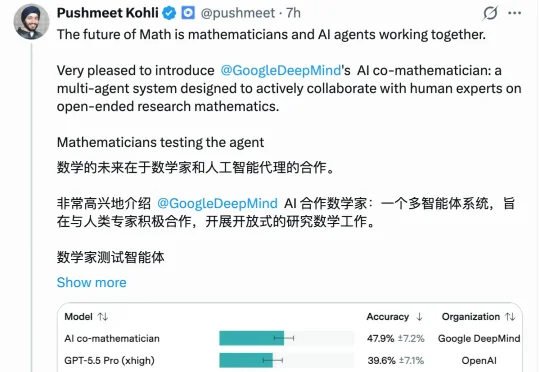
智象未来超两千亿参数图像大模型HiDream-O1-Image-Pro发布,融资持续提速
智象未来超两千亿参数图像大模型HiDream-O1-Image-Pro发布,融资持续提速智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。
来自主题: AI资讯
8971 点击 2026-05-25 09:49