
沉寂两年后,Ilya创办的SSI获英伟达重注,投资额被曝达50亿美元
沉寂两年后,Ilya创办的SSI获英伟达重注,投资额被曝达50亿美元沉寂两年之后,OpenAI 前首席科学家 Ilya Sutskever 创办的初创公司 Safe Superintelligence,终于传出了一个足够重磅的新消息。
来自主题: AI资讯
7399 点击 2026-07-28 12:34
 搜索
搜索
沉寂两年之后,OpenAI 前首席科学家 Ilya Sutskever 创办的初创公司 Safe Superintelligence,终于传出了一个足够重磅的新消息。

刚刚,OpenAI前首席科学家Ilya Sutskever的创企Safe Superintelligence(SSI)宣布和英伟达建立长期战略合作伙伴关系。英伟达将大量投资SSI,使其算力规模未来12个月内增长10倍。
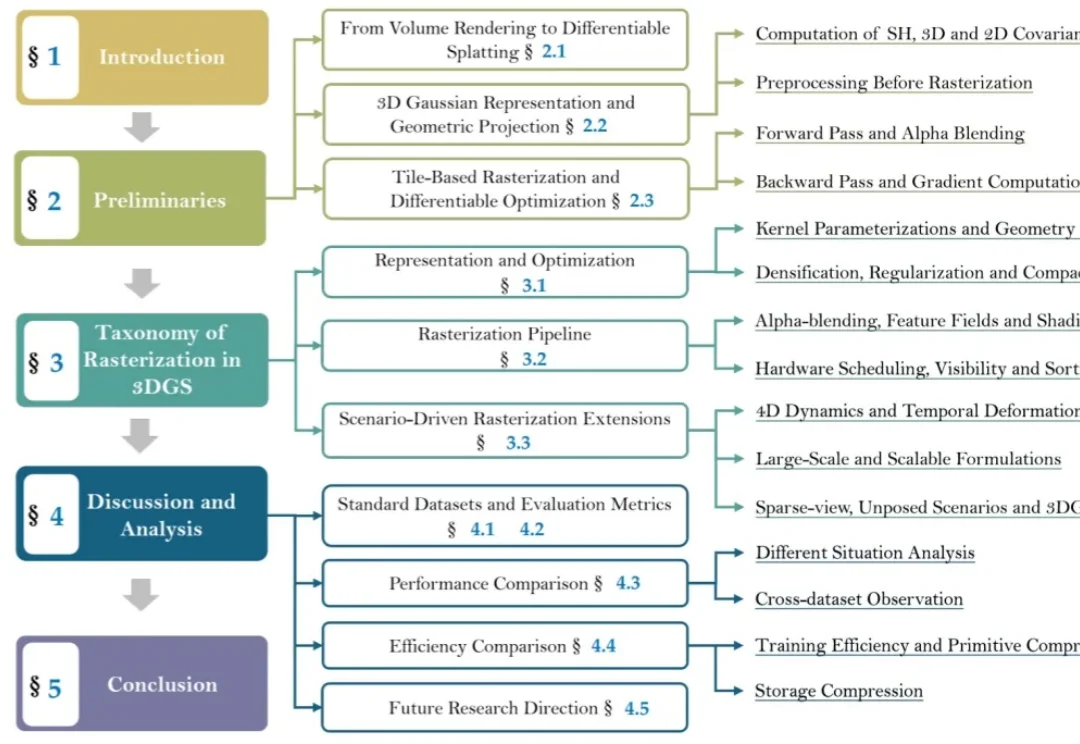
过去三年,3D Gaussian Splatting(3DGS)几乎成为实时3D场景重建与新视角合成的“默认答案”。
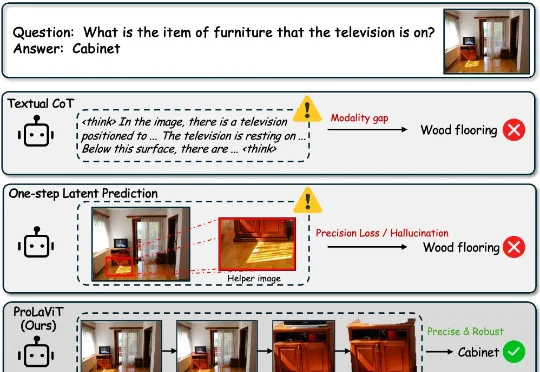
针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。

扩散语言模型(DLM)正逐渐成为自回归(Autoregressive, AR)语言模型之外一种新兴的建模范式。

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。

来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。
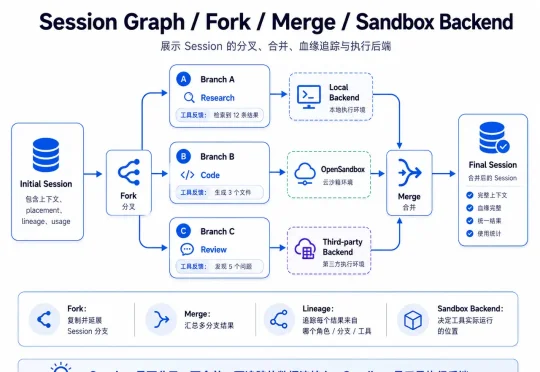
最近,一个来自清华大学与中山大学的团队(Rath Team)把他们的解法开源了,叫OpenRath:这是一个像PyTorch的多智能体、多会话运行时。它的主张是:别再围着Agent转了。真正该被当成一等公民的,是Session。
GlobalGPT 是一款很典型的 AI 套壳产品,一份订阅访问市面上几乎所有主流 AI 模型,目前全球累计用户超过 300 万,ARR 做到 1000 万美金。创始人李焕之,律师出身,2022 年开始连续创业,经历了 LegalDAO(Web3 法律社区)、LegalNow(AI 法律产品)的两次pivot后,在 2024 年初团队现金流只剩 1 个月时做出了 GlobalGPT。
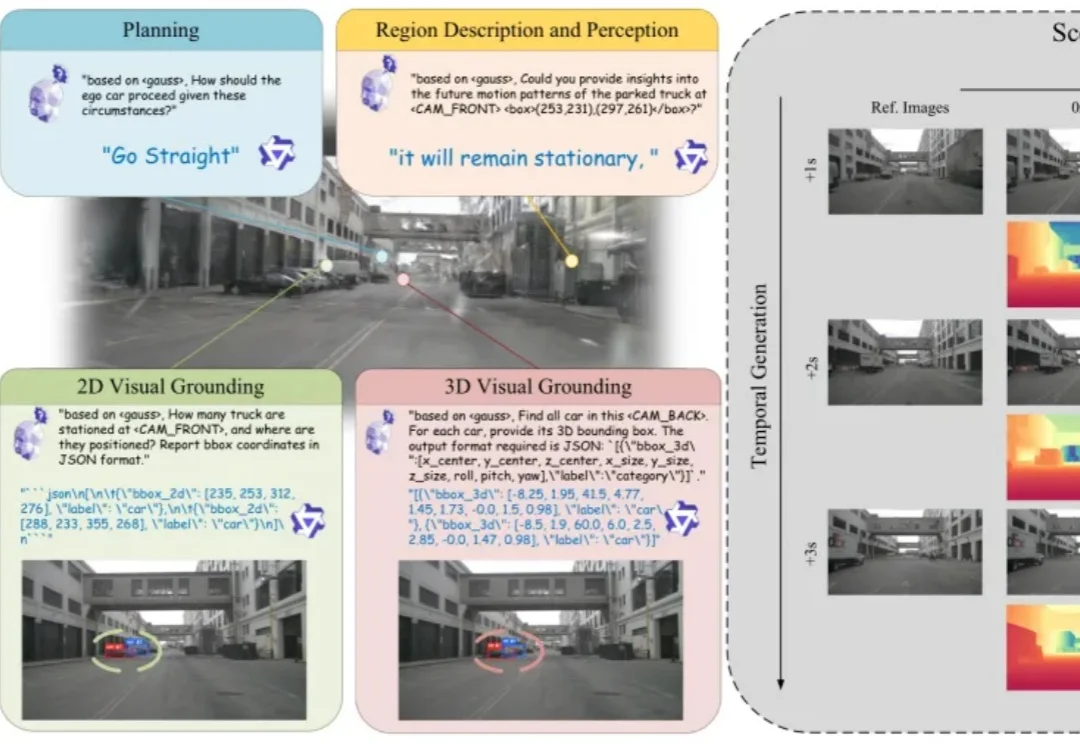
自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。