
“最强开源模型”被打假,CEO下场致歉,英伟达科学家:现有测试基准已经不靠谱了
“最强开源模型”被打假,CEO下场致歉,英伟达科学家:现有测试基准已经不靠谱了小型创业团队打造的“最强开源模型”,发布才一周就被质疑造假——
来自主题: AI技术研报
10583 点击 2024-09-13 21:15
 搜索
搜索
小型创业团队打造的“最强开源模型”,发布才一周就被质疑造假——
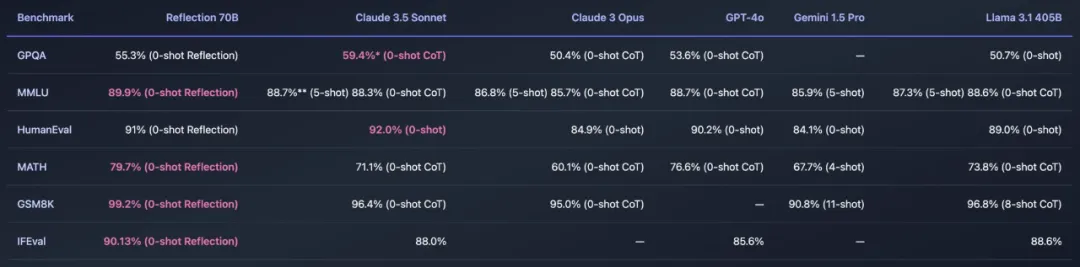
最近,开源大模型社区再次「热闹」了起来,主角是 AI 写作初创公司 HyperWrite 开发的新模型 Reflection 70B。
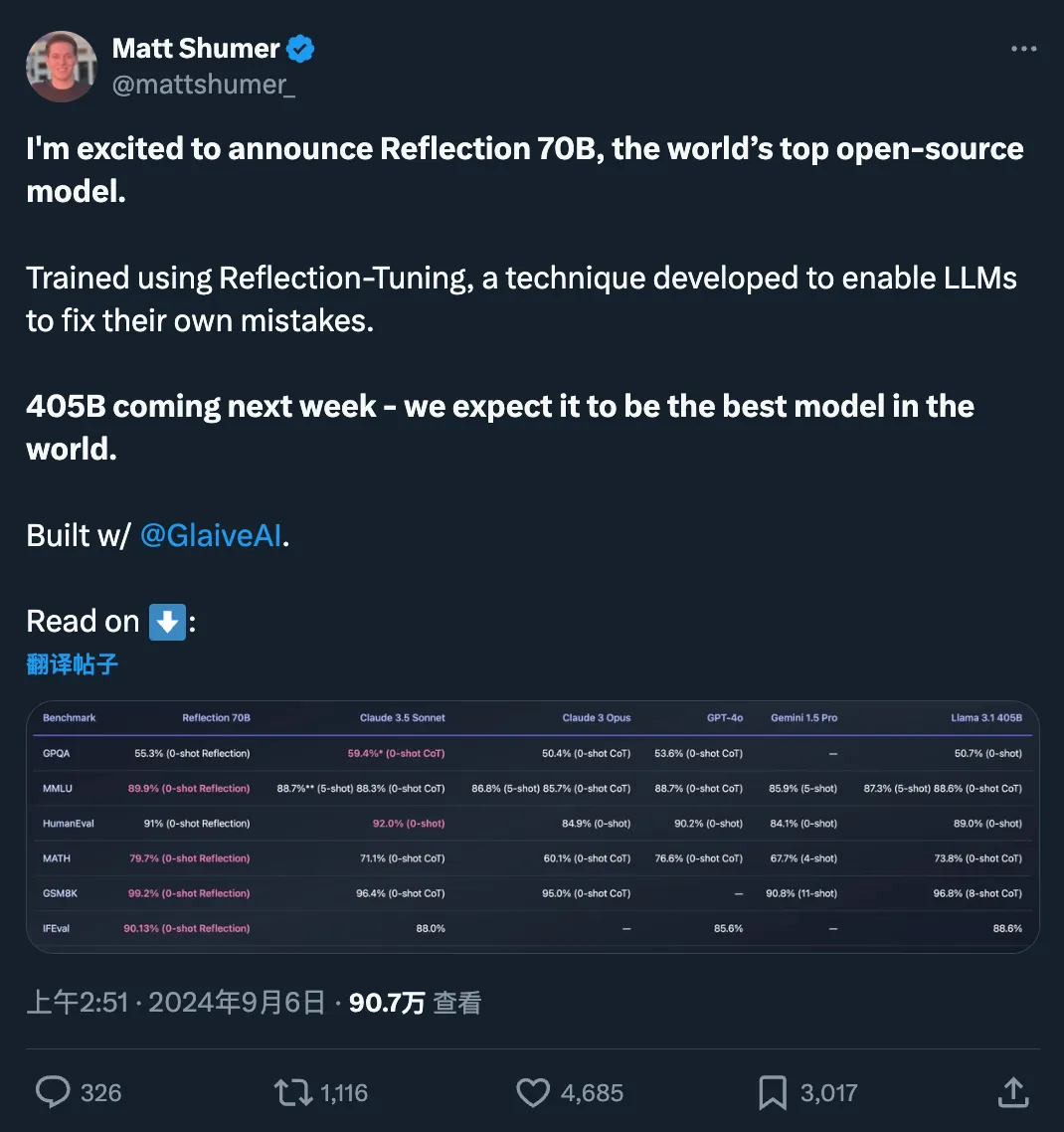
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。
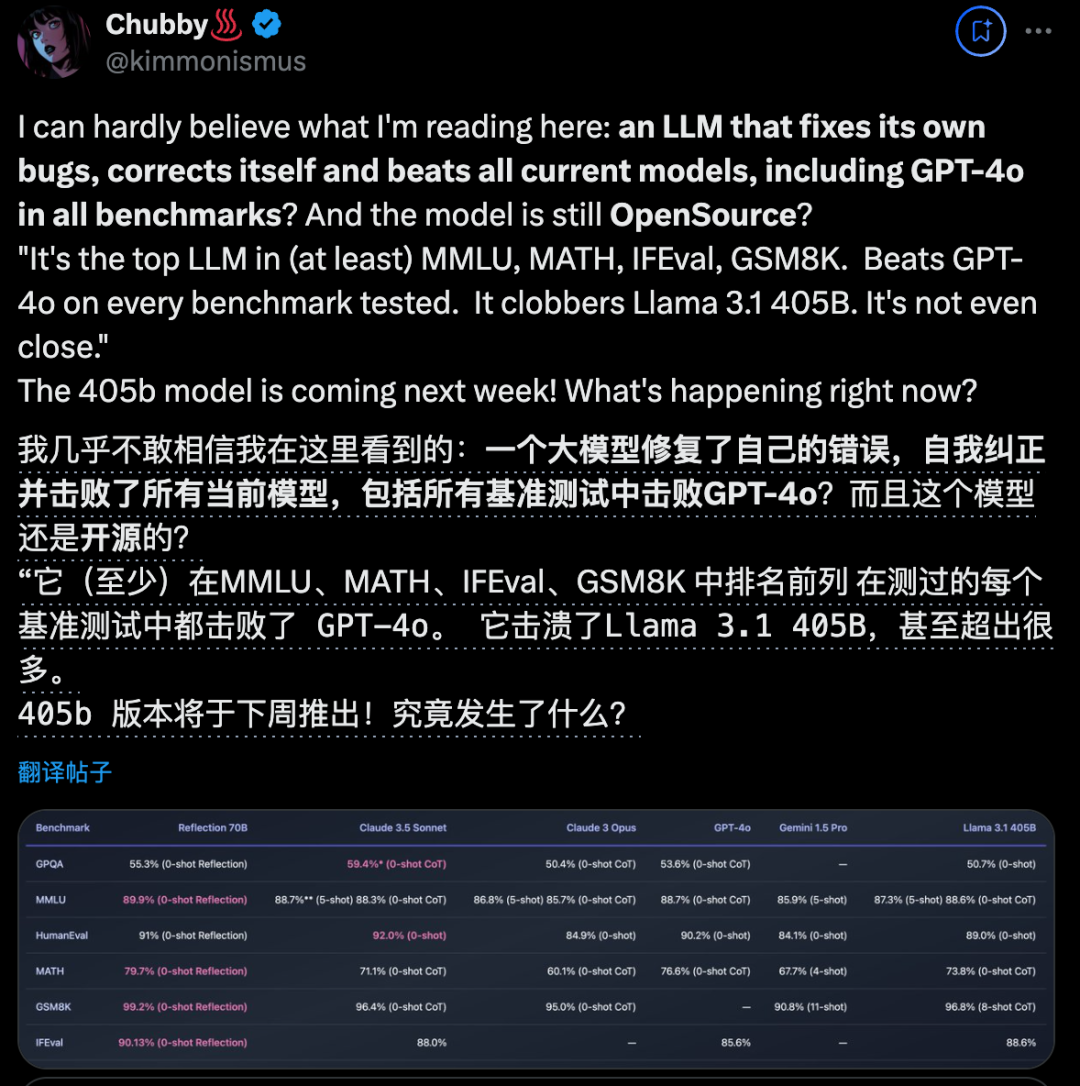
开源大模型王座突然易主,居然来自一家小创业团队,瞬间引爆业界。新模型名为Reflection 70B,使用一种全新训练技术,让AI学会在推理过程中纠正自己的错误和幻觉。

1 月 24 日,Nature Machine Intelligence 杂志在《Anniversary AI reflections》(周年人工智能反思)专题中,再次联系并采访了近期在期刊发表评论和观点文章的作者,请他们从各自所在领域中举例说明人工智能如何改变科学过程。