Kimi硬刚多模态满血版o1,首曝训练细节!强化学习scaling新范式诞生
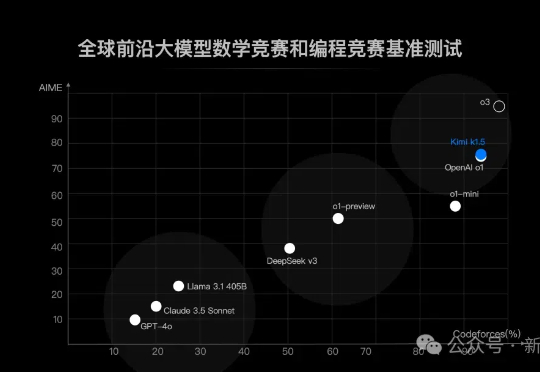
Kimi硬刚多模态满血版o1,首曝训练细节!强化学习scaling新范式诞生来了来了,月之暗面首个「满血版o1」来了!这是除OpenAI之外,首次有多模态模型在数学和代码能力上达到了满血版o1的水平。
来自主题: AI资讯
9699 点击 2025-01-21 07:44
 搜索
搜索
来了来了,月之暗面首个「满血版o1」来了!这是除OpenAI之外,首次有多模态模型在数学和代码能力上达到了满血版o1的水平。
近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……
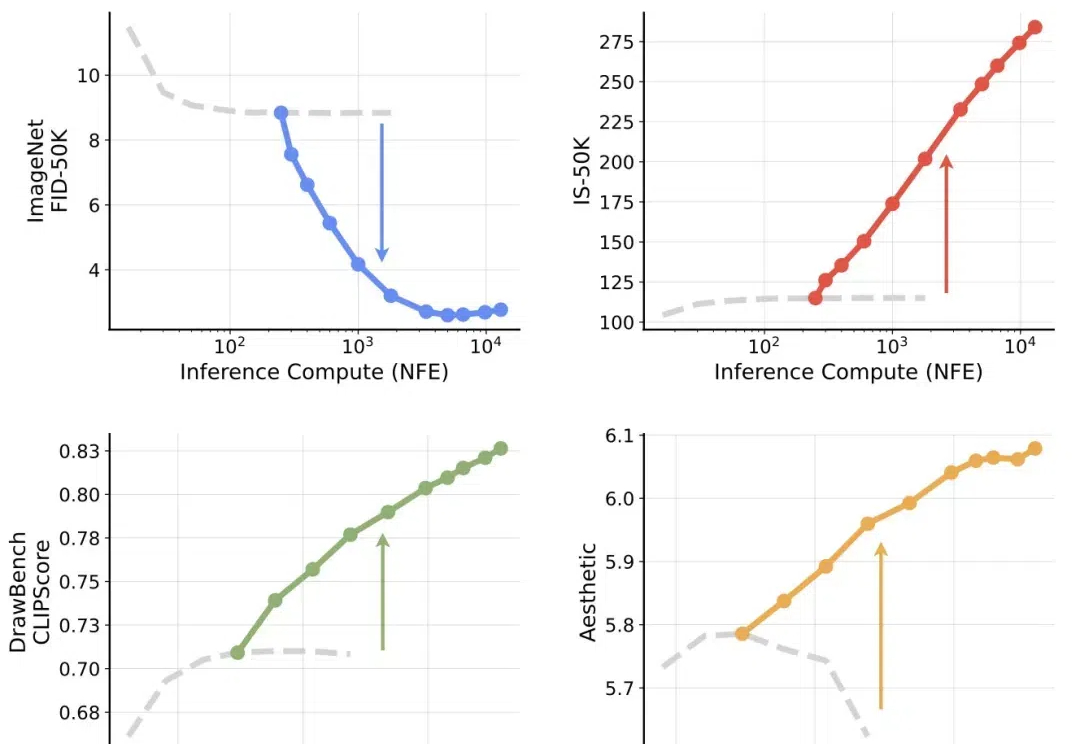
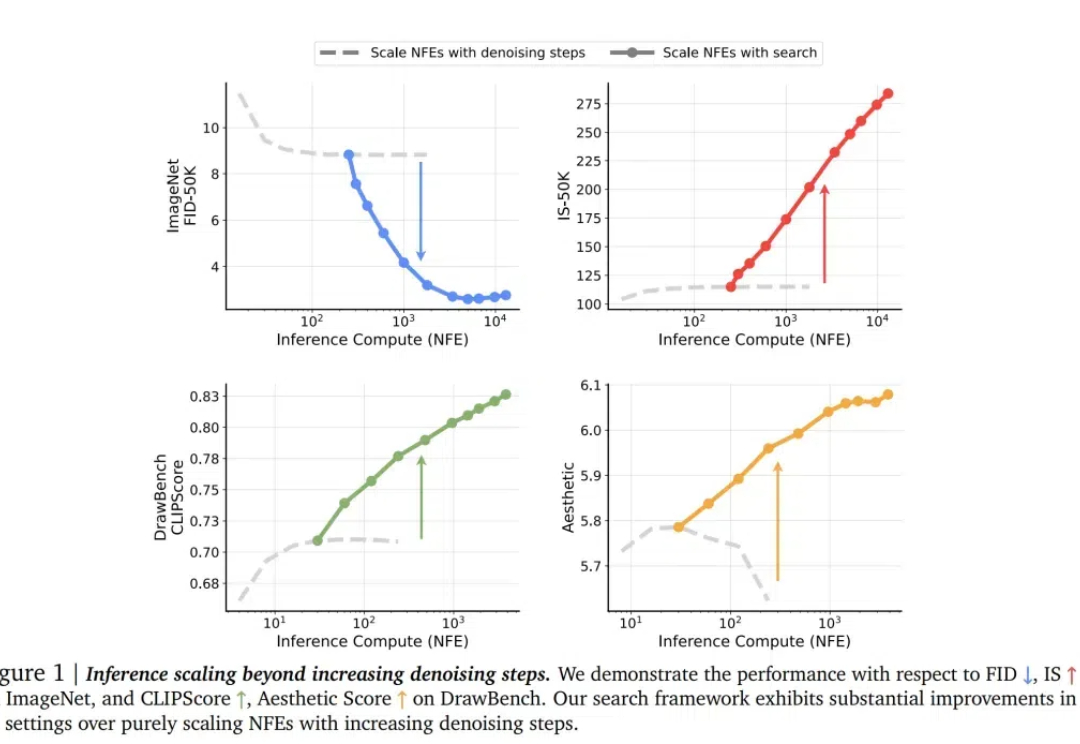
划时代的突破来了!来自NYU、MIT和谷歌的顶尖研究团队联手,为扩散模型开辟了一个全新的方向——测试时计算Scaling Law。其中,谢赛宁高徒为共同一作。

马斯克建超算速度,被中国这家公司用120天复刻了。119个集装箱,像搭积木一样拼出一座算力工厂。这不是科幻电影,而是浪潮信息交付的惊艳答卷。一个全新的AI时代,正在这里拉开序幕。
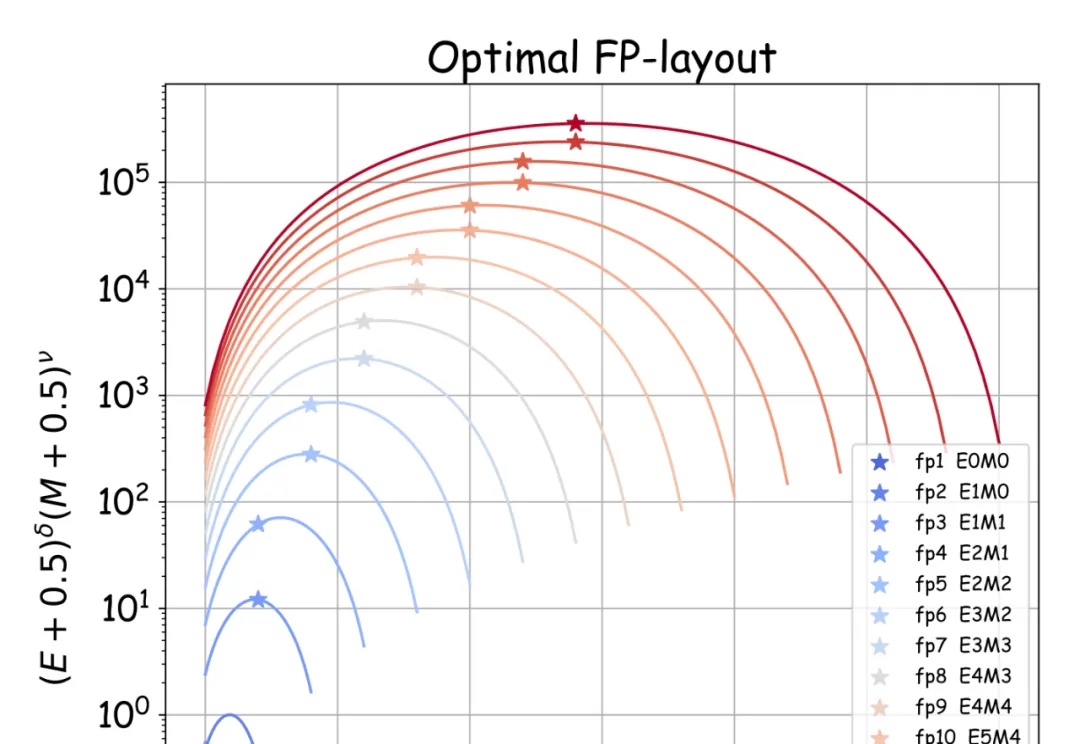
大模型低精度训练和推理是大模型领域中的重要研究方向,旨在通过降低模型精度来减少计算和存储成本,同时保持模型的性能。因为在大模型研发成本降低上的巨大价值而受到行业广泛关注 。
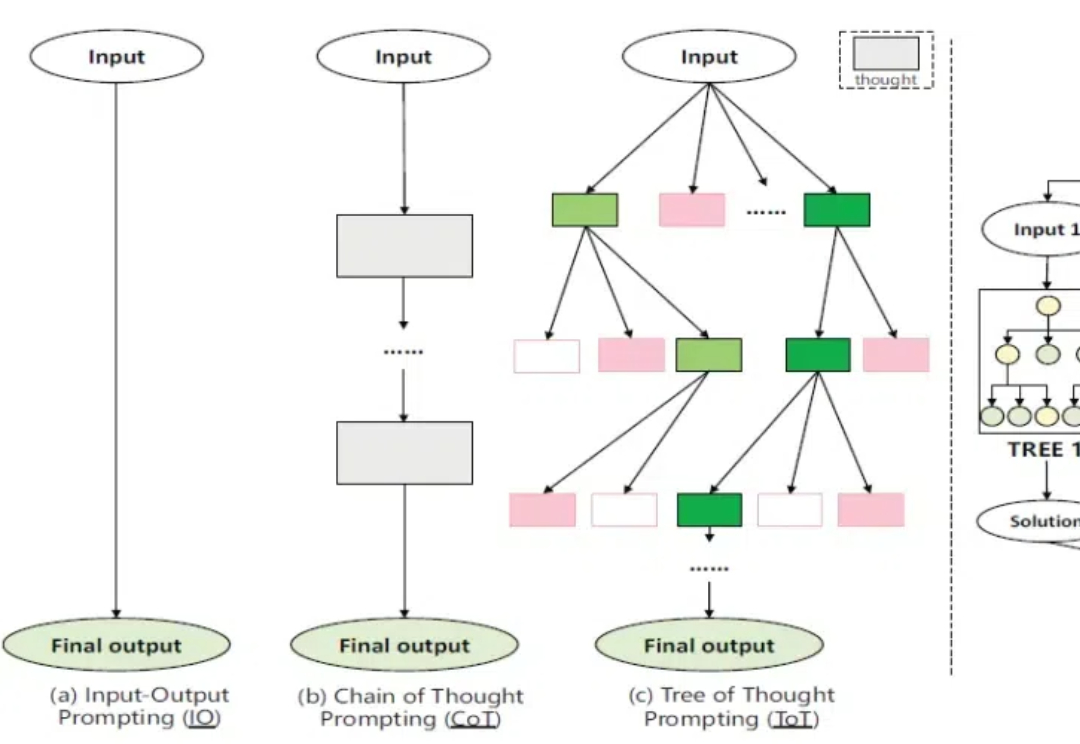
OpenAI 接连发布 o1 和 o3 模型,大模型的高阶推理能力正在迎来爆发式增强。在预训练 Scaling law “撞墙” 的背景下,探寻新的 Scaling law 成为业界关注的热点。高阶推理能力有望开启新的 Scaling law,为大模型的发展注入新的活力。
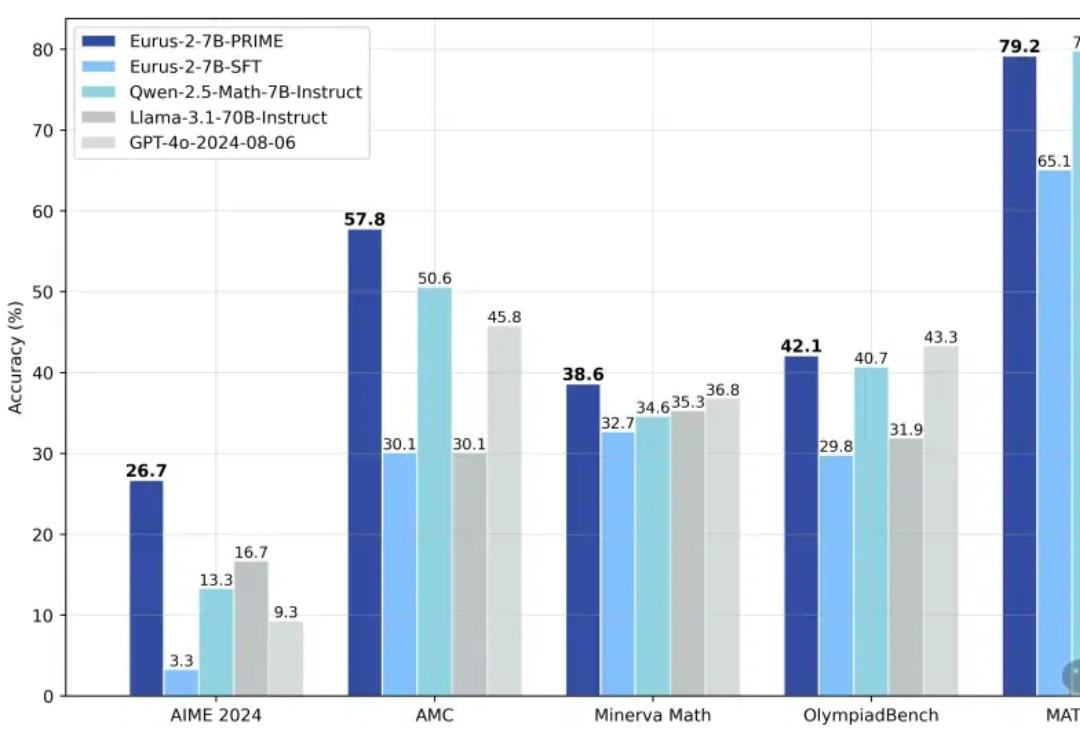
OpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。
2023 年初,Jason Wei 加入了 OpenAI,参与了 ChatGPT 的构建以及 o1 等重大项目。他的工作使思维链提示、指令微调和涌现现象等技术和概念变得广为人知。
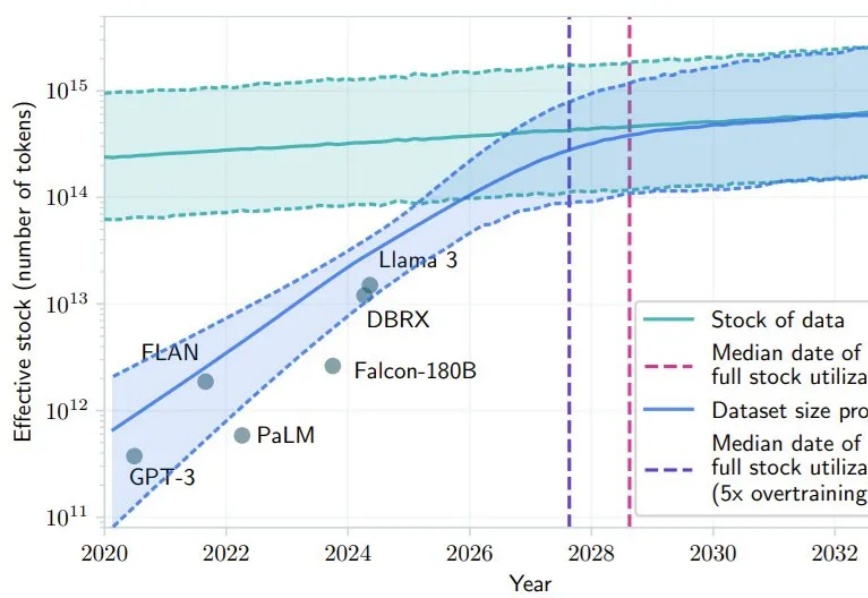
最近 AI 社区很多人都在讨论 Scaling Law 是否撞墙的问题。其中,一个支持 Scaling Law 撞墙论的理由是 AI 几乎已经快要耗尽已有的高质量数据,比如有一项研究就预计,如果 LLM 保持现在的发展势头,到 2028 年左右,已有的数据储量将被全部利用完。