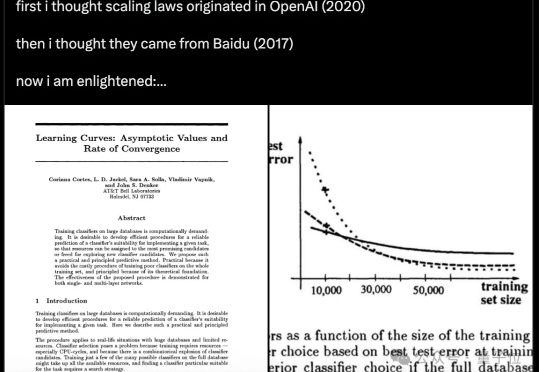
他们在1993年就提出了Scaling Law
他们在1993年就提出了Scaling Law原来,Scaling Law在32年前就被提出了! 不是2020年的OpenAI、不是2017年的百度,而是1993年的贝尔实验室。
来自主题: AI技术研报
8288 点击 2025-09-02 16:01
 搜索
搜索
原来,Scaling Law在32年前就被提出了! 不是2020年的OpenAI、不是2017年的百度,而是1993年的贝尔实验室。
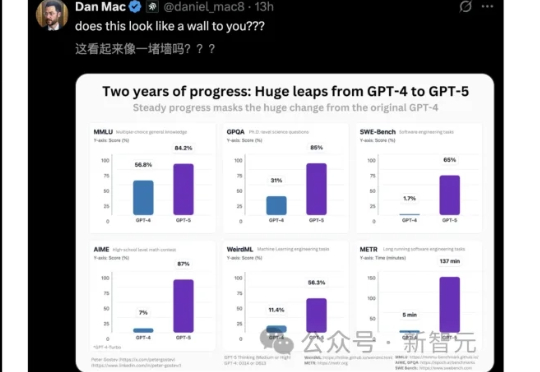
GPT-5发布半月,却被连连吐槽。如今,一张基准与GPT-4对比基准测试图,证明了Scaling Law没有撞墙。七年间,从GPT-1到GPT-5十四个花式Prompt对决,实力差一目了然。
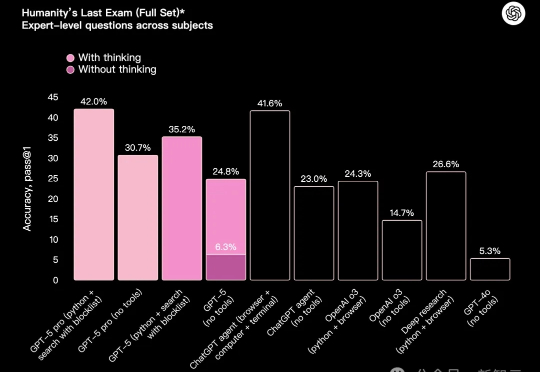
奥特曼称GPT-5「比人聪明」,但OpenAI首席运营官Lightcap澄清:这不是AGI。这只是能力过剩的冰山一角——我们仍有十年产品可建,模型越智能,融合越要精妙。GPT-5标志着从纯智商到反思能力的全面跃进。

大模型好不容易学会数r,结果换个字母就翻车了? 而且还是最新的GPT-5。 杜克大学教授Kieran Healy表示,自己让GPT-5数了数blueberry里有几个b,结果GPT-5斩钉截铁地回答3个。
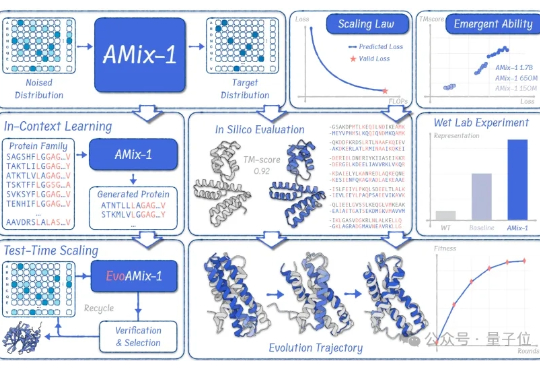
蛋白质模型的GPT时刻来了! 清华大学智能产业研究院(AIR)周浩副教授课题组联合上海人工智能实验室发布了AMix-1: 首次以Scaling Law、Emergent Ability、In-Context Learning和Test-time Scaling的系统化方法论来构建蛋白质基座模型。

OpenAI前研究员、Meta「AI梦之队员」毕书超在哥大指出:AGI就在眼前,突破需高质数据、好奇驱动探索与高效算法;Scaling Law依旧有效,规模决定智能,终身学习才是重点。
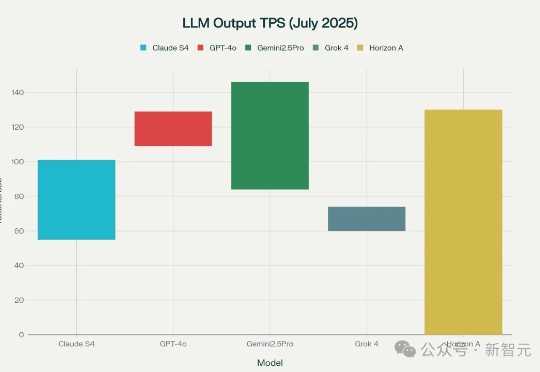
GPT-5更近了!今天,神秘模型Horizon Alpha火遍全网,编码首测性能逆天,各种三方基准实测相继放出。就在发布前夕,OpenAI核心大脑专访坦言模型还有瓶颈,但坚信Scaling Law没有尽头。

Anthropic 联合创始人 Jared Kaplan 是一名理论物理学家,研究兴趣广泛,涉及有效场论、粒子物理、宇宙学、散射振幅以及共形场论等。过去几年,他还与物理学家、计算机科学家们合作开展机器学习研究,包括神经模型以及 GPT-3 语言模型的 Scaling Law。
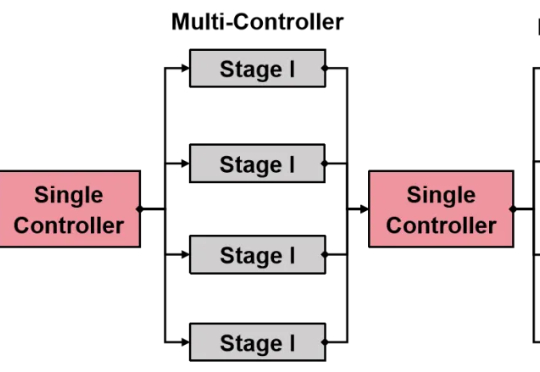
还在为强化学习(RL)框架的扩展性瓶颈和效率低下而烦恼吗?
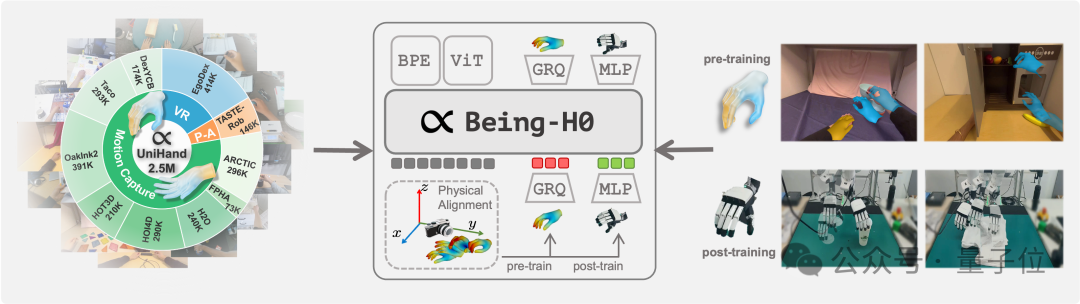
如何让机器人从看懂世界,到理解意图,再到做出动作,是具身智能领域当下最受关注的技术重点。 但真机数据的匮乏,正在使对应的视觉-语言-动作(VLA)模型面临发展瓶颈。