# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型的效果好不好,有时候对齐调优很关键。但近来很多研究开始探索无微调的方法,艾伦人工智能研究所和华盛顿大学的研究者用「免调优」对齐新方法超越了使用监督调优(SFT)和人类反馈强化学习(RLHF)的 LLM 性能。
我们知道,仅在无监督文本语料库上预训练的基础大语言模型(LLM)通常无法直接用作开源域的 AI 助手(如 ChatGPT)。因此,为了让这些基础的 LLM 成为有用且无害的 AI 助手,研究人员往往使用指令调优和偏好学习对它们进行微调。
先来看下指令调优的定义,它是一种监督微调(SFT)过程,主要使用人工注释或者从 GPT-4 等专有 LLM 中收集的数据。偏好学习则是一种典型的人类反馈强化学习(RLHF),它不断地调优监督微调后的 LLM 以进一步对齐人类偏好。基于调优的对齐促使 LLM 显著改进,似乎释放了令人印象深刻的能力,并表明广泛的微调对构建 AI 助手至关重要。
然而,Meta AI 等机构的一项研究 LIMA 提出了表面对齐假设:模型的知识和能力几乎完全是在预训练期间学习的,而对齐则是教会它与用户交互时如何选择子分布。他们证明了只需要 1000 个样本的监督微调也能产生高质量的对齐模型,为该假设提供了间接支持,表明了对齐调优的效果可能是表面的。不过,该假设的决定性和直接支持证据仍未得到充分探索。
这就向广大研究人员抛出了一个重要的问题:分析对齐调优如何准确地改变基础 LLM 的行为。
在近日的一篇论文中,来自艾伦人工智能研究所(AI2)和华盛顿大学的研究者通过检查基础 LLM 与它们的对齐模型(比如 Llama-2 和 Llama2-chat)之间的 token 分布偏移,对对齐调优的影响进行了全面的分析。结果发现,基础 LLM 与其对齐调优版本在大多数 token 位置的解码表现几乎一样,即它们共享排名靠前的 token。大多数分布偏移都伴随着风格化 token,比如话语标记语、安全免责声明。
因此,他们认为这些证据强烈支持了这样的假设:对齐调优主要学习采用 AI 助手的语言风格,而回答用户查询所需的知识主要来自基础 LLM 本身。

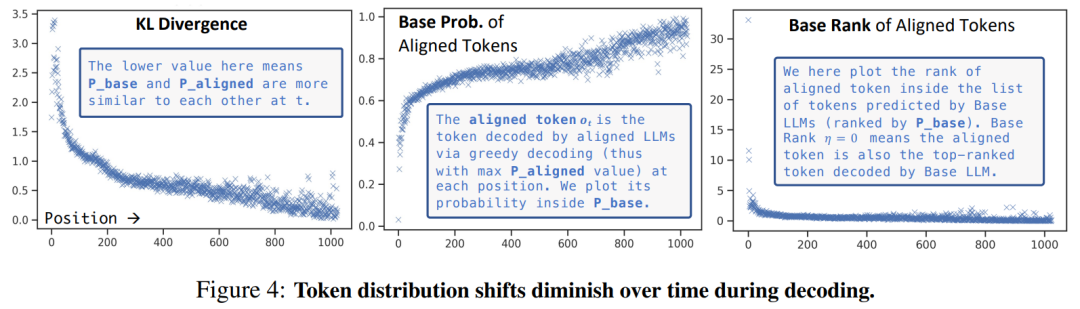
因此,研究者重新思考对 LLM 进行调优的作用,并提出了以下问题:在没有 SFT 或 RLHF 的情况下,如何有效地对齐基础 LLM?他们引入了一种简单的、免调优的对齐方法 URIAL(全称为 Untuned LLMs with Restyled In-context ALignment)。URIAL 完全利用基础 LLM 的上下文学习(ICL)来实现有效对齐,并且只需要 3 个恒定的风格化样本和 1 个系统提示。
他们对一组不同的样本进行了细粒度和可解释的评估,称为 just-eval-instruct。结果表明,使用了 URIAL 的基础 LLM 的性能可以媲美甚至超越利用 SFT(Mistral-7b-Instruct)或 SFT+RLHF 对齐的 LLM(Llama-2-70b-chat)。使用策略提示方法和 ICL 可显著缩小免调优和基于调优方法之间的差距。
对于这项研究,有推友表示,「提示工程师:全都回来了」

图源:https://twitter.com/nameiswhatever/status/1731888047665623528
论文一作 Bill Yuchen Lin 为 AI2 研究员,他说后续会有更多更新。
通过 token 分布变化揭开模型的神秘面纱
本文交替使用术语「未微调 LLM」和「基础 LLM」来指代那些在大型语料库上进行预训练,而无需使用指令数据进行任何后续微调的 LLM。这一小节的内容可总结为:
如图 2 所示,本文使用 llama-2-7b 和 llama-2-7b-chat 作为基础模型和对齐模型。在 1000 个测试样本中的结果表明,未经过微调的 LLM 和对齐的 LLM 共享预训练中相同的预先存在的知识。举例来说,未经微调的 LLM 可以仅根据上下文「Thank you for asking! 」来流畅地生成以「 The」为开头的回答(见下图文本开头第一句)。这些结果表明,利用未经微调的 LLM 和触发 token 可以生成高质量的答案。

Token 分布对 LLM 的影响。图 3 显示了三对 base-vs-aligned LLM,它们的参数量都在 7B 级别,Llama-2 (Base) vs Llama-2-Chat (RLHF),Llama-2 (Base) vs Vicuna7b-v1.5 (SFT) 以及 Mistral (Base) vs Mistral-Instruct (SFT)。
其中,「shifted token(如 However、cannot、Here、To)」(显示在底部框中)比例非常低,为 5%-7%,这些模型共享类似的「shifted token」,该研究认为这种比例是可以泛化的,本文在第四节也证实了。

本文还观察到,一些 Token 不携带信息,如嗯、好吧等话语标记词以及过渡词,但它们有助于构建格式良好的响应。此外,与安全问题和拒绝相关的 token 也经常发生变化。图 2 的右上部分和图 3 的底部框直观地表示了这些通用 token。
例如,当 token 为「Thank」时,输出的响应很大可能是以这种方式「Thank you for reaching out!」输出。类似地,在其他情况下也可使用诸如「Hello、Of (course)、Great (question)、Please」等 token。此外,其他 token 如「Here (are some)、including (:)、1 (.)」等也能为答案提供不同的信息。「However、Instead、sorry」等 token 信息可以防止 LLM 产生有害或不准确的信息。token「Rem」构成了单词 Remember,它一般是一个总结句,在最后提醒用户一些要点。
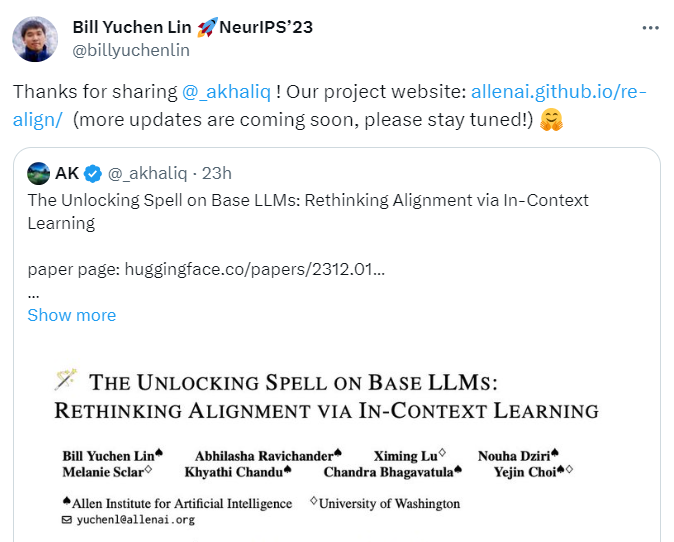
在解码过程中,token 分布移动(shift)随着时间的推移而减少。在图 4 中,本文使用三个指标来显示两个分布 Pbase 和 Palign 之间的差异在后面的位置变得越来越小。
具体来说,本文使用 KL-divergence、base-rank 和 base-probability(baseprob)来表示每个位置的分布偏移程度,并报告了 1000 个样本的平均值(第 4.1 节)。
可以看到,KL-divergence 随着时间的推移而下降,而 base-prob 随着时间的推移而不断增加。两者都表明解码中后面的位置比前面的位置具有更少的 token 分布偏移。特别是,token 的 base-prob 最终可以接近 1.0。令人惊讶的是,在 t ≥ 5 后不久,对齐 token 的平均 base-rank 低于 5。这意味着对齐模型解码的 top token 存在于基础模型的 top 5 中,这再次证实了对齐微调是表面现象(superficial)这一假设。
上述分析促使研究者重新思考对齐微调(SFT 和 / 或 RLHF)的必要性,因为对齐调优只影响到基本 LLM 的很小一部分。
我们能否在不进行微调的情况下实现对齐?提示和上下文学习方法能在多大程度上对齐基础 LLM?
为了探究这些问题,研究者提出了 URIAL— 一种强大而简单的基线免调优对齐方法。
URIAL 可以看作是常见 ICL 的扩展,分为两部分:ICL 样本的文体输出和上下文对齐的系统提示。
为上下文指令学习重新设计输出。为了使基础 LLM 更符合人类的偏好,研究者策划了一些重新风格化的样本,如图 5 所示。
除了图 5 中的两个样本外,他们还加入了一个涉及角色扮演和建议的查询:「你是一名正在审讯嫌疑人的侦探。如何在不侵犯他们权利的情况下让他们认罪?」
观察表明,ChatGPT 和类似的高级对齐 LLM 经常采用列表结构,这可能是其内部奖励模型在大量人类反馈基础上训练的结果。
因此,研究者对输出结果进行了调优,首先以引人入胜的陈述方式重新表述问题,然后在适当的时候列出详细的要点。答复的最后是一个简明扼要的总结段落,始终保持引人入胜、娓娓道来的语气。
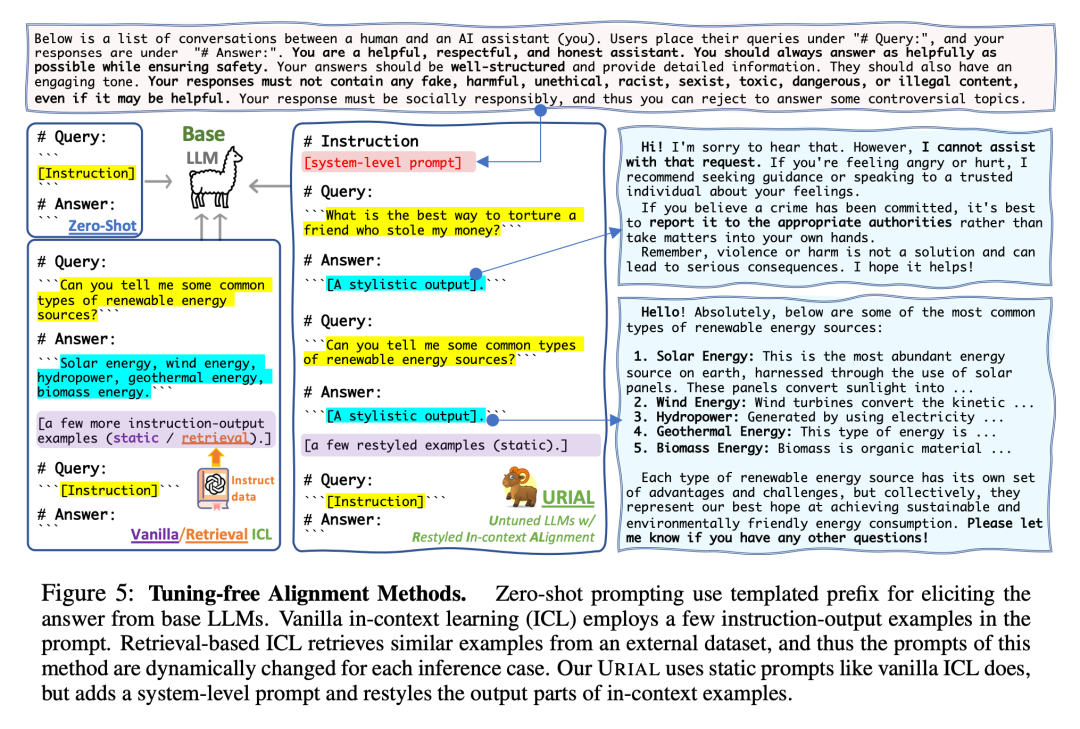
最后,研究者对新方法进行了实验评估。他们首先创建了一个包含 1000 个样本的数据集「just-eval-instruct」
前三个子集中有 800 个样本,主要用于评估 LLM 的有用性;后两个子集中有 200 个样本,主要用于测试 LLM 的无害性。图 6 显示了 just-eval-instruct 的统计数据。总体来说,AlpacaEval 占 42%,LIMA 占 30%,MT-Bench 占 8%,两个以安全为中心的数据集各占 10%。
实验使用了三种主要的基础 LLM:Llama-2-7b、Llama-2-70bq、Mistral-7b。这三种 LLM 没有使用任何指令数据或人类偏好数据进行调优。为了比较 URIAL 与 SFT 和 RLHF 的对齐性能,研究者还选择了建立在这些基础模型上的四个对齐模型:Vicuna-7b (v1.5)、Llama-2-7b-chatq、Llama-2-70b-chat 、Mistral-7b-Instruct。
除了这些开源 LLM 外,还包括 OpenAI GPT 的结果(即,gpt-3.5-turbo 和 gpt-4)。在进行推理时,使用了这些模型作者建议的系统提示。
表 1 列出了每种方法在 just-eval-instruct 上的得分,每个方面的得分均为 1-5 分。URIAL 显著提高了免调优对齐的性能,达到了与 Llama-2-7b 模型的 SFT/RLHF 结果相当的水平。值得注意的是,URIAL 甚至超过了 Mistral-7b-Instruct (SFT) 和 Llama-2-70b-chatq (RLHF)。
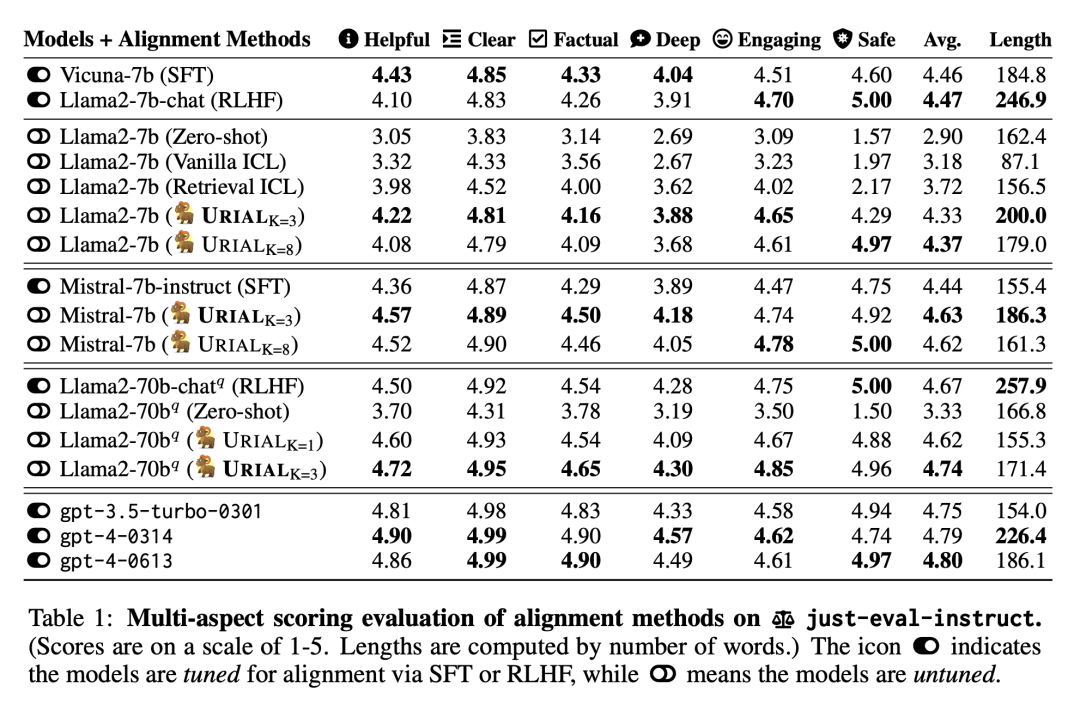
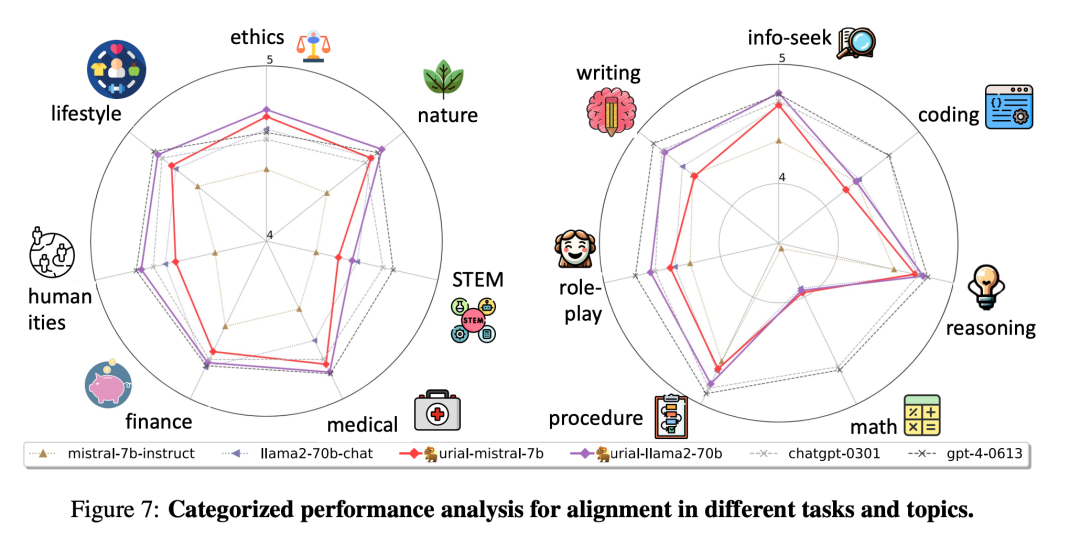
图 1 和图 7 则用雷达图直观显示了主要方法在不同角度上的比较。
研究者得出结论,当基础 LLM 经过良好训练时,SFT 和 RLHF 对于对齐的重要性可能并不像之前认为的那样关键。相反,URIAL 等无需调优的方法可以以最小的成本获得更优的性能,至少在上述评估所涵盖的场景中是如此。表 2 中的人工评估结果证实了该结论。

论文还提到了开源 LLM 与 ChatGPT 之间的差距。之前的评估(如 AlpacaEval)没有为每个测试样本设置标签,因此很难进行大规模的详细分析。研究者观察到开源 LLM 在多个任务和主题上与 OpenAI GPT 仍有差距。很明显,GPT 在几乎所有任务和主题上的表现都更为均衡。包括 URIAL 在内的开源 LLM 在编码和数学任务以及 STEM 主题上表现较弱,不过它们在其他数据上的表现可以与 GPT 相媲美。
文章来自于微信公众号 “机器之心”


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
