人在干什么?”时,RLHF-V 模型正确地答出图中的人在“竖大拇指”。InstructBLIP 也给出正确回答,即图中的人在接电话。而 LLaVA-RLHF 的过长回答里包含多条事实错误,GPT-4V 的短回答里正确与错误信息交错出现。
测试效果2:在更容易产生“幻觉”的长回复问题上,RLHF-V 模型提供的回复可信度高,且包含充足有效信息。

在长回复问题上 RLHF-V 模型与其他模型效果对比,其中红色部分为“幻觉”
用户提问“你觉得这张照片里发生了什么?”,RLHF-V 模型和 GPT-4V 都在尽可能通过图片细节正确地描述场景,而 InstructBLIP 和 LLaVA-RLHF 的回答里则包含多处事实“幻觉”。
测试效果3:在减少多模态大模型因过泛化产生的 “幻觉”上,RLHF-V 的表现超过 GPT-4V。

长回复问题中,RLHF-V 与 GPT-4V 在“过泛化”现象上的对比,其中红色部分为“幻觉”,深红色部分为“过泛化”导致的场景相关的“幻觉”
当被提出“对给定图片进行详细描述”时,GPT-4V 的回答产生了与图片中厨房场景高度相关的过泛化“幻觉”答案,如 “排风扇”、“盘子架” 等,而 RLHF-V 则没有出现场景相关的物体“幻觉”。

—
在数据标注时,通过人工修改多模态大模型输出回复的方式,得到细粒度的人类偏好对齐数据。这种标注方式相比传统基于排序的数据收集方式具有三点显著优势:
第一,回答更准确:基于排序的偏好数据在训练正例中仍然可能包含“幻觉”,例如下图中对时钟具体时间的识别,包括 GPT-4V 在内的模型都频繁出现错误,而人工修改的答案能够保证训练正例准确无误,极大提高多模态偏好数据的质量。
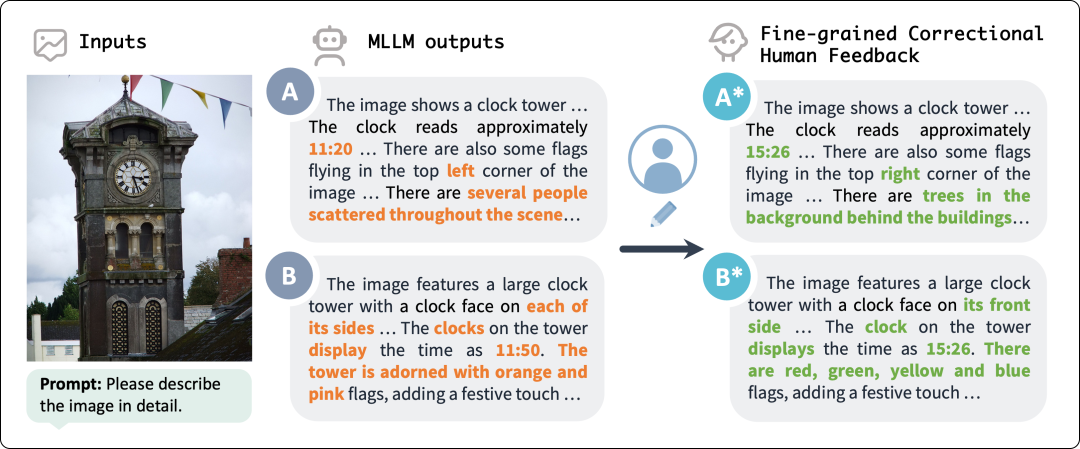
人工修改得到细粒度人类偏好对齐数据示意图
第二,无歧义的回答偏好判断:关于丰富图像内容的优质回答一般长而复杂,标注人员对这些回答进行优劣排序的过程是困难的,但如果使用 RLHF-V 提出的人工修改方法,只需找出并修改回答中的错误语句,因优劣排序而带来的标注歧义问题就会迎刃而解。
第三,提供细粒度监督信号:由于 RLHF-V 同时也提供了细化到短语级别的人类偏好数据,所以能够更加精准地鼓励或惩罚模型表现,对齐人类偏好。
目前,基于 Muffin 模型与 LLaVA 模型输出标注的偏好对齐数据已经开源,未来论文作者将会进一步扩充模型和指令规模以丰富数据多样性。
稠密监督信号的 DDPO 算法
模型“幻觉”的产生很大程度源于人类 “正/负反馈” 的缺失,从而使模型表现偏离人类偏好。在算法层面,缓解模型“幻觉”可以从采用偏好对齐算法入手。目前应用最广的人类偏好对齐算法有两种:近端策略优化(PPO,Proximal Policy Optimization) 和 直接偏好优化(DPO,Direct Preference Optimization)。
虽然新提出的 DPO 有资源消耗更低、训练更稳定的优势,但作为一个回复级别的算法,DPO 无法直接鼓励或惩罚回复中的细粒度行为。基于此,研究团队提出了 DPO 的“强化版”—— DDPO (Dense-DPO) 算法,即提高修改片段的优化权重,让模型着重学习人工修改过的语句部分,以更加充分地利用标注数据中的细粒度信息对齐人类偏好。
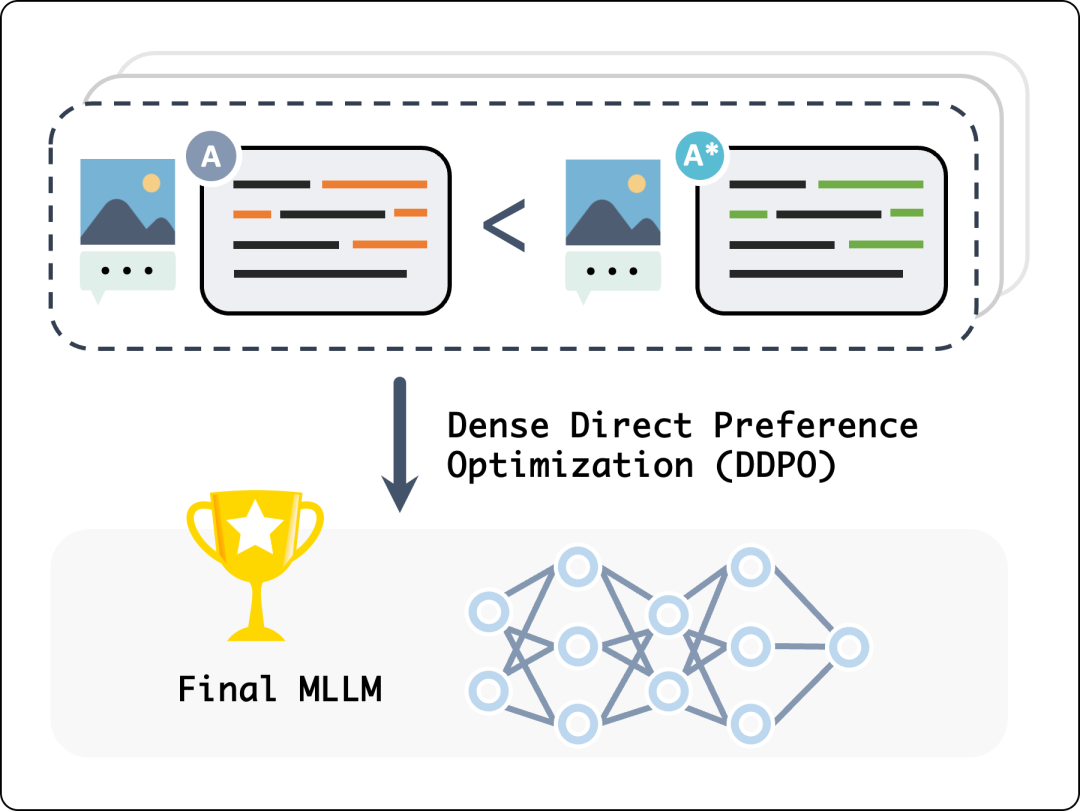
稠密监督 DDPO 算法示意图

—
文章一开头,我们就说 RLHF-V 可以降低模型“幻觉”、数据效率突出、解决“过泛化”问题的能力优于 GPT-4V……具体怎么回事呢?下面来看实验数据的可靠证明:
首先,RLHF-V 在长回复与短回复任务上模型“幻觉”均显著下降,且通用性能不受损失。
为了对模型进行“幻觉”评测,研究团队测试了模型在长回答指令和短回答指令下的“幻觉”比例情况,前者需要详细描述图片内容,后者只需简短回答图片相关问题。与此同时,为了评估模型的通用性能,研究团队还分别测试了模型在开放对话(LLaVA Bench)与图片问答(VQAv2)上的性能表现。
实验结果表明:RLHF-V 在“幻觉”评测指标上超越了已有的开源多模态大模型,且能够在显著减小“幻觉”的情况下,保持模型优秀的通用性能。
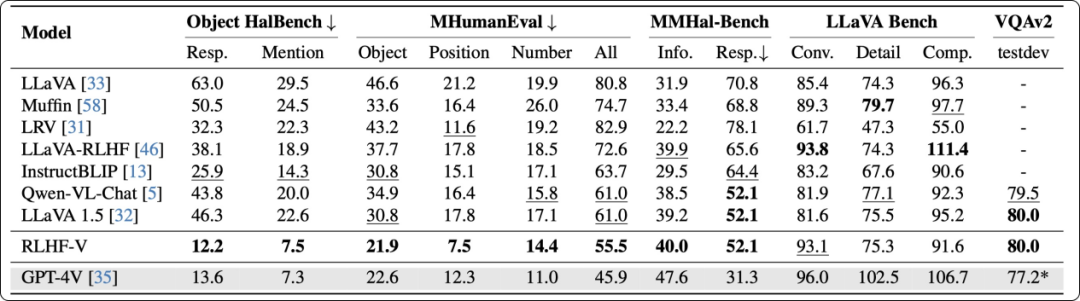
RLHF-V 与其他开源模型及 GPT-4V 在“幻觉”比例和通用性能上的对比
第二,RLHF-V 解决“过泛化” 问题的表现优于 GPT-4V。
为了评测模型在“过泛化”问题上的表现,作者选择了常见多模态指令数据中的 4 个典型的场景,以及最常出现在每个场景中的 10 个常见物体类别(COCO 物体类别),统计这些物体在所有条目中的幻觉率,以及在对应场景下的幻觉率。
实验结果表明,包括 GPT-4V 在内的现有MLLM,均有明显“过泛化”倾向,而 RLHF-V 模型“过泛化”倾向最低。
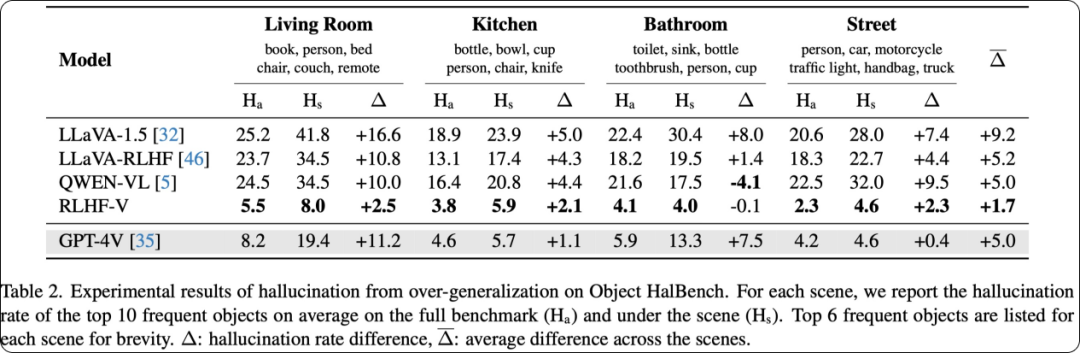
RLHF-V 与其他开源模型及 GPT-4V 在“过泛化”问题上的效果对比
第三,细粒度对齐数据在训练中具有高效性以及规模效应。
数据集规模对模型性能的影响也是非常重要的评测方向。从实验结果来看,相比基于排序的偏好数据,采用细粒度修改标注能够在 1/10 的数据规模下达到相近的模型效果。同时,随着数据量增加,模型幻觉率显著降低。
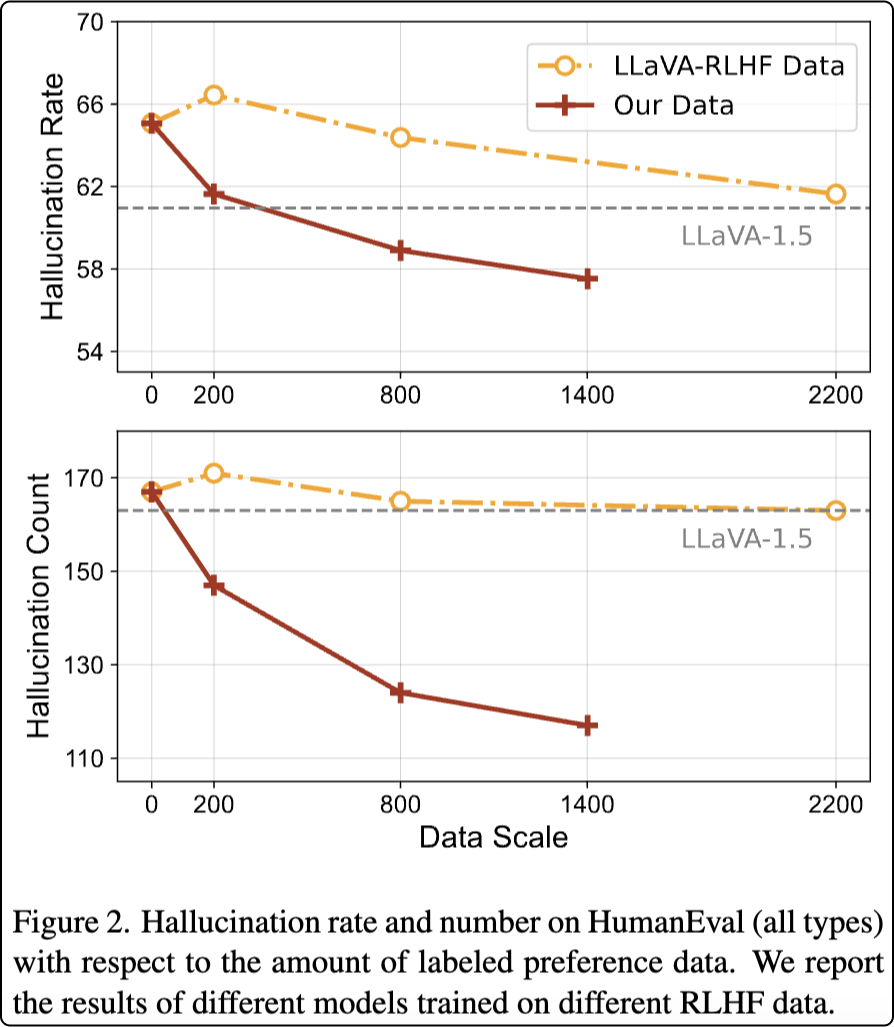
RLHF-V数据的规模效应曲线
实际上,将 RLHF-V 数据和方法用于调整其他多模态大模型,也可以有效降低模型“幻觉”的出现次数,提高模型回答可信度。在未来,研究团队也将继续提高数据规模和多样性,提升模型性能,助力开源多模态大模型向成熟应用的转变。
文章来自于微信公众号 “OpenBMB开源社区”


